
[ad_1]
Chatbots are essentially the most extensively adopted use case for leveraging the highly effective chat and reasoning capabilities of huge language fashions (LLM). The retrieval augmented era (RAG) structure is shortly turning into the trade customary for creating chatbots as a result of it combines the advantages of a data base (through a vector retailer) and generative fashions (e.g. GPT-3.5 and GPT-4) to scale back hallucinations, preserve up-to-date data, and leverage domain-specific data. Nevertheless, evaluating the standard of chatbot responses stays an unsolved drawback at the moment. With no trade requirements outlined, organizations resort to human grading (labeling) –which is time-consuming and laborious to scale.
We utilized concept to follow to assist type greatest practices for LLM automated analysis so you possibly can deploy RAG purposes to manufacturing shortly and with confidence. This weblog represents the primary in a sequence of investigations we’re working at Databricks to supply learnings on LLM analysis. All analysis on this put up was performed by Quinn Leng, Senior Software program Engineer at Databricks and creator of the Databricks Documentation AI Assistant.
Challenges with auto-evaluation in follow
Lately, the LLM group has been exploring using “LLMs as a choose” for automated analysis with many utilizing highly effective LLMs comparable to GPT-4 to do the analysis for his or her LLM outputs. The lmsys group’s analysis paper explores the feasibility and professionals/cons of utilizing numerous LLMs (GPT-4, ClaudeV1, GPT-3.5) because the choose for duties in writing, math, and world data.
Regardless of all this nice analysis, there are nonetheless many unanswered questions on find out how to apply LLM judges in follow:
- Alignment with Human Grading: Particularly for a document-Q&A chatbot, how effectively does an LLM choose’s grading replicate the precise human desire when it comes to correctness, readability and comprehensiveness of the solutions?
- Accuracy by means of Examples: What’s the effectiveness of offering a couple of grading examples to the LLM choose and the way a lot does it enhance the reliability and reusability of the LLM choose on totally different metrics?
- Applicable Grade Scales: What grading scale is advisable as a result of totally different grading scales are utilized by totally different frameworks (e.g., AzureML makes use of 0 to 100 whereas langchain makes use of binary scales)?
- Applicability Throughout Use Instances: With the identical analysis metric (e.g. correctness), to what extent can the analysis metric be reused throughout totally different use circumstances (e.g. informal chat, content material summarization, retrieval-augmented era)?
Making use of efficient auto-evaluation for RAG purposes
We explored the doable choices for the questions outlined above within the context of our personal chatbot software at Databricks. We imagine that our findings generalize and may thus assist your workforce successfully consider RAG-based chatbots at a decrease value and sooner pace:
- LLM-as-a-judge agrees with human grading on over 80% of judgments. Utilizing LLMs-as-a-judge for our document-based chatbot analysis was as efficient as human judges, matching the precise rating in over 80% of judgments and being inside a 1-score distance (utilizing a scale of 0-3) in over 95% of judgments.
- Save prices through the use of GPT-3.5 with examples. GPT-3.5 can be utilized as an LLM choose if you happen to present examples for every grading rating. Due to the context dimension restrict it’s solely sensible to make use of a low-precision grading scale. Utilizing GPT-3.5 with examples as a substitute of GPT-4 drives down the price of LLM choose by 10x and improves the pace by greater than 3x.
- Use low-precision grading scales for simpler interpretation. We discovered lower-precision grading scores like 0, 1, 2, 3 and even binary (0, 1) can largely retain precision in comparison with greater precision scales like 0 to 10.0 or 0 to 100.0, whereas making it significantly simpler to supply grading rubrics to each human annotators and LLM judges. Utilizing a decrease precision scale additionally permits consistency of grading scales amongst totally different LLM judges (e.g. between GPT-4 and claude2).
- RAG purposes require their very own benchmarks. A mannequin may need good efficiency on a printed specialised benchmark (e.g. informal chat, math, or artistic writing) however that doesn’t assure good efficiency on different duties (e.g. answering questions from a given context). Benchmarks ought to solely be used if the use case matches, i.e., a RAG software ought to solely be evaluated with a RAG benchmark.
Primarily based on our analysis, we suggest the next process when utilizing an LLM choose:
- Use a 1-5 grading scale
- Use GPT-4 as an LLM choose with no examples to grasp grading guidelines
- Swap your LLM choose to GPT-3.5 with one instance per rating
Our methodology for establishing the most effective practices
The rest of this put up will stroll by means of the sequence of experiments we performed to type these greatest practices.
Experiment Setup
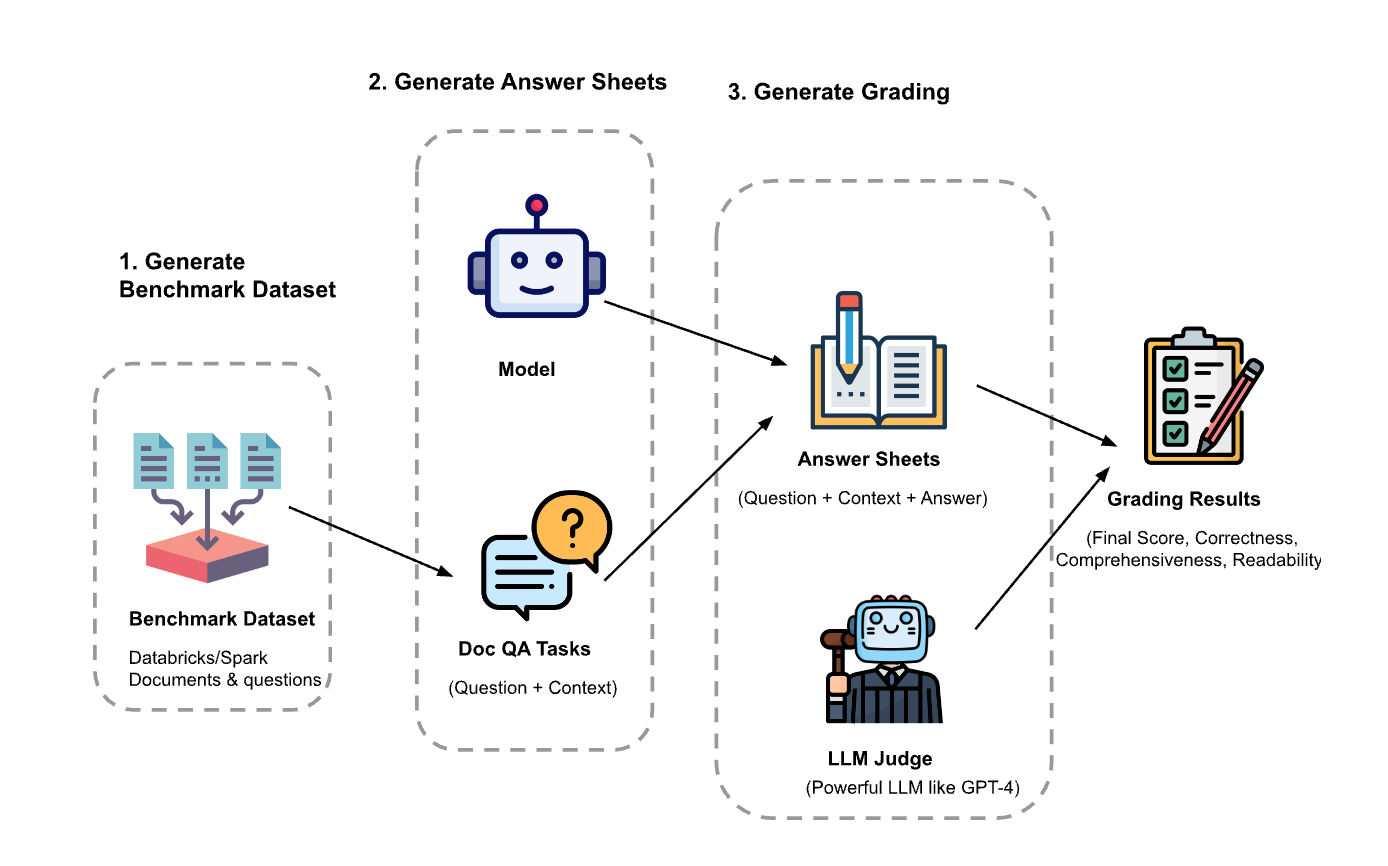
The experiment had three steps:
- Generate analysis dataset: We created a dataset from 100 questions and context from Databricks paperwork. The context represents (chunks of) paperwork which might be related to the query.

- Generate reply sheets: Utilizing the analysis dataset, we prompted totally different language fashions to generate solutions and saved the question-context-answer pairs in a dataset known as “reply sheets”. On this investigation, we used GPT-4, GPT-3.5, Claude-v1, Llama2-70b-chat, Vicuna-33b, and mpt-30b-chat.
- Generate grades: Given the reply sheets, we used numerous LLMs to generate grades and reasoning for the grades. The grades are a composite rating of Correctness (weighted: 60%), Comprehensiveness (weighted: 20%) and Readability (weighted: 20%). We selected this weighting scheme to replicate our desire for Correctness within the generated solutions. Different purposes might tune these weights in a different way however we count on Correctness to stay a dominant issue.
Moreover, the next strategies have been used to keep away from positional bias and enhance reliability:
- Low temperature (temperature 0.1) to make sure reproducibility.
- Single-answer grading as a substitute of pairwise comparability.
- Chain of ideas to let the LLM motive concerning the grading course of earlier than giving the ultimate rating.
- Few-shots era the place the LLM is supplied with a number of examples within the grading rubric for every rating worth on every issue (Correctness, Comprehensiveness, Readability).
Experiment 1: Alignment with Human Grading
To substantiate the extent of settlement between human annotators and LLM judges, we despatched reply sheets (grading scale 0-3) from gpt-3.5-turbo and vicuna-33b to a labeling firm to gather human labels, after which in contrast the end result with GPT-4’s grading output. Beneath are the findings:
- Human and GPT-4 judges can attain above 80% settlement on the correctness and readability rating. And if we decrease the requirement to be smaller or equal than 1 rating distinction, the settlement degree can attain above 95%.
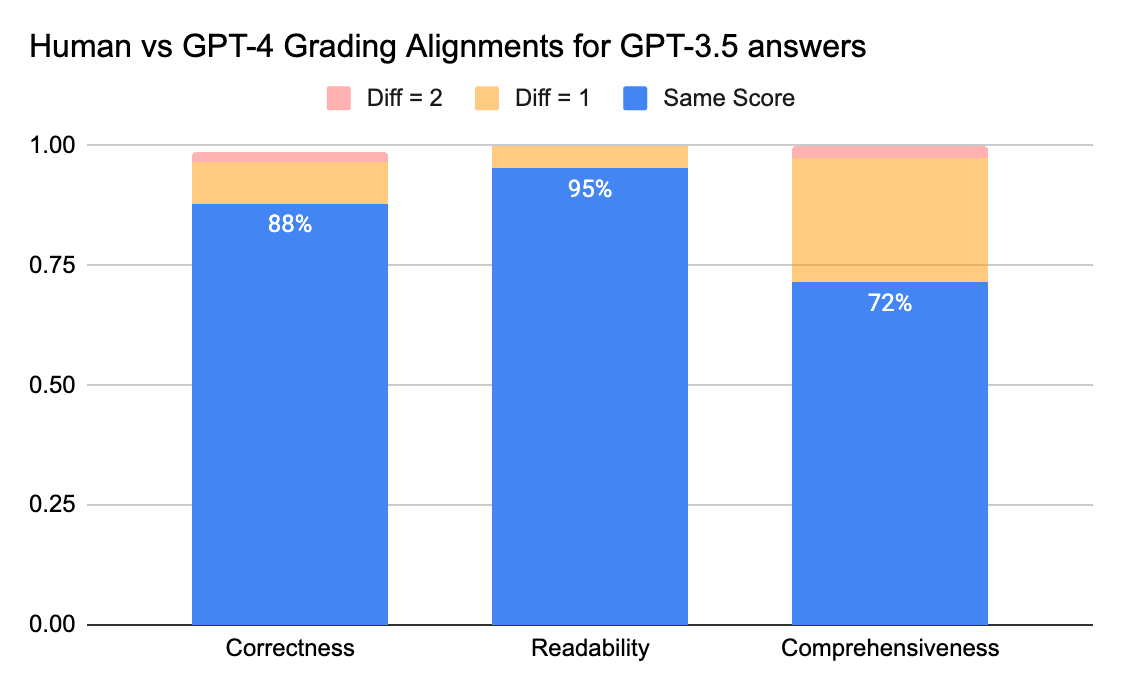
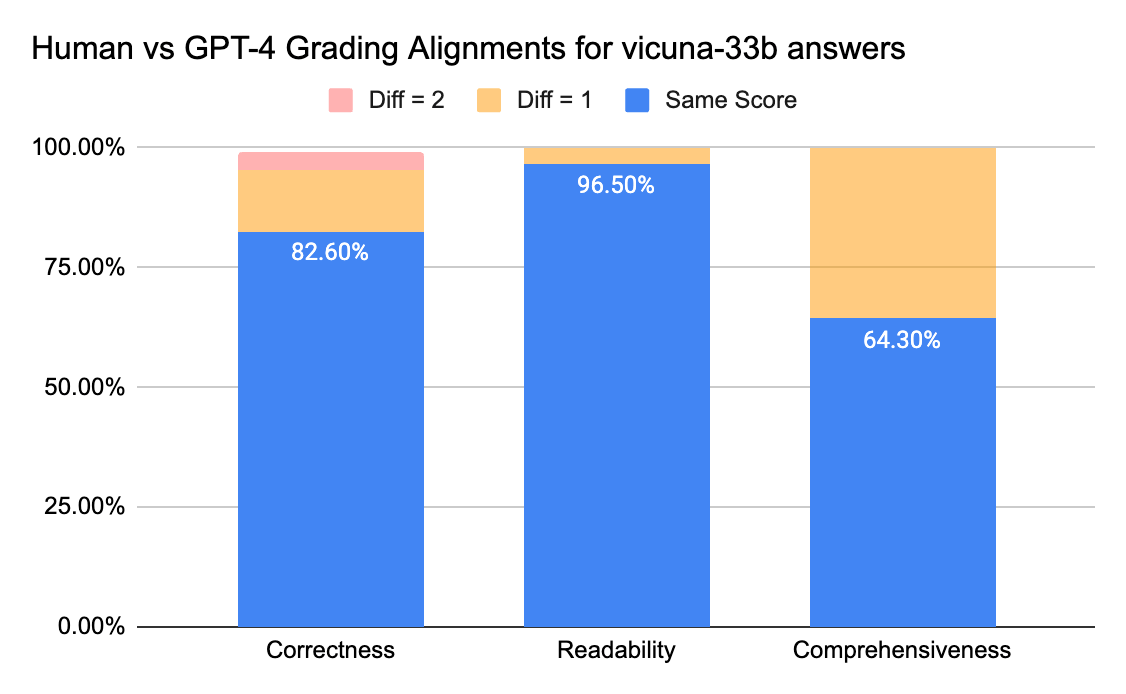
The Comprehensiveness metric has much less alignment, which matches what we’ve heard from enterprise stakeholders who shared that “complete” appears extra subjective than metrics like Correctness or Readability.
Experiment 2: Accuracy by means of Examples
The lmsys paper makes use of this immediate to instruct the LLM choose to judge based mostly on the helpfulness, relevance, accuracy, depth, creativity, and degree of element of the response. Nevertheless, the paper doesn’t share specifics on the grading rubric. From our analysis, we discovered many elements can considerably have an effect on the ultimate rating, for instance:
- The significance of various elements: Helpfulness, Relevance, Accuracy, Depth, Creativity
- The interpretation of things like Helpfulness is ambiguous
- If various factors battle with one another, the place a solution is useful however will not be correct
We developed a rubric for instructing an LLM choose for a given grading scale, by attempting the next:
- Authentic Immediate: Beneath is the unique immediate used within the lmsys paper:
|
|
We tailored the unique lmsys paper immediate to emit our metrics about correctness, comprehensiveness and readability, and likewise immediate the choose to supply one line justification earlier than giving every rating (to profit from chain-of-thought reasoning). Beneath are the zero-shot model of the immediate which doesn’t present any instance, and the few-shot model of the immediate which offers one instance for every rating. Then we used the identical reply sheets as enter and in contrast the graded outcomes from the 2 immediate sorts.
- Zero Shot Studying: require the LLM choose to emit our metrics about correctness, comprehensiveness and readability, and likewise immediate the choose to supply one line justification for every rating.
|
|
- Few Pictures Studying: We tailored the zero shot immediate to supply express examples for every rating within the scale. The brand new immediate:
|
|
From this experiment, we discovered a number of issues:
- Utilizing the Few Pictures immediate with GPT-4 didn’t make an apparent distinction within the consistency of outcomes. After we included the detailed grading rubric with examples we didn’t see a noticeable enchancment in GPT-4’s grading outcomes throughout totally different LLM fashions. Curiously, it brought on a slight variance within the vary of the scores.
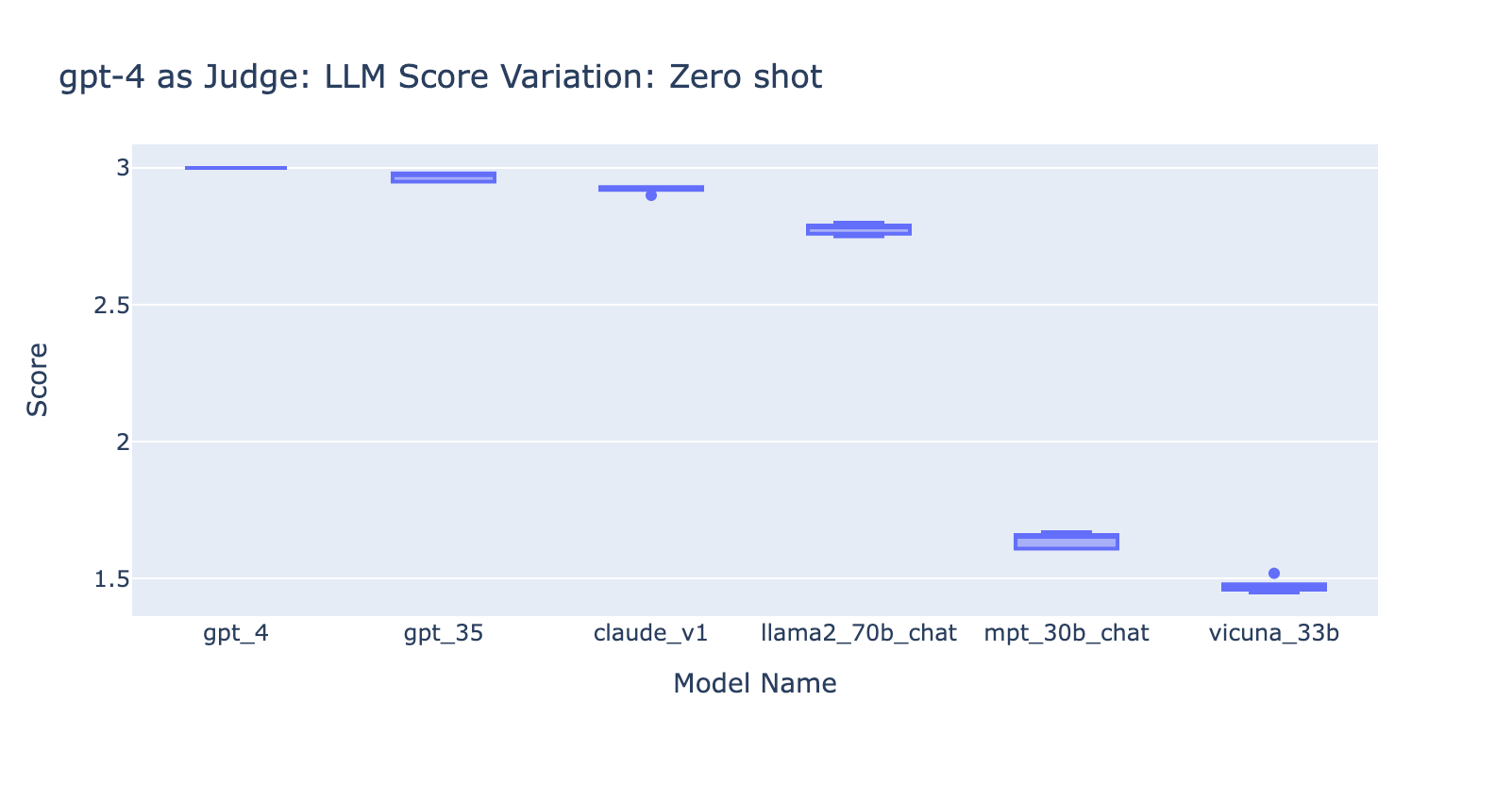
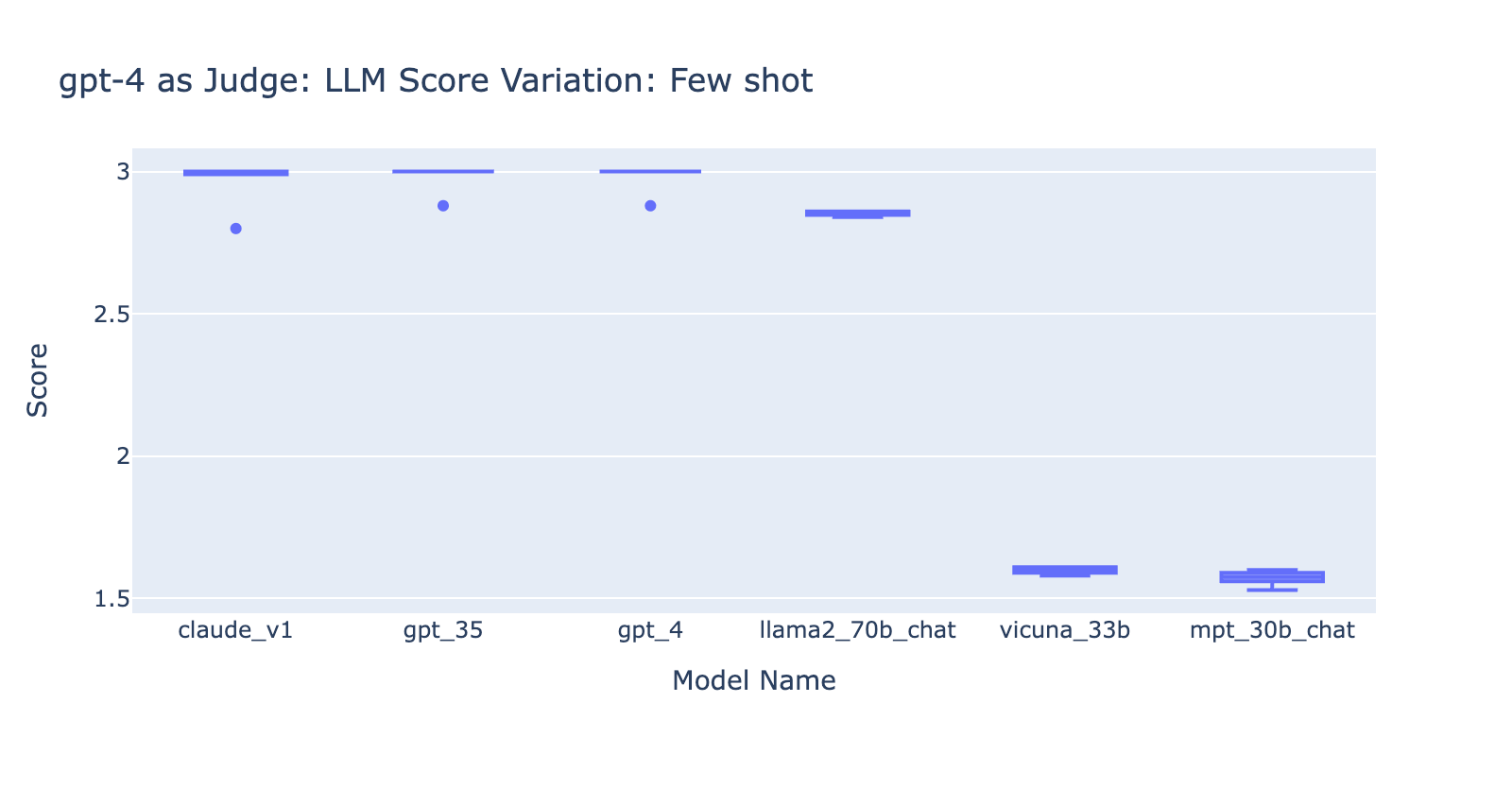
- Together with few examples for GPT-3.5-turbo-16k considerably improves the consistency of the scores, and makes the end result usable. Together with detailed grading rubric/examples has very apparent enchancment on the grading end result from GPT-3.5 (chart on the suitable aspect) Although the precise common rating worth is barely totally different between GPT-4 and GPT-3.5 (rating 3.0 vs rating 2.6), the rating and precision stays pretty constant
- Quite the opposite, (screenshot on the left) utilizing GPT-3.5 with no grading rubric will get very inconsistent outcomes and is totally unusable
- Observe that we’re utilizing GPT-3.5-turbo-16k as a substitute of GPT-3.5-turbo because the immediate could be bigger than 4k tokens.
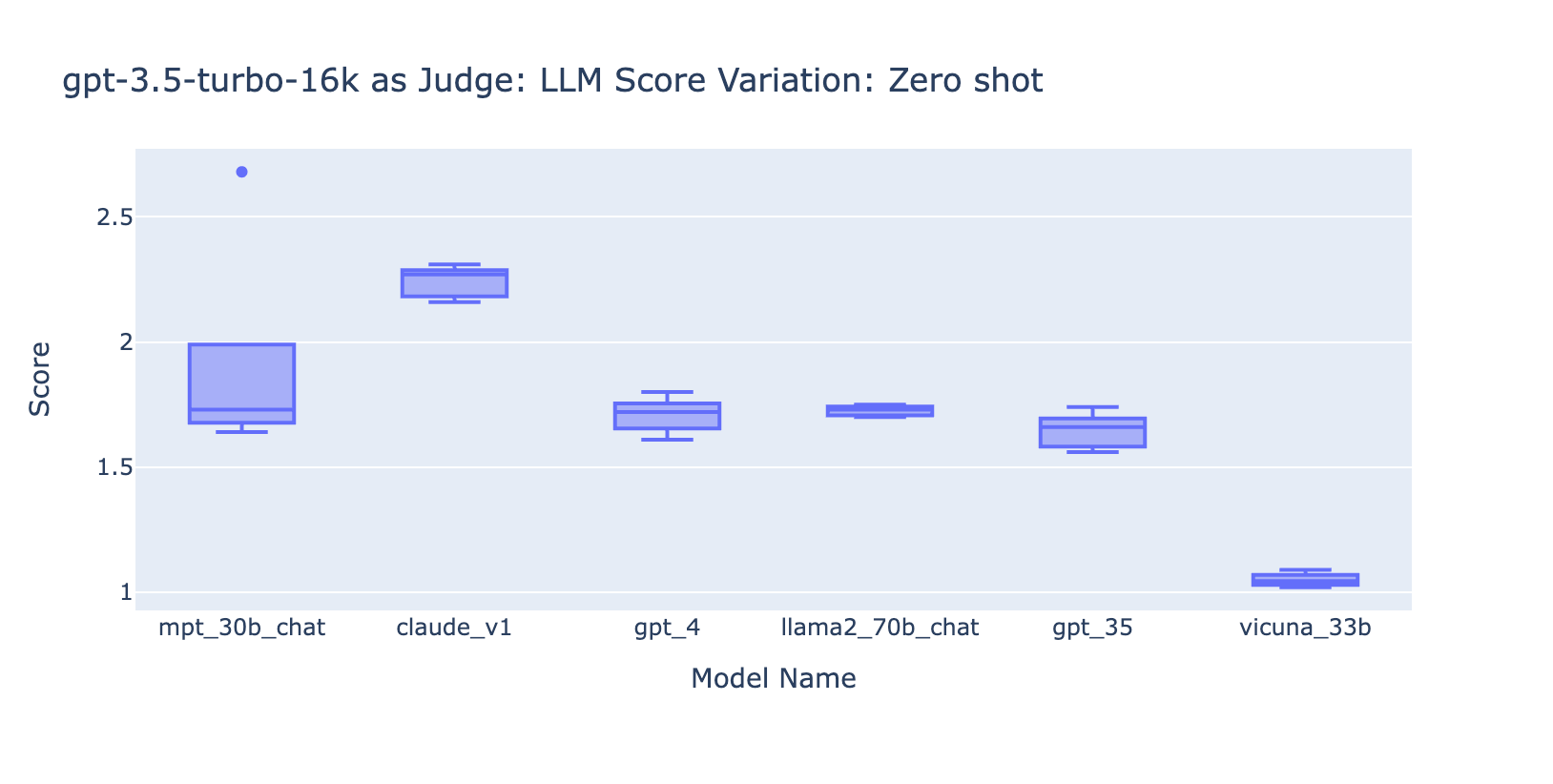
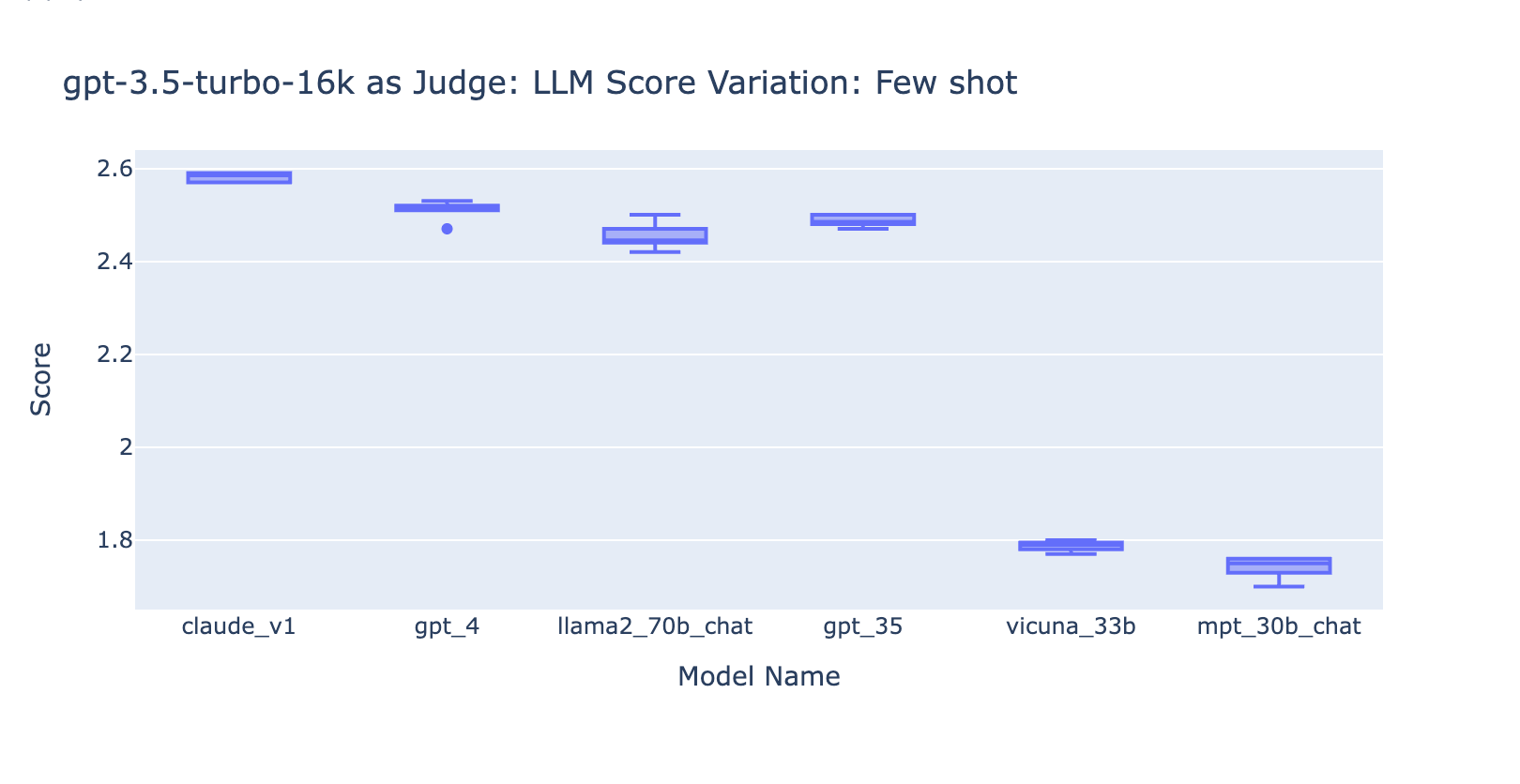
Experiment 3: Applicable Grade Scales
The LLM-as-judge paper makes use of a non-integer 0~10 scale (i.e. float) for the grading scale; in different phrases, it makes use of a excessive precision rubric for the ultimate rating. We discovered these high-precision scales trigger points downstream with the next:
- Consistency: Evaluators–each human and LLM–struggled to carry the identical customary for a similar rating when grading on excessive precision. In consequence, we discovered that output scores are much less constant throughout judges if you happen to transfer from low-precision to high-precision scales.
- Explainability: Moreover, if we need to cross-validate the LLM-judged outcomes with human-judged outcomes we should present directions on find out how to grade solutions. It is extremely troublesome to supply correct directions for every “rating” in a high-precision grading scale–for instance, what’s a very good instance for a solution that’s scored at 5.1 as in comparison with 5.6?
We experimented with numerous low-precision grading scales to supply steering on the “greatest” one to make use of, finally we suggest an integer scale of 0-3 or 0-4 (if you wish to follow the Likert scale). We tried 0-10, 1-5, 0-3, and 0-1 and discovered:
- Binary grading works for easy metrics like “usability” or “good/dangerous”.
- Scales like 0-10 are troublesome to give you distinguishing standards between all scores.
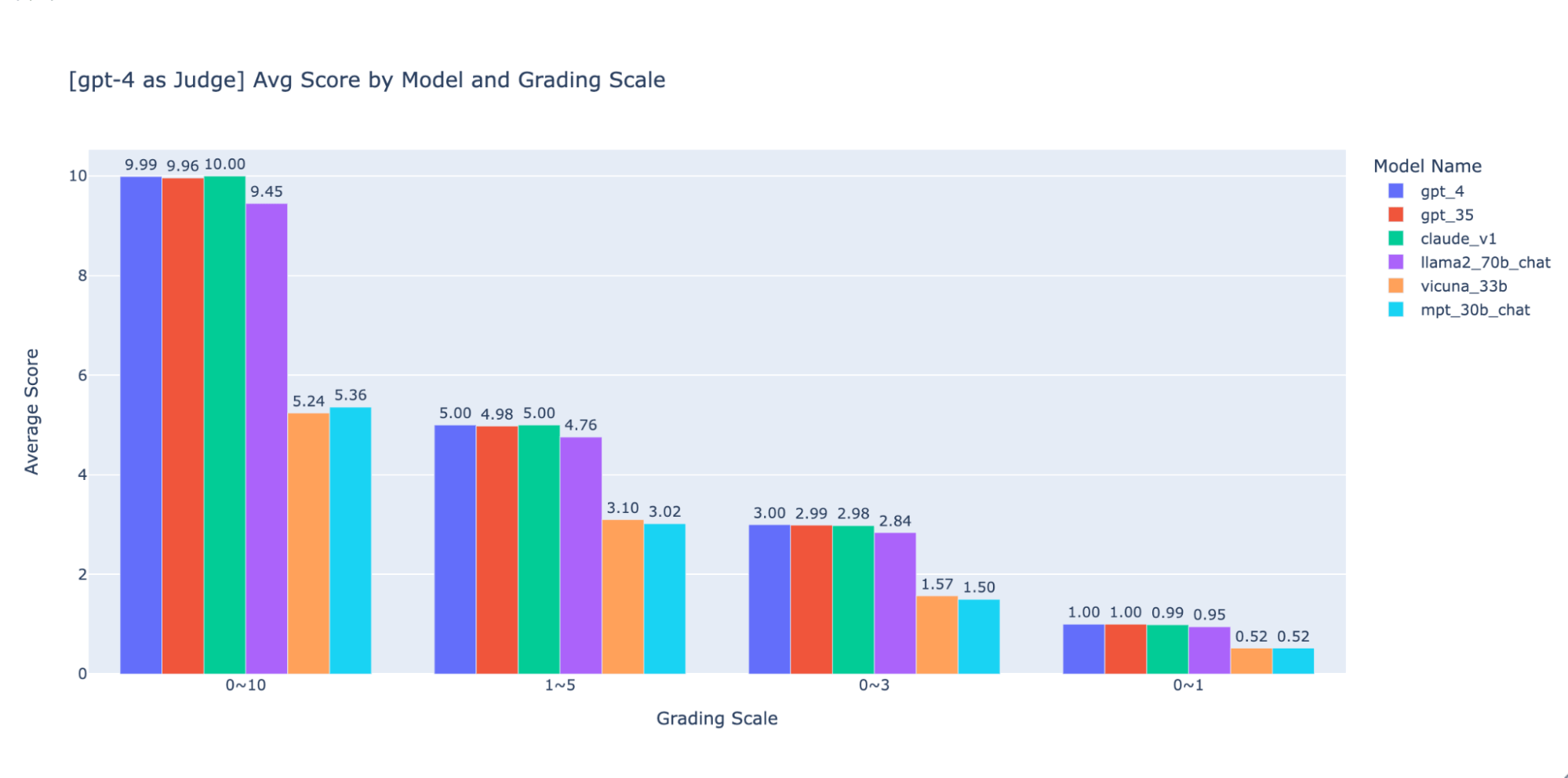
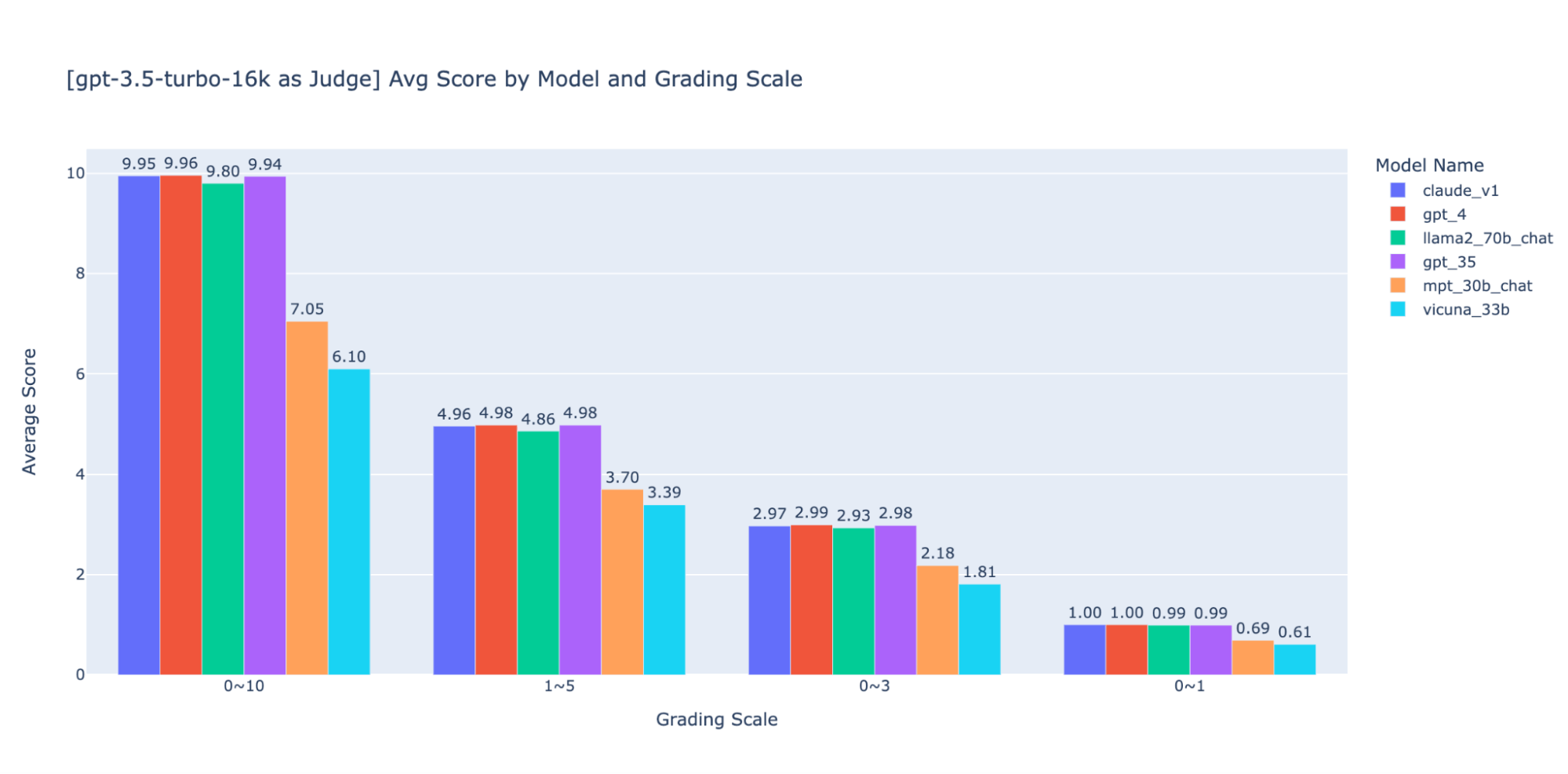
As proven within the plots above, each GPT-4 and GPT-3.5 can retain constant rating of outcomes utilizing totally different low-precision grading scales, thus utilizing a decrease grading scale like 0~3 or 1~5 can steadiness the precision with explainability)
Thus we suggest 0-3 or 1-5 as a grading scale to make it simpler to align with human labels, motive about scoring standards, and supply examples for every rating within the vary.
Experiment 4: Applicability Throughout Use Instances
The LLM-as-judge paper reveals that each LLM and human judgment ranks the Vicuna-13B mannequin as an in depth competitor to GPT-3.5:
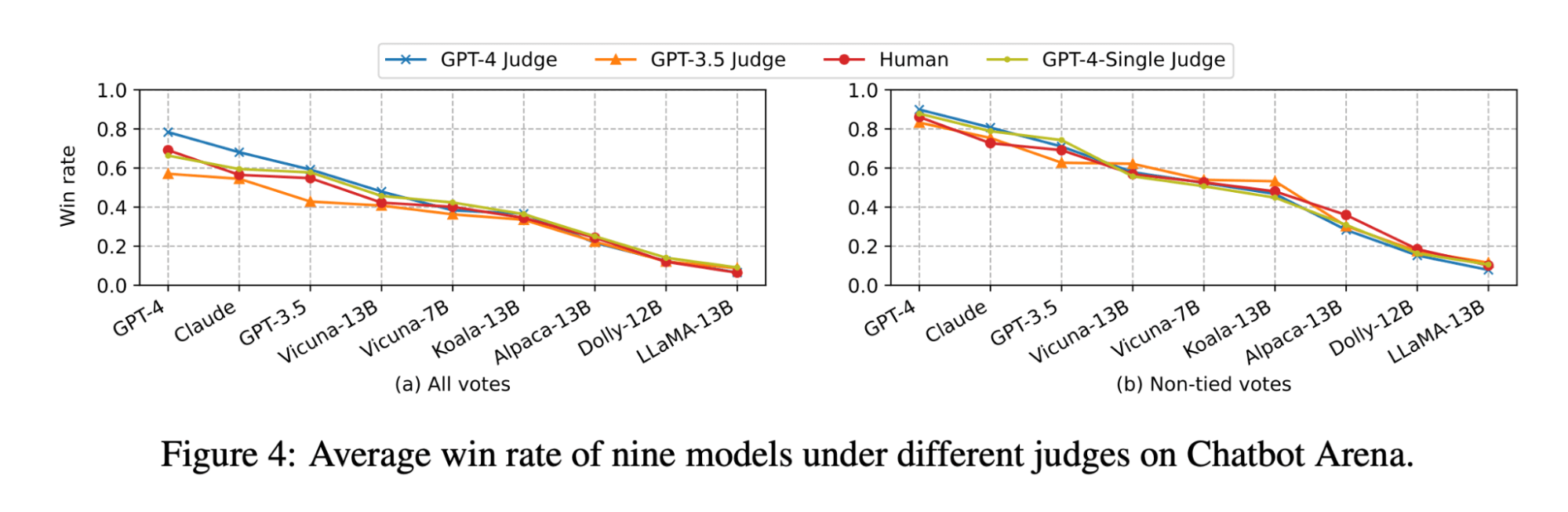
(The determine is coming from Determine 4 of the LLM-as-judge paper: https://arxiv.org/pdf/2306.05685.pdf )
Nevertheless, once we benchmarked the set of fashions for our doc Q&A use circumstances, we discovered that even the a lot bigger Vicuna-33B mannequin has a noticeably worse efficiency than GPT-3.5 when answering questions based mostly on context. These findings are additionally verified by GPT-4, GPT-3.5 and human judges (as talked about in Experiment 1) which all agree that Vicuna-33B is performing worse than GPT-3.5.
We appeared nearer on the benchmark dataset proposed by the paper and located that the 3 classes of duties (writing, math, data) don’t immediately replicate or contribute to the mannequin’s potential to synthesize a solution based mostly on a context. As a substitute, intuitively, doc Q&A use circumstances want benchmarks on studying comprehension and instruction following. Thus analysis outcomes can’t be transferred between use circumstances and we have to construct use-case-specific benchmarks so as to correctly consider how good a mannequin can meet buyer wants.
Use MLflow to leverage our greatest practices
With the experiments above, we explored how various factors can considerably have an effect on the analysis of a chatbot and confirmed that LLM as a choose can largely replicate human preferences for the doc Q&A use case. At Databricks, we’re evolving the MLflow Analysis API to assist your workforce successfully consider your LLM purposes based mostly on these findings. MLflow 2.4 launched the Analysis API for LLMs to match numerous fashions’ textual content output side-by-side, MLflow 2.6 launched LLM-based metrics for analysis like toxicity and perplexity, and we’re working to assist LLM-as-a-judge within the close to future!
Within the meantime, we compiled the record of sources we referenced in our analysis under:
- Doc_qa repository
- The code and knowledge we used to conduct the experiments
- LLM-as-Decide Analysis paper from lmsys group
- The paper is the primary analysis for utilizing LLM as choose for the informal chat use circumstances, it extensively explored the feasibility and professionals and cons of utilizing LLM (GPT-4, ClaudeV1, GPT-3.5) because the choose for duties in writing, math, world data
[ad_2]