
[ad_1]
Clustering textual content paperwork is a typical subject in pure language processing (NLP). Primarily based on their content material, associated paperwork are to be grouped. The k-means clustering approach is a popular answer to this subject. On this article, we’ll show the best way to cluster textual content paperwork utilizing k-means utilizing Scikit Be taught.
Okay-means clustering algorithm
The k-means algorithm is a popular unsupervised studying algorithm that organizes information factors into teams based mostly on similarities. The algorithm operates by iteratively assigning every information level to its nearest cluster centroid after which recalculating the centroids based mostly on the newly fashioned clusters.
Preprocessing
Preprocessing describes the procedures used to get information prepared for machine studying or evaluation. It steadily entails reworking, reformatting, and cleansing uncooked information and vectorization right into a format applicable for extra evaluation or modeling.
Steps
- Loading or getting ready the dataset [dataset link: https://github.com/PawanKrGunjan/Natural-Language-Processing/blob/main/Sarcasm%20Detection/sarcasm.json]
- Preprocessing of textual content in case the textual content is loaded as an alternative of manually including it to the code
- Vectorizing the textual content utilizing TfidfVectorizer
- Scale back the dimension utilizing PCA
- Clustering the paperwork
- Plot the cluster utilizing matplotlib
Python3
|
|
Output:
doc cluster 16263 examine finds majority of u.s. foreign money has touc... 0 5318 an open and private e mail to hillary clinton ... 0 12994 it is not only a muslim ban, it is a lot worse 0 5395 princeton college students confront college preside... 0 24591 why getting married could assist folks drink much less 0
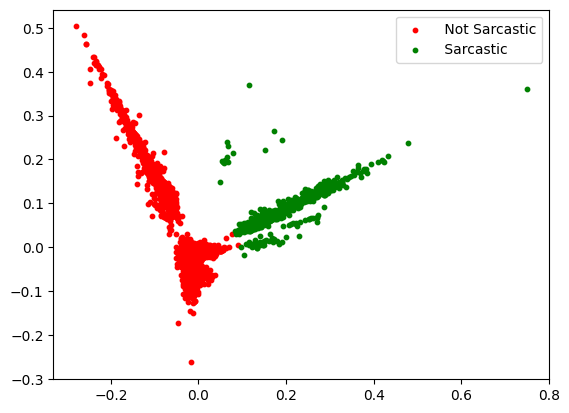
Textual content clustering utilizing KMeans
[ad_2]