
[ad_1]
This can be a visitor weblog put up co-written with Patrick Oberherr from Contentful and Johannes Günther from Netlight Consulting.
This weblog put up reveals how you can enhance safety in a knowledge pipeline structure based mostly on Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Amazon Elastic Kubernetes Service (Amazon EKS) by establishing fine-grained permissions, utilizing HashiCorp Terraform for infrastructure as code.
Many AWS clients use Amazon EKS to execute their knowledge workloads. Some great benefits of Amazon EKS embrace completely different compute and storage choices relying on workload wants, larger useful resource utilization by sharing underlying infrastructure, and a vibrant open-source neighborhood that gives purpose-built extensions. The Information on EKS mission supplies a sequence of templates and different sources to assist clients get began on this journey. It features a description of utilizing Amazon MWAA as a job scheduler.
Contentful is an AWS buyer and AWS Accomplice Community (APN) associate. Behind the scenes of their Software program-as-a-Service (SaaS) product, the Contentful Composable Content material Platform, Contentful makes use of insights from knowledge to enhance enterprise decision-making and buyer expertise. Contentful engaged Netlight, an APN consulting associate, to assist arrange a knowledge platform to assemble these insights.
Most of Contentful’s software workloads run on Amazon EKS, and information of this service and Kubernetes is widespread within the group. That’s why Contentful’s knowledge engineering staff determined to run knowledge pipelines on Amazon EKS as effectively. For job scheduling, they began with a self-operated Apache Airflow on an Amazon EKS cluster and later switched to Amazon MWAA to scale back engineering and operations overhead. The job execution remained on Amazon EKS.
Contentful runs a fancy knowledge pipeline utilizing this infrastructure, together with ingestion from a number of knowledge sources and completely different transformation jobs, for instance utilizing dbt. The entire pipeline shares a single Amazon MWAA atmosphere and a single Amazon EKS cluster. With a various set of workloads in a single atmosphere, it’s crucial to use the precept of least privilege, making certain that particular person duties or elements have solely the precise permissions they should perform.
By segmenting permissions based on roles and duties, Contentful’s knowledge engineering staff was capable of create a extra strong and safe knowledge processing atmosphere, which is important for sustaining the integrity and confidentiality of the info being dealt with.
On this weblog put up, we stroll by means of establishing the infrastructure from scratch and deploying a pattern software utilizing Terraform, Contentful’s instrument of alternative for infrastructure as code.
Stipulations
To comply with alongside this weblog put up, you want the most recent model of the next instruments put in:
Overview
On this weblog put up, you’ll create a pattern software with the next infrastructure:
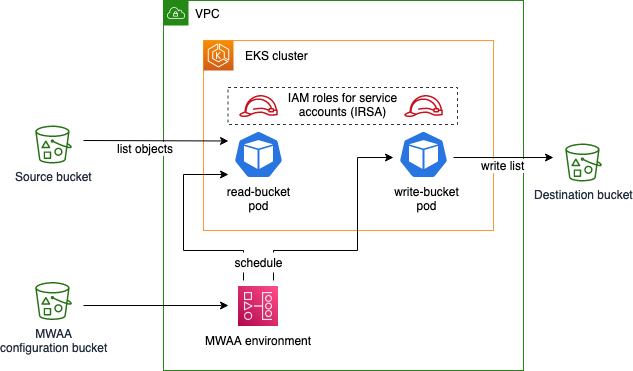
The pattern Airflow workflow lists objects within the supply bucket, quickly shops this record utilizing Airflow XComs, and writes the record as a file to the vacation spot bucket. This software is executed utilizing Amazon EKS pods, scheduled by an Amazon MWAA atmosphere. You deploy the EKS cluster and the MWAA atmosphere right into a digital personal cloud (VPC) and apply least-privilege permissions to the EKS pods utilizing IAM roles for service accounts. The configuration bucket for Amazon MWAA incorporates runtime necessities, in addition to the applying code specifying an Airflow Directed Acyclic Graph (DAG).
Initialize the mission and create buckets
Create a file primary.tf with the next content material in an empty listing:
This file defines the Terraform AWS supplier in addition to the supply and vacation spot bucket, whose names are exported as AWS Methods Supervisor parameters. It additionally tells Terraform to add an empty object named dummy.txt into the supply bucket, which permits the Airflow pattern software we’ll create later to obtain a consequence when itemizing bucket content material.
Initialize the Terraform mission and obtain the module dependencies by issuing the next command:
Create the infrastructure:
Terraform asks you to acknowledge adjustments to the atmosphere after which begins deploying sources in AWS. Upon profitable deployment, you must see the next success message:
Create VPC
Create a brand new file vpc.tf in the identical listing as primary.tf and insert the next:
This file defines the VPC, a digital community, that can later host the Amazon EKS cluster and the Amazon MWAA atmosphere. Word that we use an present Terraform module for this, which wraps configuration of underlying community sources like subnets, route tables, and NAT gateways.
Obtain the VPC module:
Deploy the brand new sources:
Word which sources are being created. By utilizing the VPC module in our Terraform file, a lot of the underlying complexity is taken away when defining our infrastructure, but it surely’s nonetheless helpful to know what precisely is being deployed.
Word that Terraform now handles sources we outlined in each recordsdata, primary.tf and vpc.tf, as a result of Terraform consists of all .tf recordsdata within the present working listing.
Create the Amazon MWAA atmosphere
Create a brand new file mwaa.tf and insert the next content material:
Like earlier than, we use an present module to avoid wasting configuration effort for the Amazon MWAA atmosphere. The module additionally creates the configuration bucket, which we use to specify the runtime dependency of the applying (apache-airflow-cncf-kubernetes) within the necessities.txt file. This bundle, together with the preinstalled bundle apache-airflow-amazon, permits interplay with Amazon EKS.
Obtain the MWAA module:
Deploy the brand new sources:
This operation takes 20–half-hour to finish.
Create the Amazon EKS cluster
Create a file eks.tf with the next content material:
To create the cluster itself, we benefit from the Amazon EKS Blueprints for Terraform mission. We additionally outline a managed node group with one node because the goal dimension. Word that in circumstances with fluctuating load, scaling your cluster with Karpenter as a substitute of the managed node group method proven above makes the cluster scale extra flexibly. We used managed node teams primarily due to the convenience of configuration.
We outline the id that the Amazon MWAA execution function assumes in Kubernetes utilizing the map_roles variable. After configuring the Terraform Kubernetes supplier, we give the Amazon MWAA execution function permissions to handle pods within the cluster.
Obtain the EKS Blueprints for Terraform module:
Deploy the brand new sources:
This operation takes about 12 minutes to finish.
Create IAM roles for service accounts
Create a file roles.tf with the next content material:
This file defines two Kubernetes service accounts, source-bucket-reader-sa and destination-bucket-writer-sa, and their permissions in opposition to the AWS API, utilizing IAM roles for service accounts (IRSA). Once more, we use a module from the Amazon EKS Blueprints for Terraform mission to simplify IRSA configuration. Word that each roles solely get the minimal permissions that they want, outlined utilizing AWS IAM insurance policies.
Obtain the brand new module:
Deploy the brand new sources:
Create the DAG
Create a file dag.py defining the Airflow DAG:
The DAG is outlined to run on an hourly schedule, with two duties read_bucket with service account source-bucket-reader-sa and write_bucket with service account destination-bucket-writer-sa, working after each other. Each are run utilizing the EksPodOperator, which is liable for scheduling the duties on Amazon EKS, utilizing the AWS CLI Docker picture to run instructions. The primary job lists recordsdata within the supply bucket and writes the record to Airflow XCom. The second job reads the record from XCom and shops it within the vacation spot bucket. Word that the service_account_name parameter differentiates what every job is permitted to do.
Create a file dag.tf to add the DAG code to the Amazon MWAA configuration bucket:
Deploy the adjustments:
The Amazon MWAA atmosphere routinely imports the file from the S3 bucket.
Run the DAG
In your browser, navigate to the Amazon MWAA console and choose your atmosphere. Within the prime right-hand nook, choose Open Airflow UI . It’s best to see the next:

To set off the DAG, within the Actions column, choose the play image after which choose Set off DAG. Click on on the DAG title to discover the DAG run and its outcomes.
Navigate to the Amazon S3 console and select the bucket beginning with “vacation spot”. It ought to include a file record.json not too long ago created by the write_bucket job. Obtain the file to discover its content material, a JSON record with a single entry.
Clear up
The sources you created on this walkthrough incur AWS prices. To delete the created sources, challenge the next command:
And approve the adjustments within the Terraform CLI dialog.
Conclusion
On this weblog put up, you discovered how you can enhance the safety of your knowledge pipeline working on Amazon MWAA and Amazon EKS by narrowing the permissions of every particular person job.
To dive deeper, use the working instance created on this walkthrough to discover the subject additional: What occurs if you happen to take away the service_account_name parameter from an Airflow job? What occurs if you happen to change the service account names within the two duties?
For simplicity, on this walkthrough we used a flat file construction with Terraform and Python recordsdata inside a single listing. We didn’t adhere to the commonplace module construction proposed by Terraform, which is mostly really useful. In a real-life mission, splitting up the mission into a number of Terraform initiatives or modules might also improve flexibility, velocity, and independence between groups proudly owning completely different components of the infrastructure.
Lastly, be sure to review the Information on EKS documentation, which supplies different beneficial sources for working your knowledge pipeline on Amazon EKS, in addition to the Amazon MWAA and Apache Airflow documentation for implementing your individual use circumstances. Particularly, take a look at this pattern implementation of a Terraform module for Amazon MWAA and Amazon EKS, which incorporates a extra mature method to Amazon EKS configuration and node automated scaling, in addition to networking.
When you’ve got any questions, you can begin a brand new thread on AWS re:Submit or attain out to AWS Help.
In regards to the Authors
 Ulrich Hinze is a Options Architect at AWS. He companions with software program corporations to architect and implement cloud-based options on AWS. Earlier than becoming a member of AWS, he labored for AWS clients and companions in software program engineering, consulting, and structure roles for 8+ years.
Ulrich Hinze is a Options Architect at AWS. He companions with software program corporations to architect and implement cloud-based options on AWS. Earlier than becoming a member of AWS, he labored for AWS clients and companions in software program engineering, consulting, and structure roles for 8+ years.
 Patrick Oberherr is a Workers Information Engineer at Contentful with 4+ years of working with AWS and 10+ years within the Information discipline. At Contentful he’s liable for infrastructure and operations of the info stack which is hosted on AWS.
Patrick Oberherr is a Workers Information Engineer at Contentful with 4+ years of working with AWS and 10+ years within the Information discipline. At Contentful he’s liable for infrastructure and operations of the info stack which is hosted on AWS.
 Johannes Günther is a cloud & knowledge guide at Netlight with 5+ years of working with AWS. He has helped purchasers throughout numerous industries designing sustainable cloud platforms and is AWS licensed.
Johannes Günther is a cloud & knowledge guide at Netlight with 5+ years of working with AWS. He has helped purchasers throughout numerous industries designing sustainable cloud platforms and is AWS licensed.
[ad_2]