
[ad_1]
Introduction
We’re thrilled to unveil the English SDK for Apache Spark, a transformative software designed to counterpoint your Spark expertise. Apache Spark™, celebrated globally with over a billion annual downloads from 208 international locations and areas, has considerably superior large-scale information analytics. With the modern software of Generative AI, our English SDK seeks to broaden this vibrant neighborhood by making Spark extra user-friendly and approachable than ever!
Motivation
GitHub Copilot has revolutionized the sphere of AI-assisted code improvement. Whereas it is highly effective, it expects the customers to grasp the generated code to commit. The reviewers want to grasp the code as effectively to assessment. This may very well be a limiting issue for its broader adoption. It additionally often struggles with context, particularly when coping with Spark tables and DataFrames. The hooked up GIF illustrates this level, with Copilot proposing a window specification and referencing a non-existent ‘dept_id’ column, which requires some experience to grasp.

As a substitute of treating AI because the copilot, lets make AI the chauffeur and we take the posh backseat? That is the place the English SDK is available in. We discover that the state-of-the-art giant language fashions know Spark rather well, due to the nice Spark neighborhood, who over the previous ten years contributed tons of open and high-quality content material like API documentation, open supply initiatives, questions and solutions, tutorials and books, and many others. Now we bake Generative AI’s professional data about Spark into the English SDK. As a substitute of getting to grasp the complicated generated code, you might get the consequence with a easy instruction in English that many perceive:
transformed_df = df.ai.rework('get 4 week shifting common gross sales by dept')
The English SDK, with its understanding of Spark tables and DataFrames, handles the complexity, returning a DataFrame straight and accurately!
Our journey started with the imaginative and prescient of utilizing English as a programming language, with Generative AI compiling these English directions into PySpark and SQL code. This modern method is designed to decrease the obstacles to programming and simplify the training curve. This imaginative and prescient is the driving pressure behind the English SDK and our purpose is to broaden the attain of Spark, making this very profitable undertaking much more profitable.
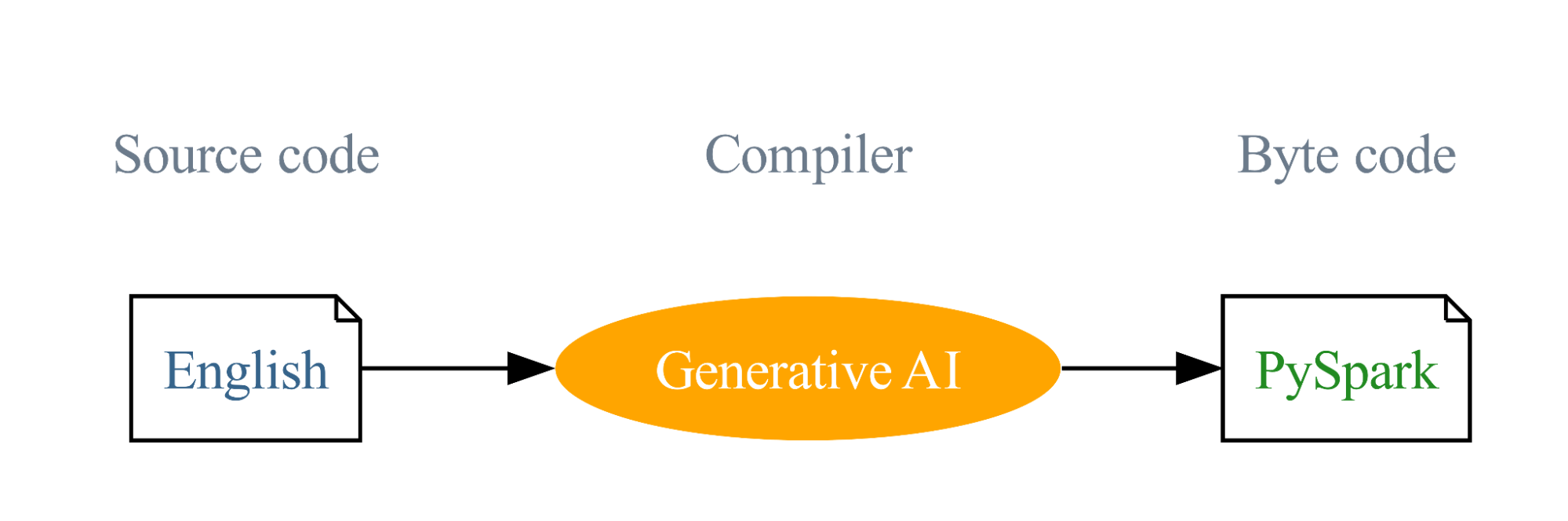
Options of the English SDK
The English SDK simplifies Spark improvement course of by providing the next key options:
- Knowledge Ingestion: The SDK can carry out an online search utilizing your supplied description, make the most of the LLM to find out probably the most acceptable consequence, after which easily incorporate this chosen internet information into Spark—all achieved in a single step.
- DataFrame Operations: The SDK gives functionalities on a given DataFrame that permit for transformation, plotting, and clarification primarily based in your English description. These options considerably improve the readability and effectivity of your code, making operations on DataFrames simple and intuitive.
- Person-Outlined Features (UDFs): The SDK helps a streamlined course of for creating UDFs. With a easy decorator, you solely want to supply a docstring, and the AI handles the code completion. This characteristic simplifies the UDF creation course of, letting you deal with perform definition whereas the AI takes care of the remaining.
- Caching: The SDK incorporates caching to spice up execution pace, make reproducible outcomes, and save price.
Examples
As an example how the English SDK can be utilized, let’s take a look at a number of examples:
Knowledge Ingestion
When you’re a knowledge scientist who must ingest 2022 USA nationwide auto gross sales, you are able to do this with simply two traces of code:
spark_ai = SparkAI()
auto_df = spark_ai.create_df("2022 USA nationwide auto gross sales by model")DataFrame Operations
Given a DataFrame df, the SDK means that you can run strategies beginning with df.ai. This contains transformations, plotting, DataFrame clarification, and so forth.
To lively partial features for PySpark DataFrame:
spark_ai.activate()To take an outline of `auto_df`:
auto_df.ai.plot()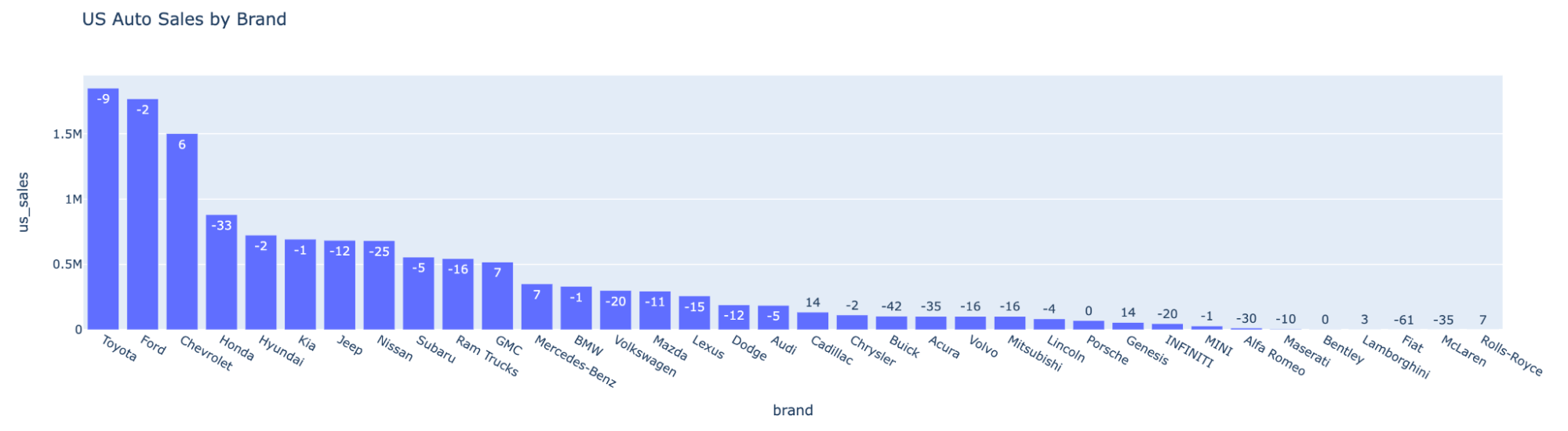
To view the market share distribution throughout automotive corporations:
auto_df.ai.plot("pie chart for US gross sales market shares, present the highest 5 manufacturers and the sum of others")
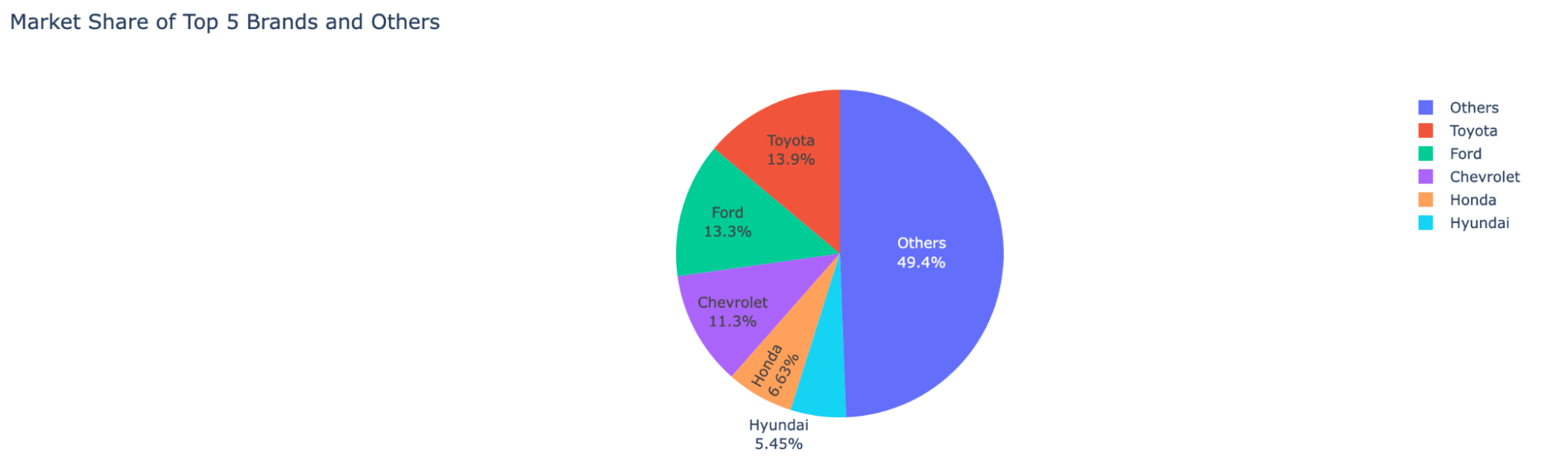
To get the model with the very best development:
auto_top_growth_df=auto_df.ai.rework("high model with the very best development")
auto_top_growth_df.present()
| model |
us_sales_2022 |
sales_change_vs_2021 |
|
Cadillac |
134726 |
14 |
To get the reason of a DataFrame:
auto_top_growth_df.ai.clarify()In abstract, this DataFrame is retrieving the model with the very best gross sales change in 2022 in comparison with 2021. It presents the outcomes sorted by gross sales change in descending order and solely returns the highest consequence.
Person-Outlined Features (UDFs)
The SDK helps a easy and neat UDF creation course of. With the @spark_ai.udf decorator, you solely must declare a perform with a docstring, and the SDK will mechanically generate the code behind the scene:
@spark_ai.udf
def convert_grades(grade_percent: float) -> str:
"""Convert the grade p.c to a letter grade utilizing commonplace cutoffs"""
...Now you need to use the UDF in SQL queries or DataFrames
SELECT student_id, convert_grades(grade_percent) FROM grade
Conclusion
The English SDK for Apache Spark is an very simple but highly effective software that may considerably improve your improvement course of. It is designed to simplify complicated duties, scale back the quantity of code required, and assist you to focus extra on deriving insights out of your information.
Whereas the English SDK is within the early phases of improvement, we’re very enthusiastic about its potential. We encourage you to discover this modern software, expertise the advantages firsthand, and take into account contributing to the undertaking. Do not simply observe the revolution—be part of it. Discover and harness the facility of the English SDK at pyspark.ai immediately. Your insights and participation will likely be invaluable in refining the English SDK and increasing the accessibility of Apache Spark.
[ad_2]