
[ad_1]
Based mostly on immutable info (occasions), event-driven architectures (EDAs) permit companies to achieve deeper insights into their prospects’ habits, unlocking extra correct and sooner decision-making processes that result in higher buyer experiences. In EDAs, fashionable occasion brokers, akin to Amazon EventBridge and Apache Kafka, play a key position to publish and subscribe to occasions. EventBridge is a serverless occasion bus that ingests knowledge from your individual apps, software program as a service (SaaS) apps, and AWS providers and routes that knowledge to targets. Though there’s overlap of their position because the spine in EDAs, each options emerged from completely different downside statements and supply distinctive options to unravel particular use instances. With a stable understanding of each applied sciences and their main use instances, builders can create easy-to-use, maintainable, and evolvable EDAs.
If the use case is nicely outlined and straight maps to 1 occasion bus, akin to occasion streaming and analytics with streaming occasions (Kafka) or utility integration with simplified and constant occasion filtering, transformation, and routing on discrete occasions (EventBridge), the choice for a specific dealer expertise is easy. Nonetheless, organizations and enterprise necessities are sometimes extra complicated and past the capabilities of 1 dealer expertise. In nearly any case, selecting an occasion dealer shouldn’t be a binary determination. Combining complementary dealer applied sciences and embracing their distinctive strengths is a stable strategy to construct easy-to-use, maintainable, and evolvable EDAs. To make the combination between Kafka and EventBridge even smoother, AWS open-sourced the EventBridge Connector primarily based on Apache Kafka. This lets you devour from on-premises Kafka deployments and keep away from point-to-point communication, whereas utilizing the present information and toolset of Kafka Join.
Streaming functions allow stateful computations over unbound datasets. This permits real-time use instances akin to anomaly detection, event-time computations, and far more. These functions may be constructed utilizing frameworks akin to Apache Flink, Apache Spark, or Kafka Streams. Though a few of these frameworks assist sending occasions to downstream methods aside from Apache Kafka, there isn’t any standardized approach of doing so throughout frameworks. It could require every utility proprietor to construct their very own logic to ship occasions downstream. In an EDA, the popular approach to deal with such a situation is to publish occasions to an occasion bus after which ship them downstream.
There are two methods to ship occasions from Apache Kafka to EventBridge: the popular technique utilizing Amazon EventBridge Pipes or the EventBridge sink connector for Kafka Join. On this publish, we discover when to make use of which possibility and find out how to construct an EDA utilizing the EventBridge sink connector and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
EventBridge sink connector vs. EventBridge Pipes
EventBridge Pipes connects sources to targets with a point-to-point integration, supporting occasion filtering, transformations, enrichment, and occasion supply to over 14 AWS providers and exterior HTTPS-based targets utilizing API Locations. That is the popular and most straightforward technique to ship occasions from Kafka to EventBridge because it simplifies the setup and operations with a pleasant developer expertise.
Alternatively, below the next circumstances you may need to select the EventBridge sink connector to ship occasions from Kafka on to EventBridge Occasion Buses:
- You’re have already invested in processes and tooling across the Kafka Join framework because the platform of your option to combine with different methods and providers
- You have to combine with a Kafka-compatible schema registry e.g., the AWS Glue Schema Registry, supporting Avro and Protobuf knowledge codecs for occasion serialization and deserialization
- You need to ship occasions from on-premises Kafka environments on to EventBridge Occasion Buses
Overview of resolution
On this publish, we present you find out how to use Kafka Join and the EventBridge sink connector to ship Avro-serialized occasions from Amazon Managed Streaming for Apache Kafka (Amazon MSK) to EventBridge. This allows a seamless and constant knowledge circulate from Apache Kafka to dozens of supported EventBridge AWS and associate targets, akin to Amazon CloudWatch, Amazon SQS, AWS Lambda, and HTTPS targets like Salesforce, Datadog, and Snowflake utilizing EventBridge API locations. The next diagram illustrates the event-driven structure used on this weblog publish primarily based on Amazon MSK and EventBridge.
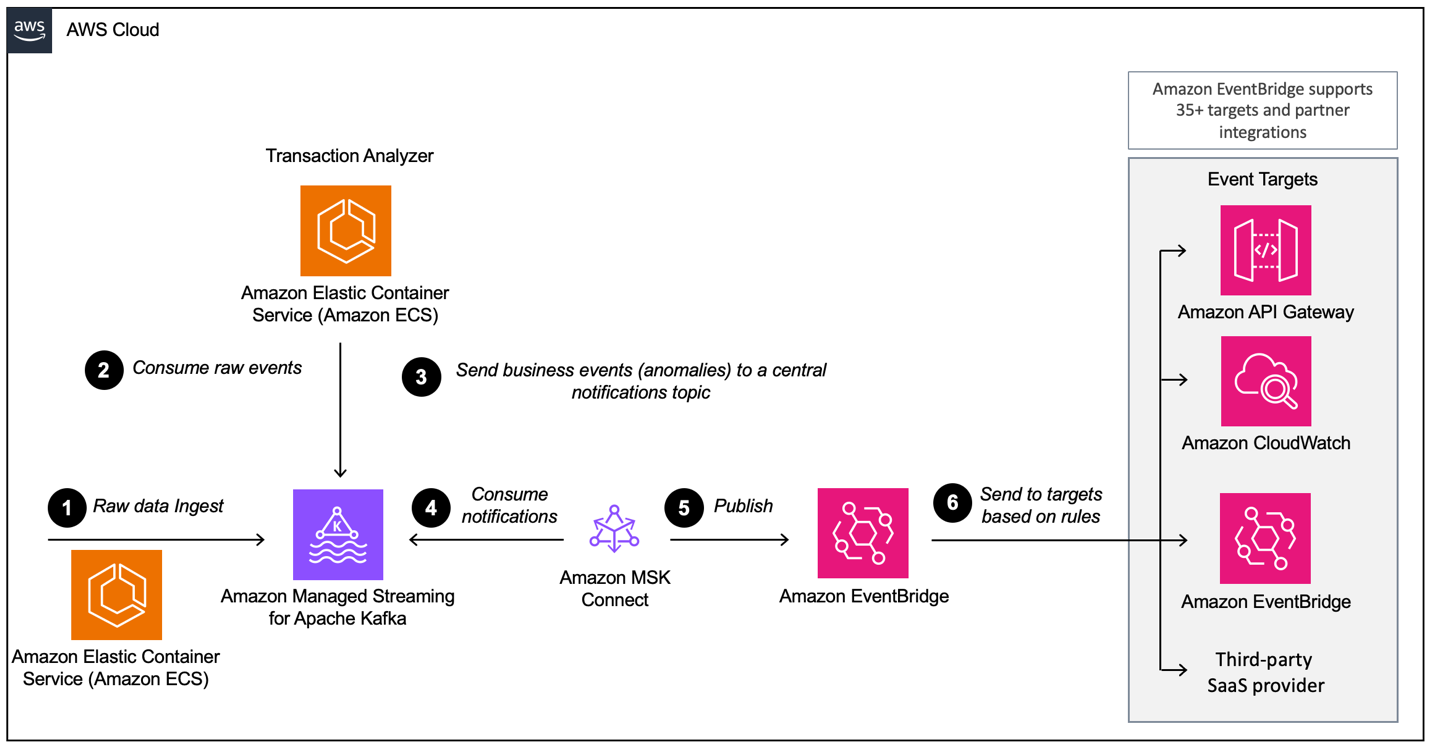
The workflow consists of the next steps:
- The demo utility generates bank card transactions, that are despatched to Amazon MSK utilizing the Avro format.
- An analytics utility working on Amazon Elastic Container Service (Amazon ECS) consumes the transactions and analyzes them if there’s an anomaly.
- If an anomaly is detected, the applying emits a fraud detection occasion again to the MSK notification matter.
- The EventBridge connector consumes the fraud detection occasions from Amazon MSK in Avro format.
- The connector converts the occasions to JSON and sends them to EventBridge.
- In EventBridge, we use JSON filtering guidelines to filter our occasions and ship them to different providers or one other Occasion Bus. On this instance, fraud detection occasions are despatched to Amazon CloudWatch Logs for auditing and introspection, and to a third-party SaaS supplier to showcase how straightforward it’s to combine with third-party APIs, akin to Salesforce.
Stipulations
For this walkthrough, it’s best to have the next stipulations:
Deploy the AWS CDK stack
This walkthrough requires you to deploy an AWS CDK stack to your account. You possibly can deploy the complete stack finish to finish or simply the required assets to observe together with this publish.
- In your terminal, run the next command:
- Navigate to the cdk listing:
- Deploy the AWS CDK stack primarily based in your preferences:
- If you wish to see the whole setup defined on this publish, run the next command:
- If you wish to deploy the connector by yourself however have the required assets already, together with the MSK cluster, AWS Id and Entry Administration (IAM) roles, safety teams, knowledge generator, and so forth, run the next command:
Deploy the EventBridge sink connector on Amazon MSK Join
When you deployed the CDK stack in FULL mode, you may skip this part and transfer on to Create EventBridge guidelines.
The connector wants an IAM position that enables studying the information from the MSK cluster and sending data downstream to EventBridge.
Add connector code to Amazon S3
Full the next steps to add the connector code to Amazon Easy Storage Service (Amazon S3):
- Navigate to the GitHub repo.
- Obtain the discharge 1.0.0 with the AWS Glue Schema Registry dependencies included.
- On the Amazon S3 console, select Buckets within the navigation pane.
- Select Create bucket.
- For Bucket identify, enter
eventbridgeconnector-bucket-${AWS_ACCOUNT_ID}.
As As a result of S3 buckets have to be globally distinctive, substitute ${AWS_ACCOUNT_ID} together with your precise AWS account ID. For instance, eventbridgeconnector-bucket-123456789012.
- Open the bucket and select Add.
- Choose the .jar file that you simply downloaded from the GitHub repository and select Add.

Create a customized plugin
We now have our utility code in Amazon S3. As a subsequent step, we create a customized plugin in Amazon MSK Join. Full the next steps:
- On the Amazon MSK console, select Customized plugins within the navigation pane below MSK Join.
- Select Create customized plugin.
- For S3 URI – Customized plugin object, browse to the file named
kafka-eventbridge-sink-with-gsr-dependencies.jarwithin the S3 bucketeventbridgeconnector-bucket-${AWS_ACCOUNT_ID}for the EventBridge connector. - For Customized plugin identify, enter
msk-eventBridge-sink-plugin-v1. - Enter an elective description.
- Select Create customized plugin.

- Look forward to plugin to transition to the standing Lively.
Create a connector
Full the next steps to create a connector in MSK Join:
- On the Amazon MSK console, select Connectors within the navigation pane below MSK Join.
- Select Create connector.
- Choose Use present customized plugin and below Customized plugins, choose the plugin
msk-eventBridge-sink-plugin-v1that you simply created earlier. - Select Subsequent.
- For Connector identify, enter
msk-eventBridge-sink-connector. - Enter an elective description.
- For Cluster kind, choose MSK cluster.
- For MSK clusters, choose the cluster you created earlier.
- For Authentication, select IAM.
- Below Connector configurations, enter the next settings (for extra particulars on the configuration, see the GitHub repository):
- Be certain to
substitute aws.eventbridge.eventbus.arn,aws.eventbridge.area, andworth.converter.areawith the values from the prerequisite stack. - Within the Connector capability part, choose Autoscaled for Capability kind.
- Depart the default worth of 1 for MCU depend per employee.
- Maintain all default values for Connector capability.
- For Employee configuration, choose Use the MSK default configuration.
- Below Entry permissions, select the customized IAM position
KafkaEventBridgeSinkStack-connectorRole, which you created throughout the AWS CDK stack deployment. - Select Subsequent.
- Select Subsequent once more.
- For Log supply, choose Ship to Amazon CloudWatch Logs.
- For Log group, select
/aws/mskconnect/eventBridgeSinkConnector. - Select Subsequent.
- Below Assessment and Create, validate all of the settings and select Create connector.
The connector might be now within the state Creating. It will possibly take as much as a number of minutes for the connector to transition into the standing Operating.
Create EventBridge guidelines
Now that the connector is forwarding occasions to EventBridge, we are able to use EventBridge guidelines to filter and ship occasions to different targets. Full the next steps to create a rule:
- On the EventBridge console, select Guidelines within the navigation pane.
- Select Create rule.
- Enter
eb-to-cloudwatch-logs-and-webhookfor Title. - Choose eventbridge-sink-eventbus for Occasion bus.
- Select Subsequent.
- Choose Customized sample (JSON editor), select Insert, and substitute the occasion sample with the next code:
- Select Subsequent.
- For Goal 1, choose CloudWatch log group and enter
kafka-eventsfor Log Group. - Select Add one other goal.
- (Non-obligatory: Create an API vacation spot) For Goal 2, choose EventBridge API vacation spot for Goal sorts.
- Choose Create a brand new API vacation spot.
- Enter a descriptive identify for Title.
- Add the URL and enter it as API vacation spot endpoint. (This may be the URL of your Datadog, Salesforce, and so forth. endpoint)
- Choose POST for HTTP technique.
- Choose Create a brand new connection for Connection.
- For Connection Title, enter a reputation.
- Choose Different as Vacation spot kind and choose API Key as Authorization Sort.
- For API key identify and Worth, enter your keys.
- Select Subsequent.
- Validate your inputs and select Create rule.

The next screenshot of the CloudWatch Logs console reveals a number of occasions from EventBridge.

Run the connector in manufacturing
On this part, we dive deeper into the operational features of the connector. Particularly, we focus on how the connector scales and find out how to monitor it utilizing CloudWatch.
Scale the connector
Kafka connectors scale by way of the variety of duties. The code design of the EventBridge sink connector doesn’t restrict the variety of duties that it may possibly run. MSK Join gives the compute capability to run the duties, which may be from Provisioned or Autoscaled kind. Throughout the deployment of the connector, we select the capability kind Autoscaled and 1 MCU per employee (which represents 1vCPU and 4GiB of reminiscence). This implies MSK Join will scale the infrastructure to run duties however not the variety of duties. The variety of duties is outlined by the connector. By default, the connector will begin with the variety of duties outlined in duties.max within the connector configuration. If this worth is greater than the partition depend of the processed matter, the variety of duties might be set to the variety of partitions throughout the Kafka Join rebalance.
Monitor the connector
MSK Join emits metrics to CloudWatch for monitoring by default. In addition to MSK Join metrics, the offset of the connector also needs to be monitored in manufacturing. Monitoring the offset offers insights if the connector can sustain with the information produced within the Kafka cluster.
Clear up
To wash up your assets and keep away from ongoing fees, full the next the steps:
- On the Amazon MSK console, select Connectors within the navigation pane below MSK Join.
- Choose the connectors you created and select Delete.
- Select Clusters within the navigation pane.
- Choose the cluster you created and select Delete on the Actions menu.
- On the EventBridge console, select Guidelines within the navigation pane.
- Select the occasion bus eventbridge-sink-eventbus.
- Choose all the foundations you created and select Delete.
- Affirm the elimination by getting into delete, then select Delete.
When you deployed the AWS CDK stack with the context PREREQ, delete the .jar file for the connector.
- On the Amazon S3 console, select Buckets within the navigation pane.
- Navigate to the bucket the place you uploaded your connector and delete the
kafka-eventbridge-sink-with-gsr-dependencies.jarfile.
Impartial from the chosen deployment mode, all different AWS assets may be deleted by utilizing AWS CDK or AWS CloudFormation. Run cdk destroy from the repository listing to delete the CloudFormation stack.
Alternatively, on the AWS CloudFormation console, choose the stack KafkaEventBridgeSinkStack and select Delete.
Conclusion
On this publish, we confirmed how you should use MSK Hook up with run the AWS open-sourced Kafka connector for EventBridge, find out how to configure the connector to ahead a Kafka matter to EventBridge, and find out how to use EventBridge guidelines to filter and ahead occasions to CloudWatch Logs and a webhook.
To study extra concerning the Kafka connector for EventBridge, consult with Amazon EventBridge publicizes open-source connector for Kafka Join, in addition to the MSK Join Developer Information and the code for the connector on the GitHub repo.
Concerning the Authors
 Florian Mair is a Senior Options Architect and knowledge streaming professional at AWS. He’s a technologist that helps prospects in Germany succeed and innovate by fixing enterprise challenges utilizing AWS Cloud providers. In addition to working as a Options Architect, Florian is a passionate mountaineer, and has climbed a few of the highest mountains throughout Europe.
Florian Mair is a Senior Options Architect and knowledge streaming professional at AWS. He’s a technologist that helps prospects in Germany succeed and innovate by fixing enterprise challenges utilizing AWS Cloud providers. In addition to working as a Options Architect, Florian is a passionate mountaineer, and has climbed a few of the highest mountains throughout Europe.
 Benjamin Meyer is a Senior Options Architect at AWS, centered on Video games companies in Germany to unravel enterprise challenges by utilizing AWS Cloud providers. Benjamin has been an avid technologist for 7 years, and when he’s not serving to prospects, he may be discovered growing cell apps, constructing electronics, or tending to his cacti.
Benjamin Meyer is a Senior Options Architect at AWS, centered on Video games companies in Germany to unravel enterprise challenges by utilizing AWS Cloud providers. Benjamin has been an avid technologist for 7 years, and when he’s not serving to prospects, he may be discovered growing cell apps, constructing electronics, or tending to his cacti.
[ad_2]