
[ad_1]
At the moment, Databricks is happy to announce assist for Mixtral 8x7B in Mannequin Serving. Mixtral 8x7B is a sparse Combination of Specialists (MoE) open language mannequin that outperforms or matches many state-of-the-art fashions. It has the flexibility to deal with lengthy context lengths of as much as 32k tokens (roughly 50 pages of textual content), and its MoE structure supplies quicker inference, making it supreme for Retrieval-Augmented Era (RAG) and different enterprise use instances.
Databricks Mannequin Serving now supplies on the spot entry to Mixtral 8x7B with on-demand pricing on a production-grade, enterprise-ready platform. We assist hundreds of queries per second and supply seamless vector retailer integration, automated high quality monitoring, unified governance, and SLAs for uptime. This end-to-end integration supplies you with a quick path for deploying GenAI Programs into manufacturing.
What are Combination of Specialists Fashions?
Mixtral 8x7B makes use of a MoE structure, which is taken into account a major development over dense GPT-like architectures utilized by fashions resembling Llama2. In GPT-like fashions, every block includes an consideration layer and a feed-forward layer. The feed-forward layer within the MoE mannequin consists of a number of parallel sub-layers, every generally known as an “knowledgeable”, fronted by a “router” community that determines which consultants to ship the tokens to. Since the entire parameters in a MoE mannequin usually are not energetic for an enter token, MoE fashions are thought of “sparse” architectures. The determine beneath reveals it pictorially as proven within the sensible paper on change transformers. It is extensively accepted within the analysis group that every knowledgeable makes a speciality of studying sure facets or areas of the information [Shazeer et al.].
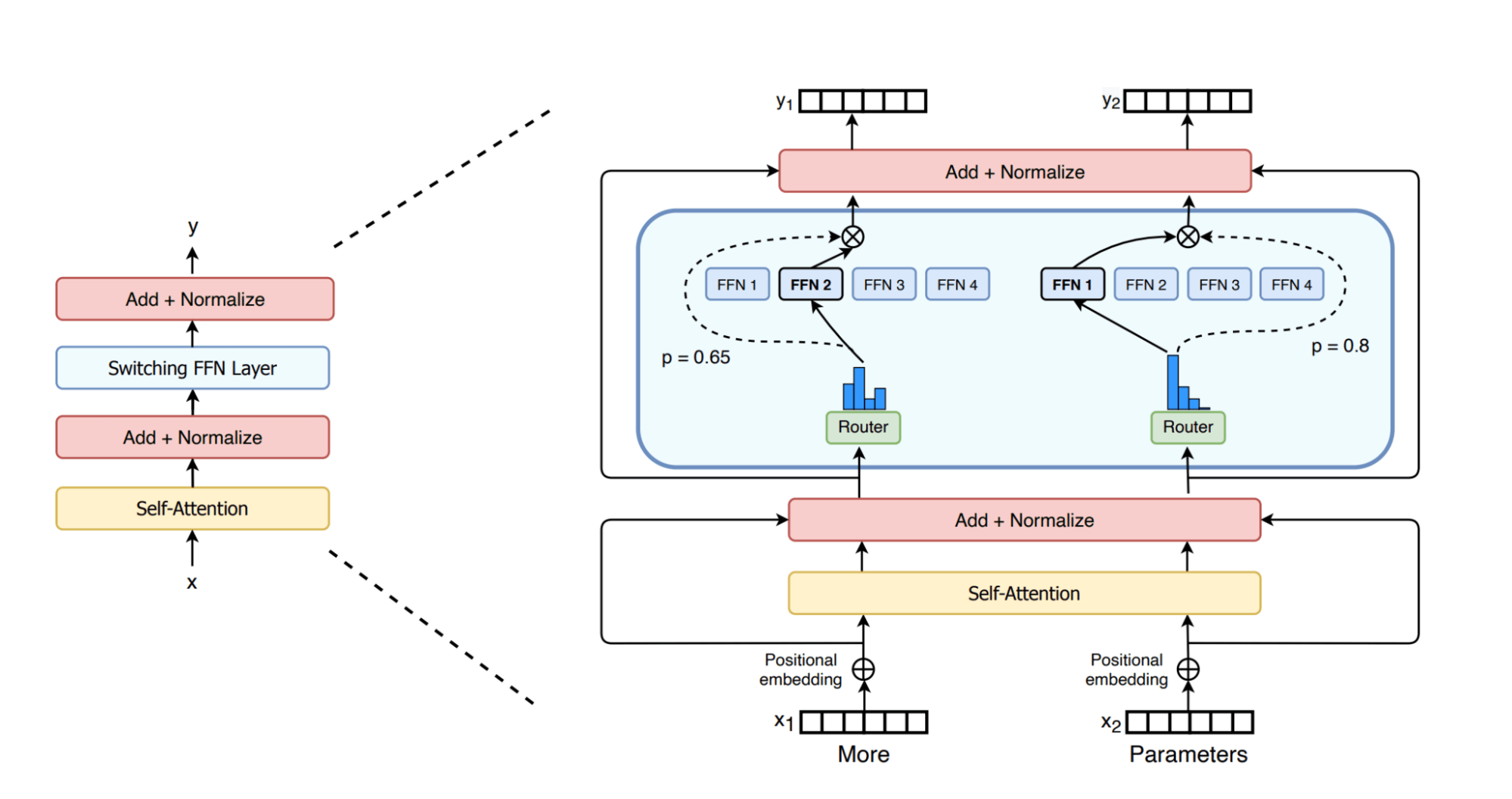
The primary benefit of MoE structure is that it permits scaling of the mannequin dimension with out the proportional improve in inference-time computation required for dense fashions. In MoE fashions, every enter token is processed by solely a choose subset of the obtainable consultants (e.g., two consultants for every token in Mixtral 8x7B), thus minimizing the quantity of computation accomplished for every token throughout coaching and inference. Additionally, the MoE mannequin treats solely the feed-forward layer as an knowledgeable whereas sharing the remainder of the parameters, making ‘Mistral 8x7B’ a 47 billion parameter mannequin, not the 56 billion implied by its title. Nevertheless, every token solely computes with about 13B parameters, also referred to as reside parameters. An equal 47B dense mannequin would require 94B (2*#params) FLOPs within the ahead move, whereas the Mixtral mannequin solely requires 26B (2 * #live_params) operations within the ahead move. This implies Mixtral’s inference can run as quick as a 13B mannequin, but with the standard of 47B and bigger dense fashions.
Whereas MoE fashions typically carry out fewer computations per token, the nuances of their inference efficiency are extra complicated. The effectivity positive aspects of MoE fashions in comparison with equivalently sized dense fashions differ relying on the dimensions of the information batches being processed, as illustrated within the determine beneath. For instance, when Mixtral inference is compute-bound at giant batch sizes we anticipate a ~3.6x speedup relative to a dense mannequin. In distinction, within the bandwidth-bound area at small batch sizes, the speedup shall be lower than this most ratio. Our earlier weblog submit delves into these ideas intimately, explaining how smaller batch sizes are usually bandwidth-bound, whereas bigger ones are compute-bound.
Easy and Manufacturing-Grade API for Mixtral 8x7B
Immediately entry Mixtral 8x7B with Basis Mannequin APIs
Databricks Mannequin Serving now gives on the spot entry to Mixtral 8x7B through Basis Mannequin APIs. Basis Mannequin APIs can be utilized on a pay-per-token foundation, drastically decreasing value and growing flexibility. As a result of Basis Mannequin APIs are served from inside Databricks infrastructure, your knowledge doesn’t have to transit to 3rd social gathering providers.
Basis Mannequin APIs additionally characteristic Provisioned Throughput for Mixtral 8x7B fashions to supply constant efficiency ensures and assist for fine-tuned fashions and excessive QPS visitors.
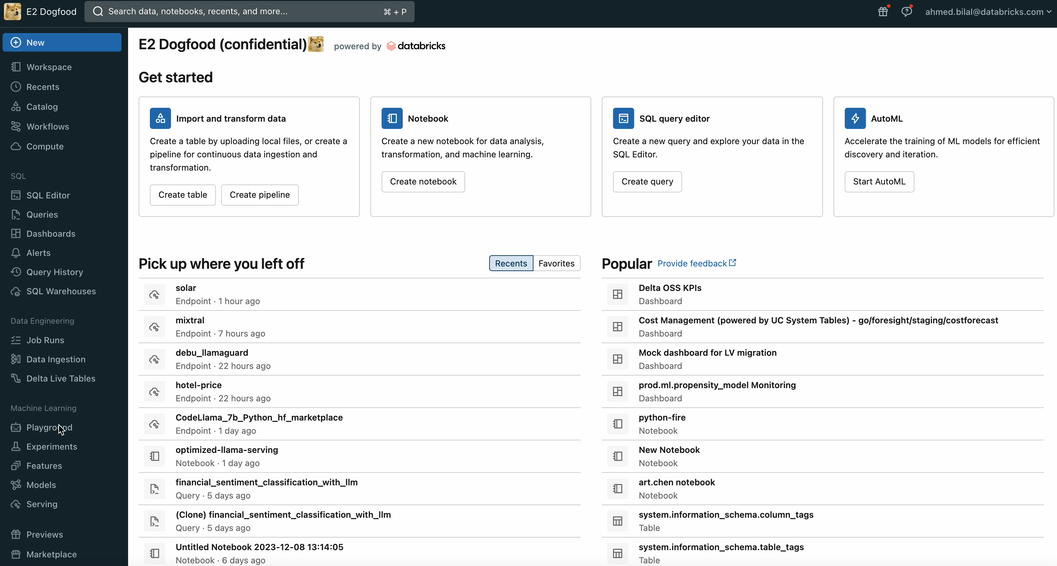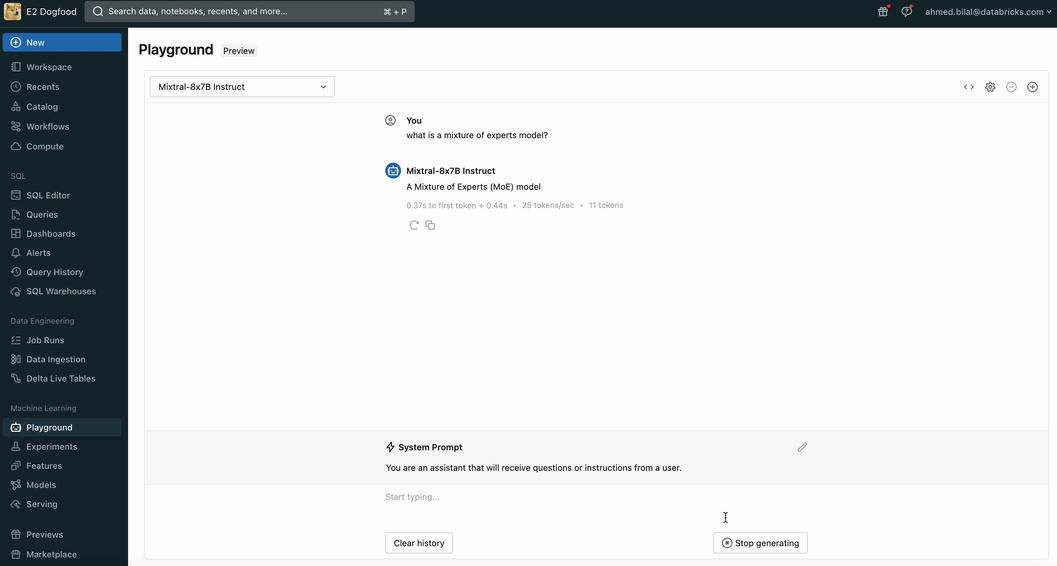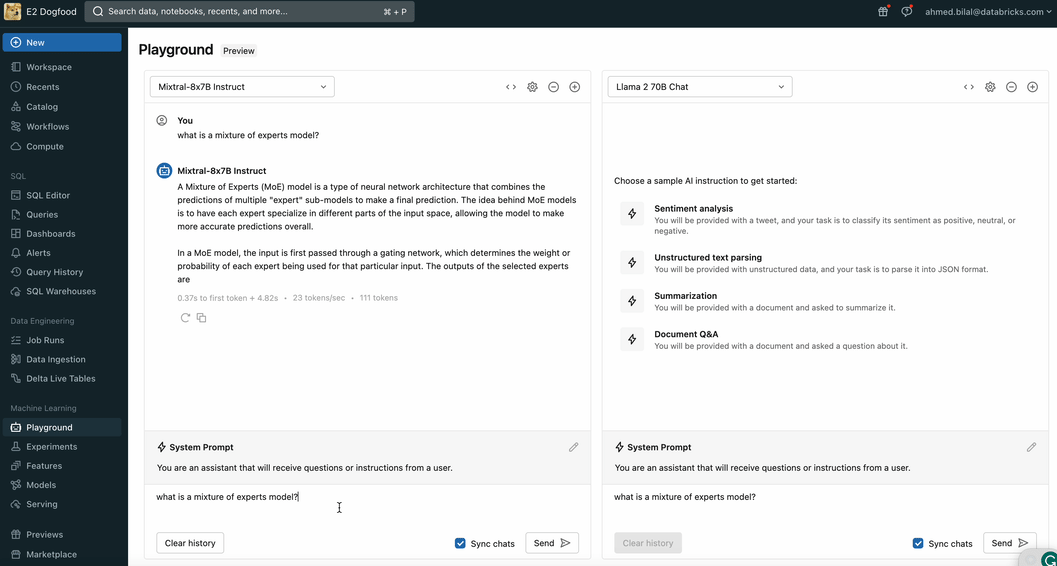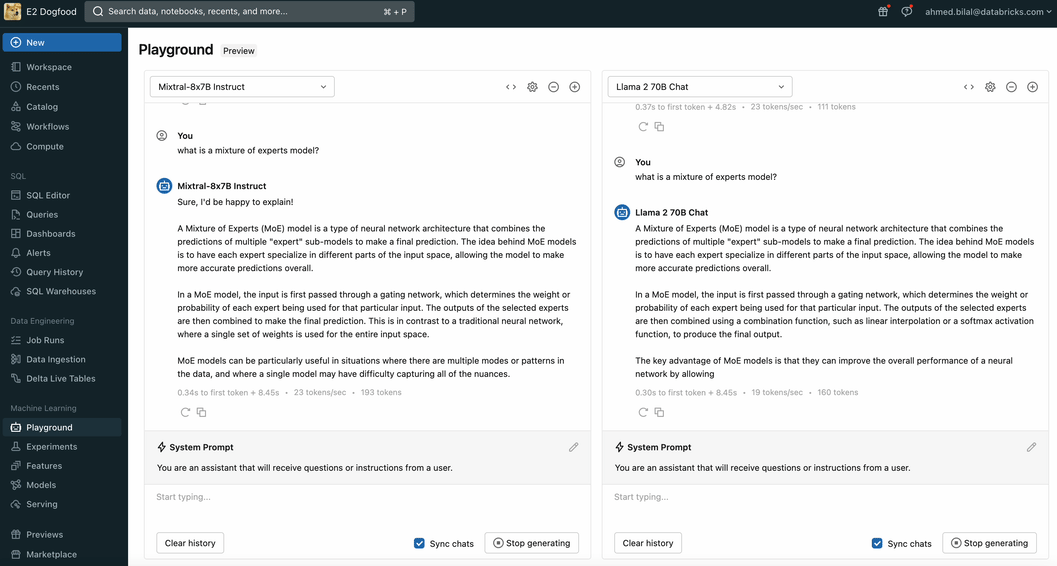
Simply evaluate and govern Mixtral 8x7B alongside different fashions
You may entry Mixtral 8x7B with the identical unified API and SDK that works with different Basis Fashions. This unified interface makes it potential to experiment, customise, and productionize basis fashions throughout all clouds and suppliers.
import mlflow.deployments
consumer = mlflow.deployments.get_deploy_client("databricks")
inputs = {
"messages": [
{
"role": "user",
"content": "List 3 reasons why you should train an AI model on domain specific data sets? No explanations required."
}
],
"max_tokens": 64,
"temperature": 0
}
response = consumer.predict(endpoint="databricks-mixtral-8x7b-instruct", inputs=inputs)
print(response["choices"][0]['message']['content'])You may also invoke mannequin inference immediately from SQL utilizing the `ai_query` SQL perform. To be taught extra, try the ai_query documentation.
SELECT ai_query(
'databricks-mixtral-8x7b-instruct',
'Describe Databricks SQL in 30 phrases.'
) AS chatAs a result of all of your fashions, whether or not hosted inside or outdoors Databricks, are in a single place, you’ll be able to centrally handle permissions, monitor utilization limits, and monitor the standard of all kinds of fashions. This makes it simple to learn from new mannequin releases with out incurring extra setup prices or overburdening your self with steady updates whereas making certain applicable guardrails can be found.
“Databricks’ Basis Mannequin APIs enable us to question state-of-the-art open fashions with the push of a button, letting us give attention to our clients reasonably than on wrangling compute. We’ve been utilizing a number of fashions on the platform and have been impressed with the soundness and reliability we’ve seen up to now, in addition to the assist we’ve obtained any time we’ve had a difficulty.” – Sidd Seethepalli, CTO & Founder, Vellum
Keep on the leading edge with Databricks’ dedication to delivering the most recent fashions with optimized efficiency
Databricks is devoted to making sure that you’ve got entry to the very best and newest open fashions with optimized inference. This strategy supplies the pliability to pick probably the most appropriate mannequin for every activity, making certain you keep on the forefront of rising developments within the ever-expanding spectrum of obtainable fashions. We’re actively working to additional enhance optimization to make sure you proceed to benefit from the lowest latency and diminished Whole Value of Possession (TCO). Keep tuned for extra updates on these developments, coming early subsequent yr.
“Databricks Mannequin Serving is accelerating our AI-driven tasks by making it simple to securely entry and handle a number of SaaS and open fashions, together with these hosted on or outdoors Databricks. Its centralized strategy simplifies safety and price administration, permitting our knowledge groups to focus extra on innovation and fewer on administrative overhead.” – Greg Rokita, AVP, Expertise at Edmunds.com
Getting began with Mixtral 8x7B on Databricks Mannequin Serving
Go to the Databricks AI Playground to shortly attempt generative AI fashions immediately out of your workspace. For extra info:
License
Mixtral 8x7B is licensed underneath Apache-2.0
[ad_2]