
[ad_1]
Microsoft Azure has delivered industry-leading outcomes for AI inference workloads amongst cloud service suppliers in the latest MLPerf Inference outcomes printed publicly by MLCommons. The Azure outcomes have been achieved utilizing the brand new NC H100 v5 sequence digital machines (VMs) powered by NVIDIA H100 NVL Tensor Core GPUs and strengthened the dedication from Azure to designing AI infrastructure that’s optimized for coaching and inferencing within the cloud.
The evolution of generative AI fashions
Fashions for generative AI are quickly increasing in dimension and complexity, reflecting a prevailing pattern within the {industry} towards ever-larger architectures. Trade-standard benchmarks and cloud-native workloads constantly push the boundaries, with fashions now reaching billions and even trillions of parameters. A first-rate instance of this pattern is the latest unveiling of Llama2, which boasts a staggering 70 billion parameters, marking it as MLPerf’s most vital take a look at of generative AI up to now (determine 1). This monumental leap in mannequin dimension is obvious when evaluating it to earlier {industry} requirements such because the Giant Language Mannequin GPT-J, which pales as compared with 10x fewer parameters. Such exponential development underscores the evolving calls for and ambitions throughout the AI {industry}, as prospects attempt to deal with more and more advanced duties and generate extra refined outputs.
Tailor-made particularly to handle the dense or generative inferencing wants that fashions like Llama 2 require, the Azure NC H100 v5 VMs marks a major leap ahead in efficiency for generative AI functions. Its purpose-driven design ensures optimized efficiency, making it an excellent alternative for organizations searching for to harness the ability of AI with reliability and effectivity. With the NC H100 v5-series, prospects can anticipate enhanced capabilities with these new requirements for his or her AI infrastructure, empowering them to deal with advanced duties with ease and effectivity.
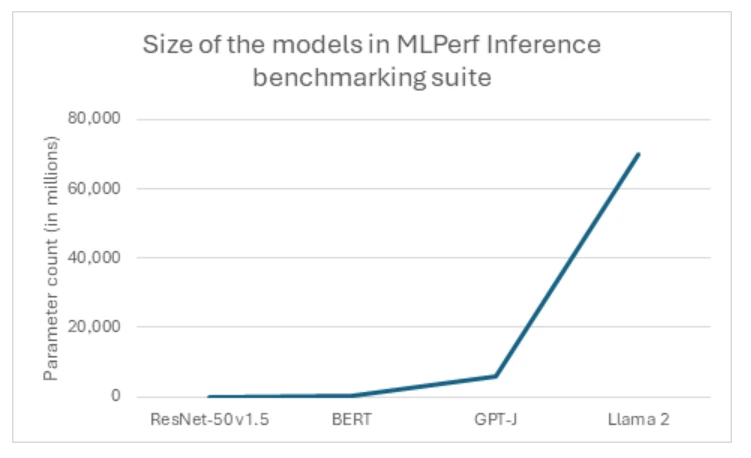
Nevertheless, the transition to bigger mannequin sizes necessitates a shift towards a unique class of {hardware} that’s able to accommodating the massive fashions on fewer GPUs. This paradigm shift presents a singular alternative for high-end programs, highlighting the capabilities of superior options just like the NC H100 v5 sequence. Because the {industry} continues to embrace the period of mega-models, the NC H100 v5 sequence stands prepared to fulfill the challenges of tomorrow’s AI workloads, providing unparalleled efficiency and scalability within the face of ever-expanding mannequin sizes.

Azure AI infrastucture
World-class infrastructure efficiency for AI workloads
Enhanced efficiency with purpose-built AI infrastructure
The NC H100 v5-series shines with purpose-built infrastructure, that includes a superior {hardware} configuration that yields exceptional efficiency features in comparison with its predecessors. Every GPU inside this sequence is provided with 94GB of HBM3 reminiscence. This substantial enhance in reminiscence capability and bandwidth interprets in a 17.5% enhance in reminiscence dimension and a 64% enhance in reminiscence bandwidth over the earlier generations. . Powered by NVIDIA H100 NVL PCIe GPUs and 4th-generation AMD EPYC™ Genoa processors, these digital machines characteristic as much as 2 GPUs, alongside as much as 96 non-multithreaded AMD EPYC Genoa processor cores and 640 GiB of system reminiscence.
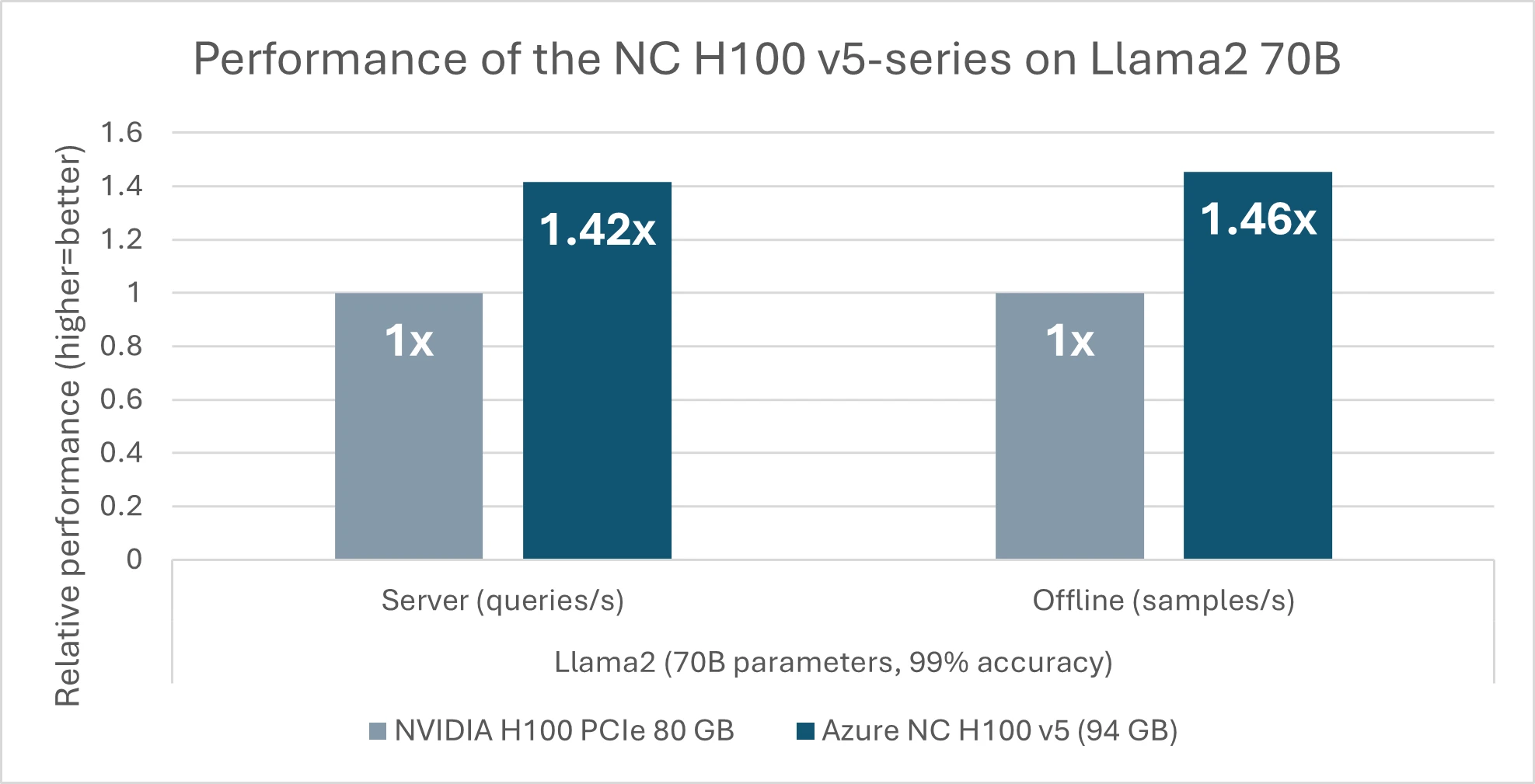
In immediately’s announcement from MLCommons, the NC H100 v5 sequence premiered efficiency ends in the MLPerf Inference v4.0 benchmark suite. Noteworthy amongst these achievements is a 46% efficiency acquire over competing merchandise geared up with GPUs of 80GB of reminiscence (determine 2), solely primarily based on the spectacular 17.5% enhance in reminiscence dimension (94 GB) of the NC H100 v5-series. This leap in efficiency is attributed to the sequence’ potential to suit the massive fashions into fewer GPUs effectively. For smaller fashions like GPT-J with 6 billion parameters, there’s a notable 1.6x speedup from the earlier era (NC A100 v4) to the brand new NC H100 v5. This enhancement is especially advantageous for patrons with dense Inferencing jobs, because it permits them to run a number of duties in parallel with better pace and effectivity whereas using fewer sources.
Efficiency delivering a aggressive edge
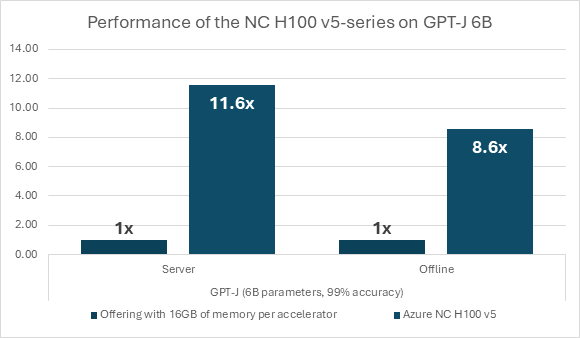
The rise in efficiency is essential not simply in comparison with earlier generations of comparable infrastructure options Within the MLPerf benchmarks outcomes, Azure’s NC H100 v5 sequence digital machines outcomes are standout in comparison with different cloud computing submissions made. Notably, when in comparison with cloud choices with smaller reminiscence capacities per accelerator, resembling these with 16GB reminiscence per accelerator, the NC H100 v5 sequence VMs exhibit a considerable efficiency enhance. With practically six occasions the reminiscence per accelerator, Azure’s purpose-built AI infrastructure sequence demonstrates a efficiency speedup of 8.6x to 11.6x (determine 3). This represents a efficiency enhance of fifty% to 100% for each byte of GPU reminiscence, showcasing the unparalleled capability of the NC H100 v5 sequence. These outcomes underscore the sequence’ capability to guide the efficiency requirements in cloud computing, providing organizations a strong answer to handle their evolving computational necessities.
In conclusion, the launch of the NC H100 v5 sequence marks a major milestone in Azure’s relentless pursuit of innovation in cloud computing. With its excellent efficiency, superior {hardware} capabilities, and seamless integration with Azure’s ecosystem, the NC H100 v5 sequence is revolutionizing the panorama of AI infrastructure, enabling organizations to completely leverage the potential of generative AI Inference workloads. The most recent MLPerf Inference v4.0 outcomes underscore the NC H100 v5 sequence’ unparalleled capability to excel in essentially the most demanding AI workloads, setting a brand new customary for efficiency within the {industry}. With its distinctive efficiency metrics and enhanced effectivity, the NC H100 v5 sequence reaffirms its place as a frontrunner within the realm of AI infrastructure, empowering organizations to unlock new prospects and obtain better success of their AI initiatives. Moreover, Microsoft’s dedication, as introduced throughout the NVIDIA GPU Expertise Convention (GTC), to proceed innovating by introducing much more highly effective GPUs to the cloud, such because the NVIDIA Grace Blackwell GB200 Tensor Core GPUs, additional enhances the prospects for advancing AI capabilities and driving transformative change within the cloud computing panorama.
Be taught extra about Azure generative AI
[ad_2]