
[ad_1]
As organizations are maturing their information infrastructure and accumulating extra information than ever earlier than of their information lakes, Open and Dependable desk codecs akin to Delta Lake turn out to be a vital necessity.
1000’s of firms are already utilizing Delta Lake in manufacturing, and open-sourcing all of Delta Lake (as introduced in June 2022) has additional elevated its adoption throughout numerous domains and verticals.
Since a lot of these firms are utilizing each Databricks and different information and AI frameworks (e.g., Energy BI, Trino, Flink, Spark on Kubernetes) as a part of their tech stack, it’s essential for them to have the ability to learn and write from/to Delta Lake utilizing all these frameworks.
The aim of this weblog submit is to assist these customers accomplish that, as seamlessly as attainable.
Integration Choices
Databricks supplies a number of choices to learn information from and write information to the lakehouse. These choices range from one another on numerous parameters. Every of those choices match completely different use circumstances.
The parameters we use to guage these choices are:
- Learn Solely/Learn Write – Does this selection present learn/write entry or learn solely.
- Upfront funding – Does this integration possibility require any customized growth or establishing one other element.
- Execution Overhead – Does this selection require a compute engine (cluster or SQL warehouse) between the info and the shopper software.
- Price – Does this selection entail any extra value (past the operational value of the storage and the shopper).
- Catalog – Does this selection present a catalog (akin to Hive Metastore) the shopper can use to browse for information property and retrieve metadata from.
- Entry to Storage – Does the shopper want direct community entry to the cloud storage.
- Scalability – Does this selection depend on scalable compute on the shopper or supplies compute for the shopper.
- Concurrent Write Help – Does this selection deal with concurrent writes, permitting write from a number of purchasers or from the shopper and Databricks on the similar time. (Docs)
Direct Cloud Storage Entry
Entry the recordsdata straight on the cloud storage. Exterior tables (AWS/Azure/GCP) in Databricks Unity Catalog (UC) might be accessed straight utilizing the trail of the desk. That requires the shopper to retailer the trail, have a networking path to the storage, and have permission to entry the storage straight.
a. Professionals
- No upfront funding (no scripting or tooling is required)
- No execution overhead
- No extra value
b. Cons
- No catalog – requires the developer to register and handle the placement
- No discovery capabilities
- Restricted Metadata (no Metadata for non delta tables)
- Requires entry to storage
- No governance capabilities
- No desk ACLs: Permission managed on the file/folder stage
- No audit
- Restricted concurrent write assist
- No inbuilt scalability – the studying software has to deal with scalability in case of enormous information units
c. Circulate:
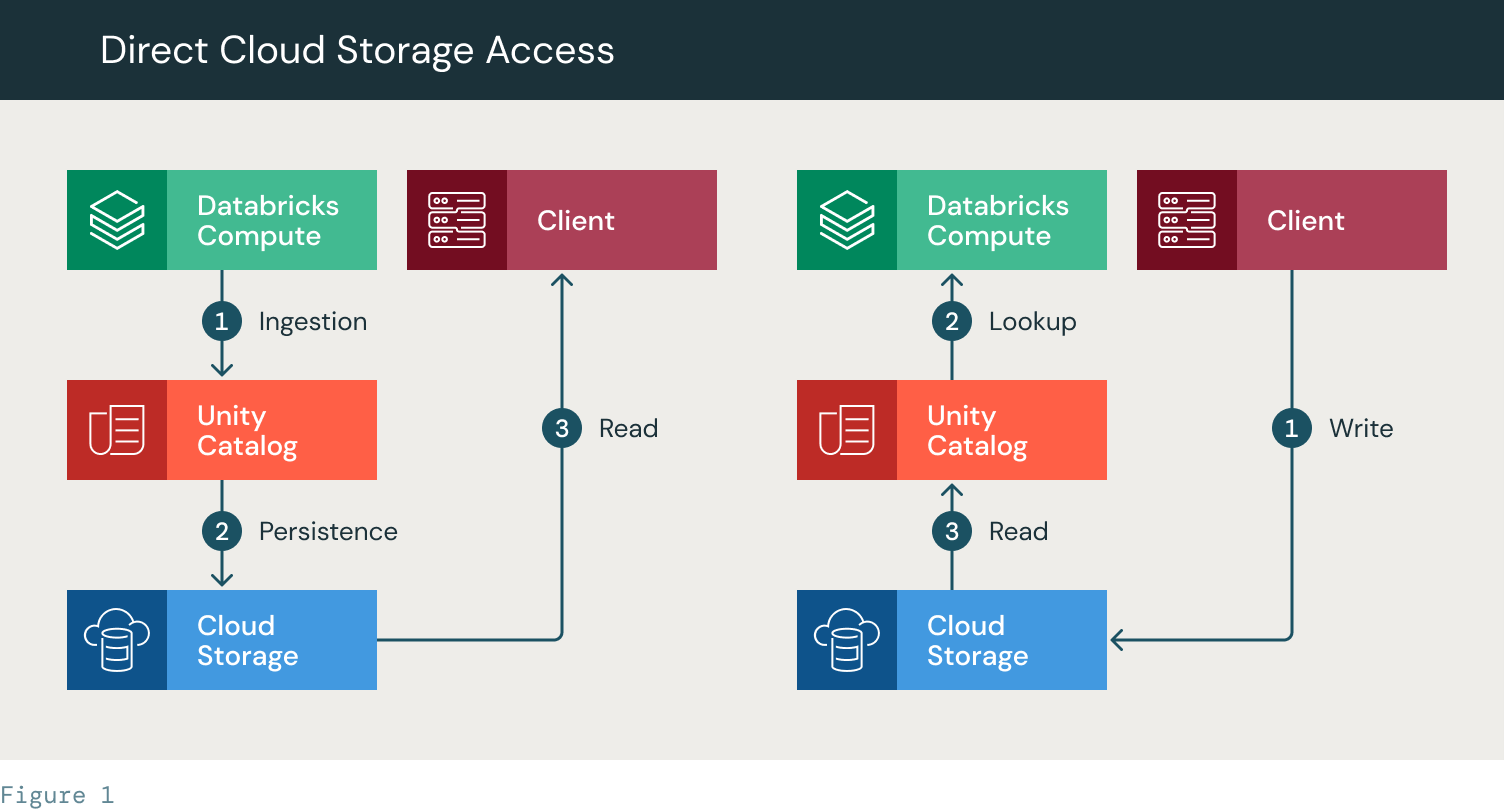
- Learn:
- Databricks carry out ingestion (1)
- It persists the file to a desk outlined in Unity Catalog. The info is continued to the cloud storage (2)
- The shopper is supplied with the trail to the desk. It makes use of its personal storage credentials (SPN/Occasion Profile) to entry the cloud storage on to learn the desk/recordsdata.
- Write:
- The shopper writes on to the cloud storage utilizing a path. The trail is then used to create a desk in UC. The desk is out there for learn operations in Databricks.
Exterior Hive Metastore (Bidirectional Sync)
On this state of affairs, we sync the metadata in Unity Catalog with an exterior Hive Metastore (HMS), akin to Glue, frequently. We preserve a number of databases in sync with the exterior listing. This can permit a shopper utilizing a Hive-supported reader to entry the desk. Equally to the earlier answer it requires the shopper to have direct entry to the storage.
a. Professionals
- Catalog supplies an inventory of the tables and manages the placement
- Discoverability permits the person to browse and discover tables
b. Cons
- Requires upfront setup
- Governance overhead – This answer requires redundant administration of entry. The UC depends on desk ACLs and Hive Metastore depends on storage entry permissions
- Requires a customized script to maintain the Hive Metastore metadata updated with the Unity Catalog metadata
- Restricted concurrent write assist
- No inbuilt scalability – the studying software has to deal with scalability in case of enormous information units
c. Circulate:
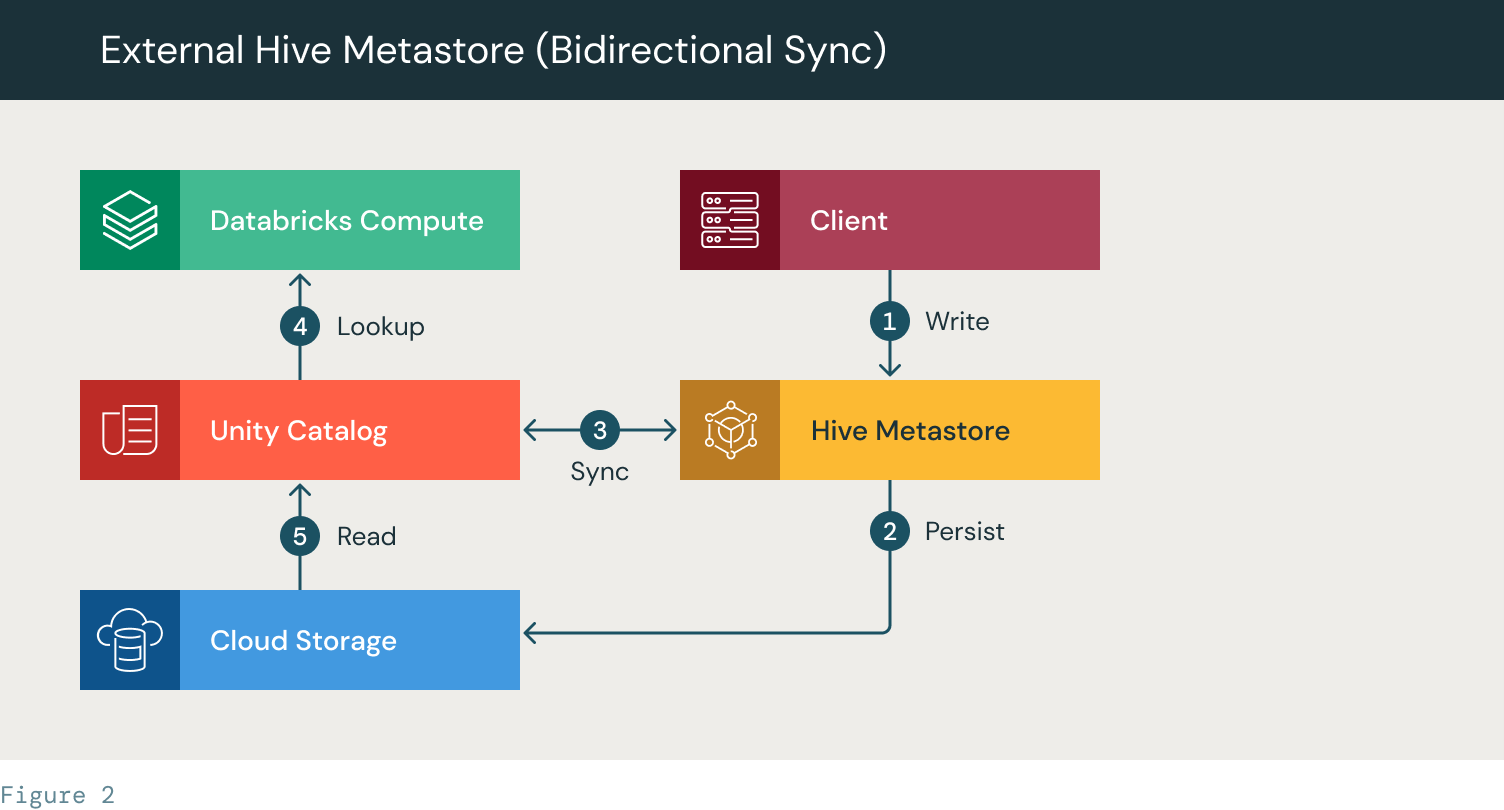
- The shopper creates a desk in HMS
- The desk is continued to the cloud storage
- A Sync script (customized script) syncs the desk metadata between HMS and Unity Catalog
- A Databricks cluster/SQL warehouse seems to be up the desk in UC
- The desk recordsdata are accessed utilizing UC from the cloud storage
Delta Sharing
Entry Delta tables through Delta Sharing (learn extra about Delta Sharing right here).
The info supplier creates a share for present Delta tables, and the info recipient can entry the info outlined throughout the share configuration. The Shared information is saved updated and helps actual time/close to actual time use circumstances together with streaming.
Typically talking, the info recipient connects to a Delta Sharing server, through a Delta Sharing shopper (that’s supported by a wide range of instruments). A Delta sharing shopper is any device that helps direct learn from a Delta Sharing supply. A signed URL is then supplied to the Delta Sharing shopper, and the shopper makes use of it to entry the Delta desk storage straight and browse solely the info they’re allowed to entry.
On the info supplier finish, this method removes the necessity to handle permissions on the storage stage and supplies sure audit capabilities (on the share stage).
On the info recipient finish, the info is consumed utilizing one of many aforementioned instruments, which suggests the recipient additionally must deal with the compute scalability on their very own (e.g., utilizing a Spark cluster).
a. Professionals
- Catalog + discoverability
- Doesn’t require permission to storage (performed on the share stage)
- Offers you audit capabilities (albeit restricted – it’s on the share stage)
b. Cons
- Learn-only
- It’s essential deal with scalability by yourself (e.g., use Spark)
i. Circulate:
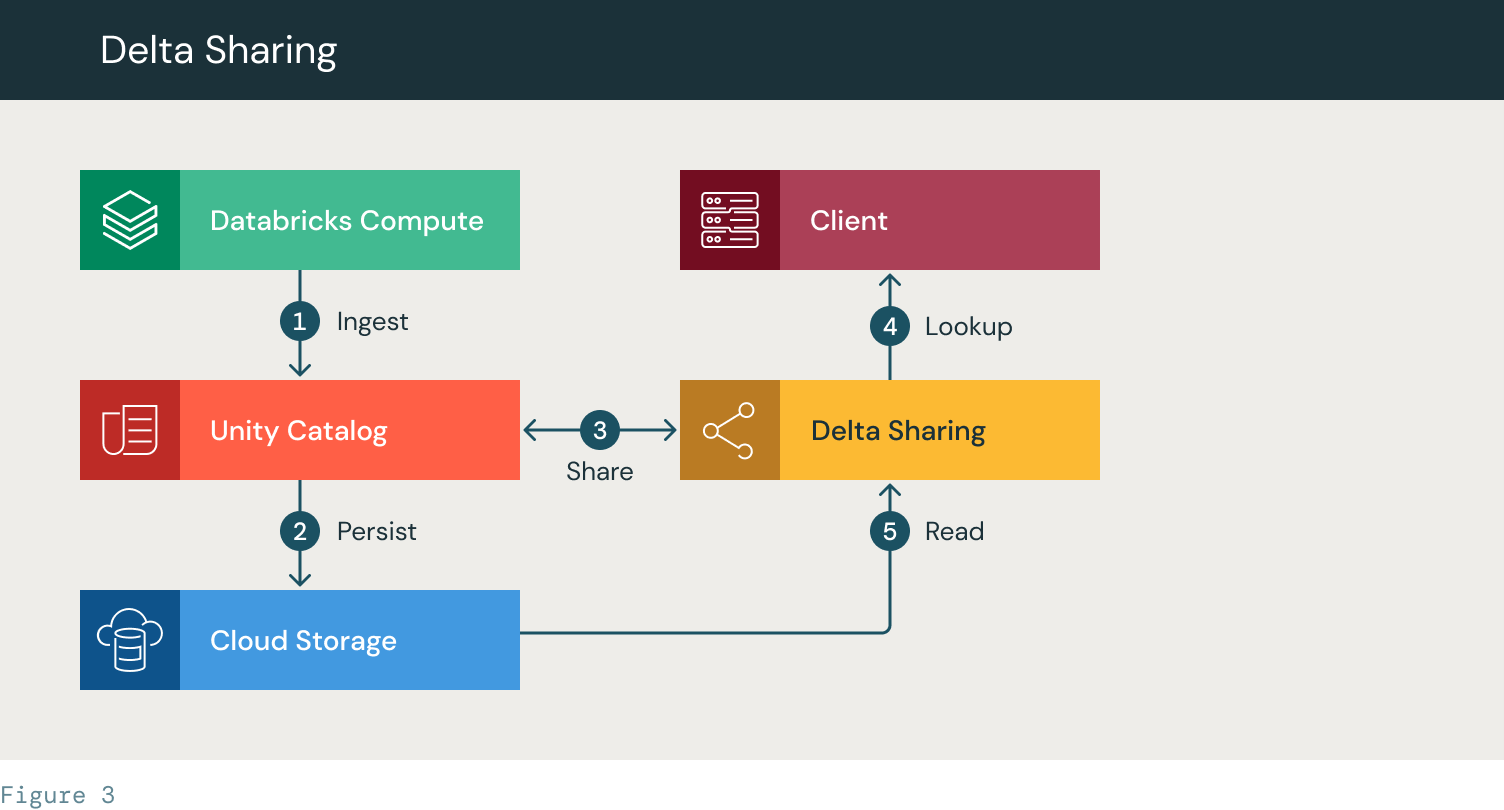
- Databricks ingests information and creates a UC desk
- The info is saved to the cloud storage
- A Delta Sharing supplier is created and the desk/database is shared. The entry token is supplied to the shopper
- The shopper accesses the Delta Sharing server and appears up the desk
- The Consumer is supplied entry to learn the desk recordsdata from the cloud storage
JDBC/ODBC connector (write/learn from wherever utilizing Databricks SQL)
The JDBC/ODBC connector lets you join your backend software, utilizing JDBC/ODBC, to a Databricks SQL warehouse (as described right here).
This basically isn’t any completely different than what you’d usually do when connecting backend functions to a database.
Databricks and a few third occasion builders present wrappers for the JDBC/ODBC connector that permit direct entry from numerous environments, together with:
This answer is appropriate for standalone purchasers, because the computing energy is the Databricks SQL warehouse (therefore the compute scalability is dealt with by Databricks).
Versus the Delta Sharing method, the JDBC/ODBC connector method additionally lets you write information to Delta tables (it even helps concurrent writes).
a. Professionals
- Scalability is dealt with by Databricks
- Full governance and audit
- Straightforward setup
- Concurrent write assist (Docs)
b. Cons
- Price
- Appropriate for standalone purchasers (much less for distributed execution engines like Spark)
l. Workflow:
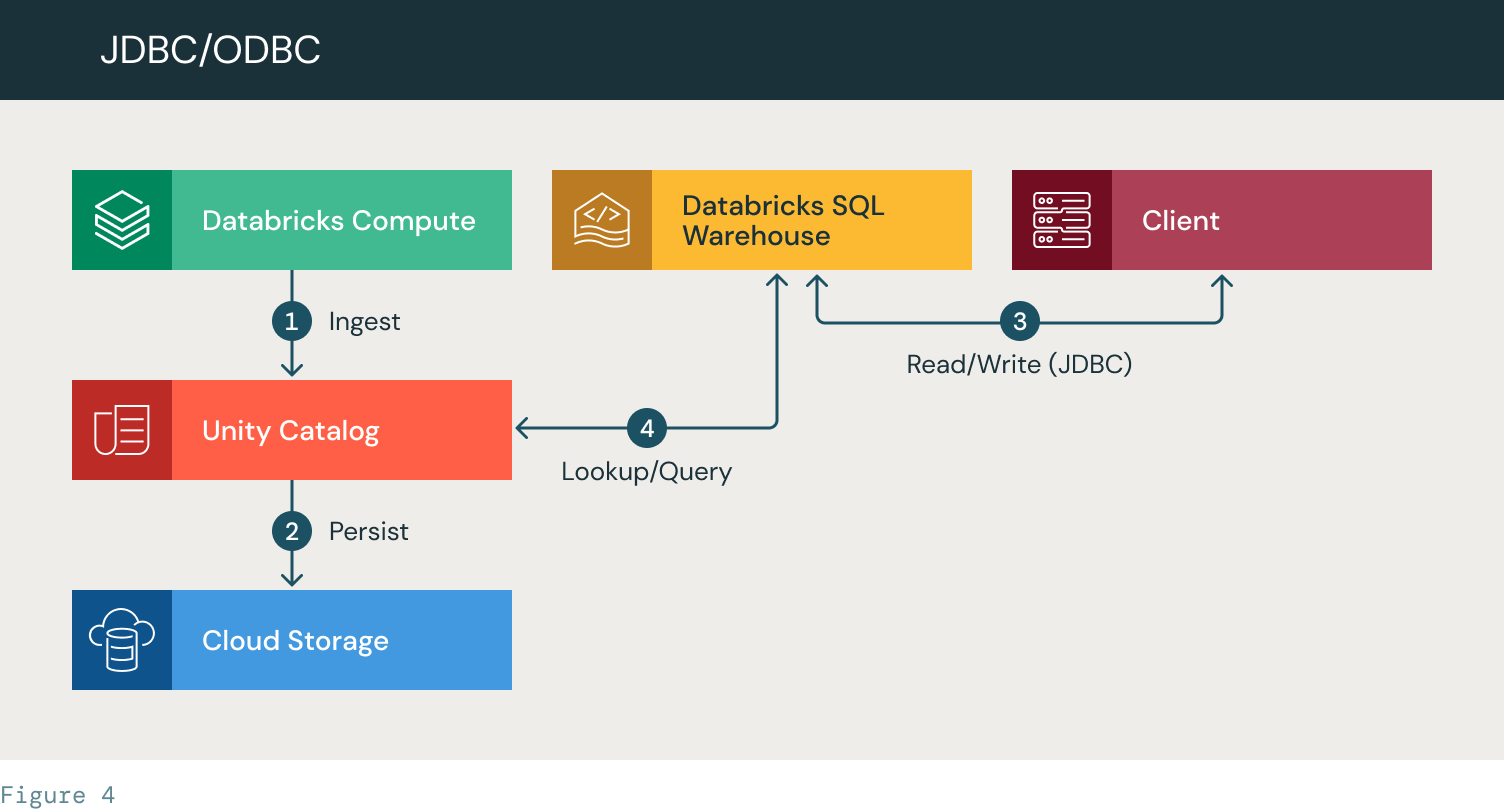
- Databricks ingests information and creates a UC desk
- The info is saved to the cloud storage
- The shopper makes use of a JDBC connection to authenticate and question a SQL warehouse
- The SQL warehouse seems to be up the info in Unity Catalog. It applies ACLs, accesses the info, performs the question and returns a outcome set to the shopper
c. Observe that when you have Unity Catalog enabled in your workspace, you additionally get full governance and audit of the operations. You possibly can nonetheless use the method described above with out Unity Catalog, however governance and auditing might be restricted.
d. That is the one possibility that helps row stage filtering and column filtering.
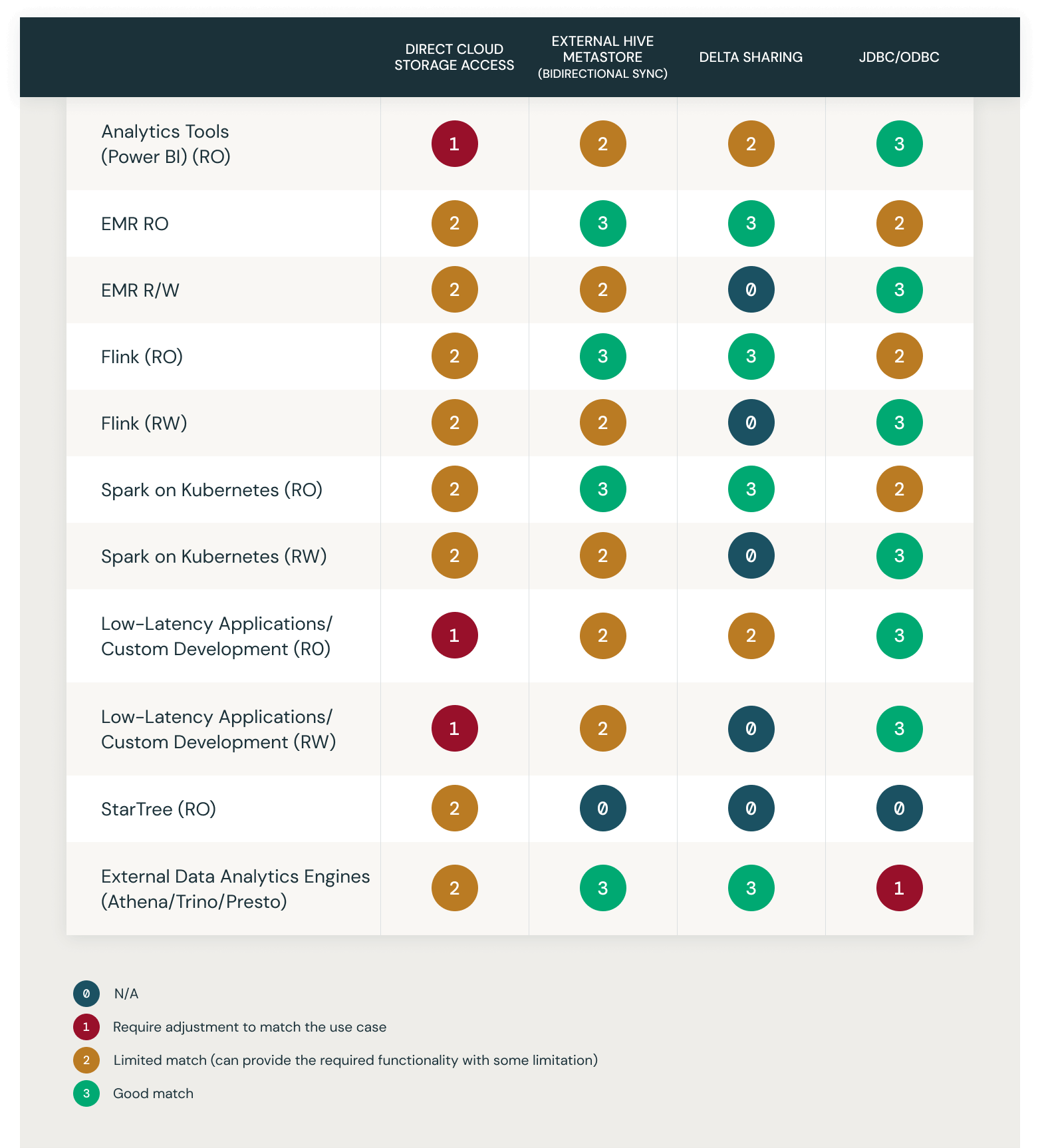
Integration choices and use-cases matrix
This chart demonstrates the match of the above described answer alternate options with a choose record of widespread use circumstances. They’re rated 0-4:
- 0 – N/A
- 1 – Require Adjustment to Match the use case
- 2 – Restricted Match (can present the required performance with some limitation)
- 3 – Good Match
Evaluate Documentation
https://docs.databricks.com/integrations/jdbc-odbc-bi.html
https://www.databricks.com/product/delta-sharing
https://docs.databricks.com/sql/language-manual/sql-ref-syntax-aux-sync.html
[ad_2]