
[ad_1]
This weblog publish is co-written with Zygimantas Koncius from Etleap.
Organizations use their information to extract helpful insights and drive knowledgeable enterprise choices. With a big selection of information sources, together with transactional databases, log information, and occasion streams, you want a simple-to-use answer able to effectively ingesting and reworking giant volumes of information in actual time, guaranteeing information cleanliness, structural integrity, and information staff collaboration.
On this publish, we clarify how information groups can shortly configure low-latency information pipelines that ingest and mannequin information from quite a lot of sources, utilizing Etleap’s end-to-end pipelines with Amazon Redshift and dbt. The result’s sturdy and versatile information merchandise with excessive scalability and best-in-class question efficiency.
Introduction to Amazon Redshift
Amazon Redshift is a quick, fully-managed, self-learning, self-tuning, petabyte-scale, ANSI-SQL suitable, and safe cloud information warehouse. 1000’s of consumers use Amazon Redshift to investigate exabytes of information and run complicated analytical queries. Amazon Redshift Serverless makes it simple to run and scale analytics in seconds with out having to handle the information warehouse. It routinely provisions and scales the information warehouse capability to ship excessive efficiency for demanding and unpredictable workloads, and also you solely pay for the sources you utilize. Amazon Redshift helps you break down the information silos and permits you to run unified, self-service, real-time, and predictive analytics on all information throughout your operational databases, information lake, information warehouse, and third-party datasets with built-in governance. Amazon Redshift delivers as much as 5 instances higher worth efficiency than different cloud information warehouses out of the field and helps you retain prices predictable.
Introduction to dbt
dbt is a SQL-based transformation workflow that’s quickly rising because the go-to commonplace for information analytics groups. For simple use circumstances, dbt supplies a easy but sturdy SQL transformation growth sample. For extra superior situations, dbt fashions might be expanded utilizing macros created with the Jinja templating language and exterior dbt packages, offering extra performance.
One of many key benefits of dbt is its means to foster seamless collaboration inside and throughout information analytics groups. A powerful emphasis on model management empowers groups to trace and evaluate the historical past of adjustments made to their fashions. A complete testing framework ensures that your fashions persistently ship correct and dependable information, whereas modularity allows sooner growth by way of part reusability. Mixed, these options can enhance your information staff’s velocity, guarantee greater information high quality, and empower staff members to imagine possession.
dbt is in style for reworking huge datasets, so it’s essential that the information warehouse that runs the transformations present loads of computational capability on the lowest doable price. Amazon Redshift is able to fulfilling each of those necessities, with options comparable to concurrency scaling, RA3 nodes, and Redshift Serverless.
To benefit from dbt’s capabilities, you need to use dbt Core, an open-source command-line device that serves because the interface to utilizing dbt. By operating dbt Core together with dbt’s Amazon Redshift adapter, you may compile and run your fashions straight inside your Amazon Redshift information warehouse.
Introduction to Etleap
Etleap is an AWS Superior Know-how Associate with the AWS Knowledge & Analytics Competency and Amazon Redshift Service Prepared designation. Etleap simplifies the information pipeline constructing expertise. A cloud-native platform that seamlessly integrates with AWS infrastructure, Etleap consolidates information with out the necessity for coding. Automated difficulty detection pinpoints issues so information groups can keep centered on analytics initiatives, not information pipelines. Etleap integrates key Amazon Redshift options into its product, comparable to streaming ingestion, Redshift Serverless, and information sharing.
In Etleap, pre-load transformations are primarily used for cleansing and structuring information, whereas post-load SQL transformations allow multi-table joins and dataset aggregations. Bridging the hole between information ingestion and SQL transformations comes with a number of challenges, comparable to dependency administration, scheduling points, and monitoring the information stream. That can assist you tackle these challenges, Etleap launched end-to-end pipelines that use dbt Core fashions to mix information ingestion with modeling.
Etleap end-to-end information pipelines
The next diagram illustrates Etleap’s end-to-end pipeline structure and an instance information stream.

Etleap end-to-end information pipelines mix information ingestion with modeling within the following method: a cron schedule first triggers ingestion of information required by the fashions. As soon as all of the ingestion is full, a user-defined dbt construct is run, which performs post-load SQL transformations and aggregations on the information that has simply been ingested by ingestion pipelines.
Finish-to-end pipelines supply a number of benefits over operating dbt workflows in isolation, together with dependency administration, scheduling and latency, Amazon Redshift workload synchronization, and managed infrastructure.
Dependency administration
In a typical dbt use case, the information that dbt performs SQL transformations on is ingested by an extract, remodel, and cargo (ETL) device comparable to Etleap. Tables ingested by ETL processes in dbt tasks are often referenced as dbt sources. These supply references must be maintained both manually or utilizing customized options. That is usually a laborious and error-prone course of. Etleap eliminates these processes by routinely retaining your dbt supply record updated. Moreover, any adjustments made to the dbt mission or ingestion pipeline will likely be validated by Etleap, guaranteeing that the adjustments are suitable and received’t disrupt your dbt builds.
Scheduling and latency
Finish-to-end pipelines assist you to monitor and decrease end-to-end latency. That is achieved by utilizing a single end-to-end pipeline schedule, which eliminates the necessity for an impartial ingestion pipeline and dbt job-level schedules. When the schedule triggers the end-to-end pipeline, the ingestion processes will run. The dbt workflow will begin solely after the information for each desk used within the dbt SQL fashions is updated. This removes the necessity for extra scheduling elements exterior of Etleap, which reduces information stack complexity. It additionally ensures that every one information concerned in dbt transformations is at the very least as latest because the scheduled set off time. Consequently, information in all the ultimate tables or views will likely be updated as of the scheduled set off time.
Amazon Redshift workload synchronization
On account of pipelines and dbt builds operating on the identical schedule and triggering solely the required components of information ingestion and dbt transformations, greater workload synchronization is achieved. Which means that clients utilizing Redshift Serverless can additional decrease their compute utilization, driving their prices down additional.
Managed infrastructure
One of many challenges when utilizing dbt Core is the necessity to arrange and keep your individual infrastructure during which the dbt jobs might be run effectively and securely. As a software program as a service (SaaS) supplier, Etleap supplies extremely scalable and safe dbt Core infrastructure out of the field, so there’s no infrastructure administration required by your information groups.
Answer overview
For example how end-to-end pipelines can tackle an information analytics staff’s wants, we use an instance based mostly on Etleap’s personal buyer success dashboard.
For Etleap’s buyer success staff, it’s essential to trace adjustments within the variety of ingestion pipelines clients have. To satisfy the staff’s necessities, the information analyst must ingest the mandatory information from inside techniques into an Amazon Redshift cluster. They then must develop dbt fashions and schedule an end-to-end pipeline. This manner, Etleap’s buyer success staff has dashboard-ready information that’s persistently updated.
Ingest information from the sources
In Etleap’s case, the interior entities are saved in a MySQL database, and buyer relationships are managed by way of HubSpot. Due to this fact, the information analyst should first ingest all information from the MySQL consumer and pipeline tables in addition to the corporations entity from HubSpot into their Amazon Redshift cluster. They will obtain this by logging into Etleap and configuring ingestion pipelines by means of the UI.
Develop the dbt fashions
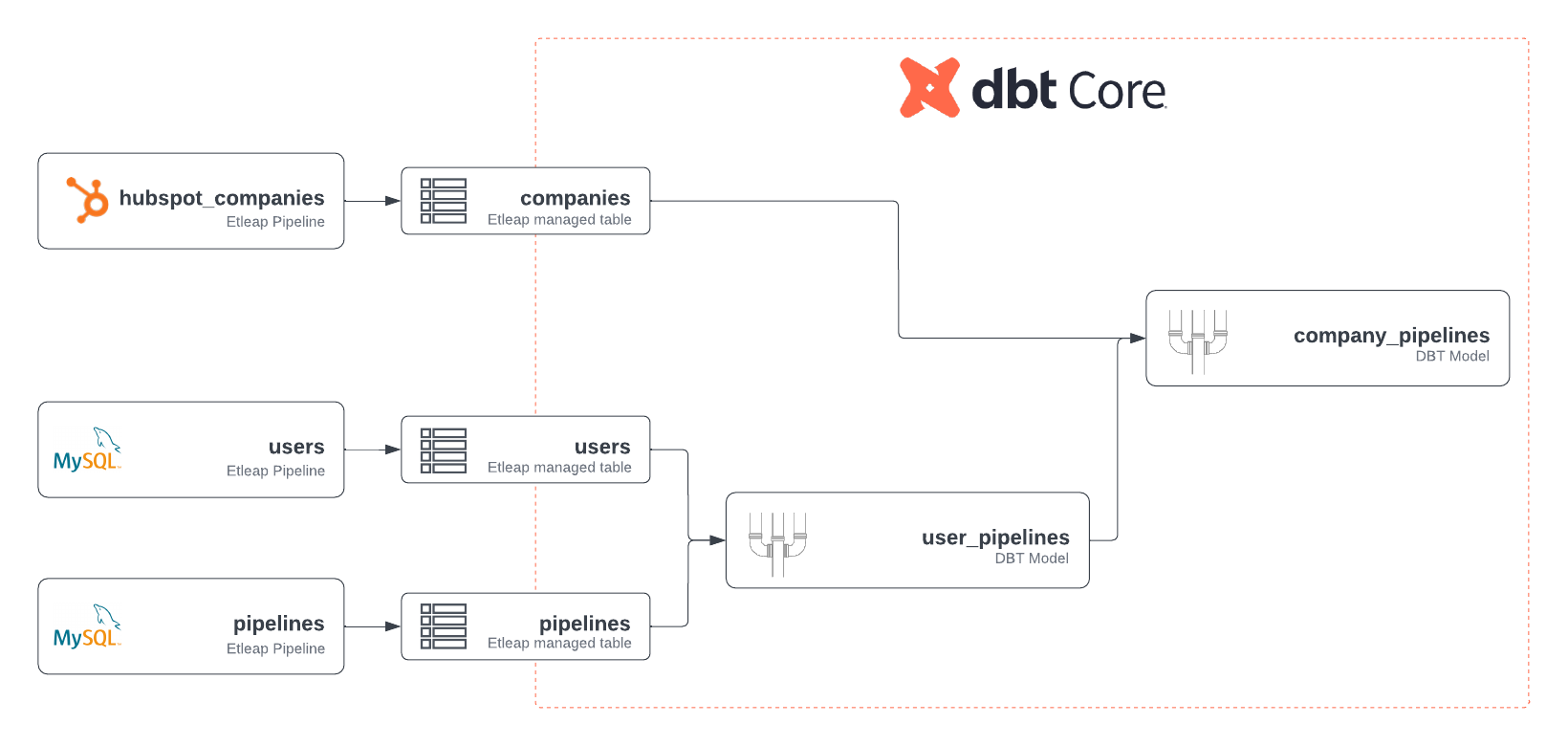
After the information has been loaded into Amazon Redshift, the information analyst can start creating dbt fashions by utilizing queries that be a part of the HubSpot information with inside entities. The primary mannequin, user_pipelines.sql, joins the customers desk with the pipelines desk based mostly on the overseas key user_id saved within the pipelines desk, as proven within the following code. Notice the usage of supply notation to reference the supply tables, which have been ingested utilizing ingestion pipelines.
The second mannequin, company_pipelines.sql, joins the HubSpot corporations desk with the user_pipelines desk, which is created by the primary dbt mannequin, based mostly on the e-mail area. Notice the utilization of ref notation to reference the primary mannequin:
After creating these fashions within the dbt mission, the information analyst may have achieved the information stream summarized within the following determine.
Take a look at the dbt workflow
Lastly, the information analyst can outline a dbt selector to pick the newly created fashions and run the dbt workflow domestically. This creates the views and tables outlined by the fashions of their Amazon Redshift cluster.
The ensuing company_pipelines desk allows the staff to trace metrics, such because the variety of pipelines created by every buyer or the variety of pipelines created on any specific day.
Schedule an end-to-end pipeline in Etleap
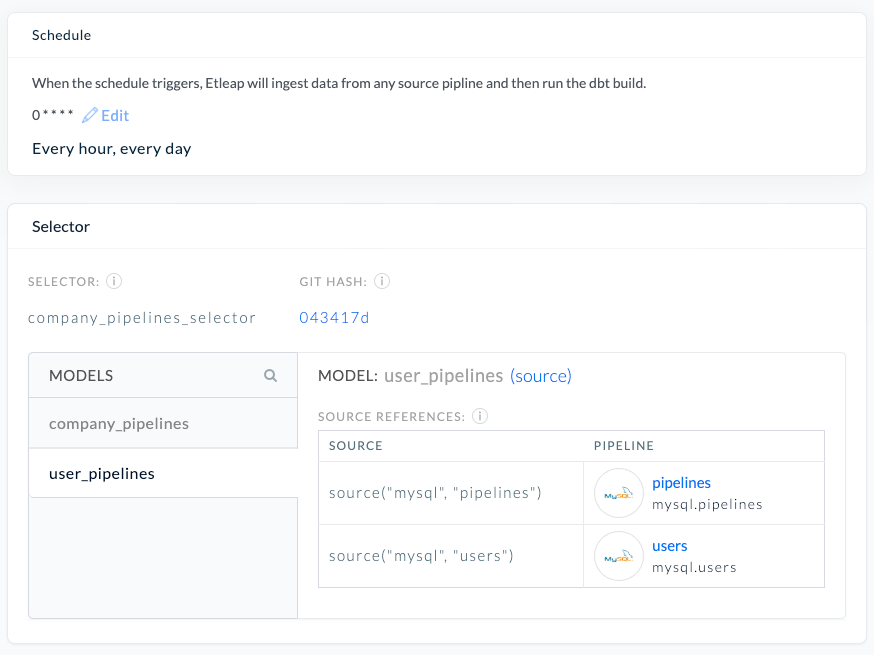
After the information analyst has developed the preliminary fashions and queries, they’ll schedule an Etleap end-to-end pipeline by selecting the selector and defining a desired cron schedule. The tip-to-end pipeline matches the sources to pipelines and takes care of operating the ingestion pipelines in addition to dbt builds on an outlined schedule, guaranteeing excessive freshness of the information.
The next screenshot of the Etleap UI reveals the configuration of an end-to-end pipeline, together with its cron schedule, which fashions are included within the dbt construct, and the mapping of inferred dbt sources to Etleap pipelines.
Abstract
On this publish, we described how Etleap’s end-to-end pipelines allow information groups to simplify their information integration and transformation workflows in addition to obtain greater information freshness. Specifically, we illustrated how information groups can use Etleap with dbt and Amazon Redshift to run their information ingestion pipelines with post-load SQL transformations with minimal effort required by the staff.
Begin utilizing Amazon Redshift or Amazon Redshift Serverless to benefit from their highly effective SQL transformations. To get began with Etleap, begin a free trial or request a tailor-made demo.
In regards to the authors
 Zygimantas Koncius is an engineer at Etleap with 3 years of expertise in creating sturdy and performant ETL software program. Along with growth work, he maintains Etleap infrastructure and supplies deep-level technical buyer assist.
Zygimantas Koncius is an engineer at Etleap with 3 years of expertise in creating sturdy and performant ETL software program. Along with growth work, he maintains Etleap infrastructure and supplies deep-level technical buyer assist.
 Sudhir Gupta is a Principal Associate Options Architect, Analytics Specialist at AWS with over 18 years of expertise in Databases and Analytics. He helps AWS companions and clients design, implement, and migrate large-scale information & analytics (D&A) workloads. As a trusted advisor to companions, he allows companions globally on AWS D&A providers, builds options/accelerators, and leads go-to-market initiatives.
Sudhir Gupta is a Principal Associate Options Architect, Analytics Specialist at AWS with over 18 years of expertise in Databases and Analytics. He helps AWS companions and clients design, implement, and migrate large-scale information & analytics (D&A) workloads. As a trusted advisor to companions, he allows companions globally on AWS D&A providers, builds options/accelerators, and leads go-to-market initiatives.
[ad_2]