
[ad_1]
In Databricks Runtime, Adaptive Question Execution (AQE) is a efficiency characteristic that constantly re-optimizes batch queries utilizing runtime statistics throughout question execution. Ranging from Databricks Runtime 13.1, real-time streaming queries that use the ForeachBatch Sink may even leverage AQE for dynamic re-optimizations as a part of Mission Lightspeed.
Limitations with Static Planning and Statistics
At Databricks, Structured Streaming handles petabytes of real-time knowledge every day. The ForeachBatch streaming sink, utilized by over 40% of shoppers, typically incorporates essentially the most resource-intensive operations, corresponding to joins and Delta MERGE with giant volumes of knowledge. The ensuing multi-staged execution plans have essentially the most potential to be re-optimized by AQE.
Streaming queries have relied on static question planning and estimated statistics, resulting in a number of identified points beforehand seen in batch queries, together with poor bodily technique selections and skewed knowledge distributions that degrade efficiency.
Software of Dynamic Optimizations
To deal with these challenges, we exploit the runtime statistics collected throughout the micro-batch execution of the ForeachBatch Sink for dynamic optimizations. Adaptive question replanning shall be triggered independently on every micro-batch as a result of the traits of the information might change over time throughout totally different micro-batches.
The impact of AQE is remoted on stateless operators and is utilized to the micro-batch DataFrame inside the ForeachBatch callable perform. Operators instantly utilized to the streaming DataFrame earlier than invoking ForeachBatch are executed in a distinct question plan with out AQE as a result of these operators could possibly be stateful. Separation of execution prevents AQE repartitioning on stateful operators, which might take away locality and trigger correctness points.
For Photon-enabled clusters, every micro-batch from a stateless question is executed with a cohesive question plan virtually similar to that of a batch Photon question. This design permits the widest vary of logical and bodily optimizations. AQE will take impact for many stateless Photon-enabled queries utilizing the ForeachBatch Sink.
Usually, AQE shall be best when transformations will be utilized inside the ForeachBatch Sink. The pattern code beneath reveals two semantically similar streaming queries. The second question is really useful for probably higher AQE protection because the be part of is moved contained in the ForeachBatch perform.
// EXAMPLE 1
val streamDf = spark.readStream...
val tableDf = spark.learn.desk("desk")
streamDf
.writeStream
.be part of(tableDf)
.the place("id > 10000")
.foreachBatch{ (batchDf: DataFrame, batchID: Lengthy) =>
batchDf
.withColumn(....)
.write
.format(...)
.mode(...)
.save(...)
}
.begin()
// EXAMPLE 2
val streamDf = spark.readStream...
val tableDf = spark.learn.desk("desk")
readDF
.writeStream
.foreachBatch{ (batchDf: DataFrame, batchID: Lengthy) =>
batchDf
.be part of(tableDf)
.the place("id > 10000")
.withColumn(....)
.write
.format(...)
.mode(...)
.save(...)
}
.begin()Interpretation of Question Plans with AQE
Contemplate a simplified instance of a streaming Delta MERGE question which is used for upserting real-time knowledge right into a Delta desk:
val readDf = spark.readStream... // Learn Streaming Supply
val stream = readDf
.writeStream
.foreachBatch((batchDF: DataFrame, batchID: Lengthy) => {
val deltaTable = DeltaTable.forPath(targetPath)
deltaTable.as("tgt")
.merge(batchDF.as("src"), "src.id = tgt.id")
.whenNotMatched()
.insertAll()
.whenMatched()
.updateAll()
.execute()
})
.begin()Scanning for matches is usually the most expensive a part of a Delta Merge question. Let’s study the Spark UI snippets of a question plan that executes the matching course of on a pattern micro-batch.
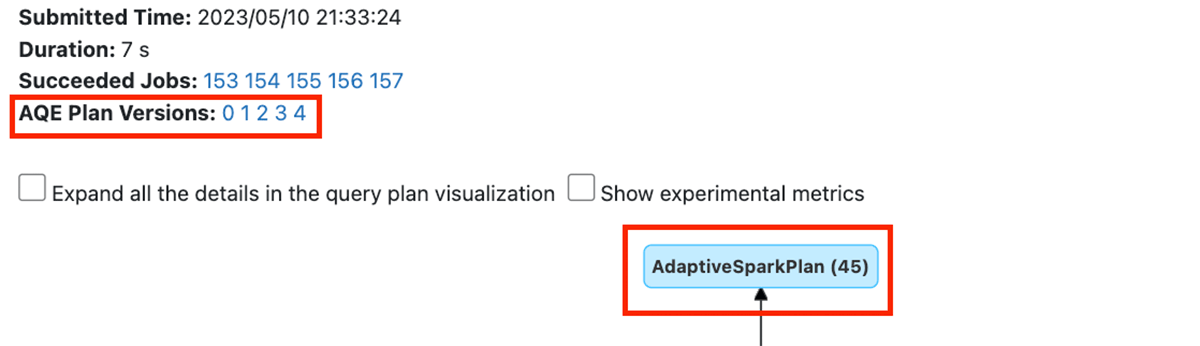
First, AQE Plan Variations include hyperlinks that present how the plan advanced throughout execution. The AdaptiveSparkPlan root node signifies that AQE was utilized to this question plan as a result of it contained no less than one shuffle.
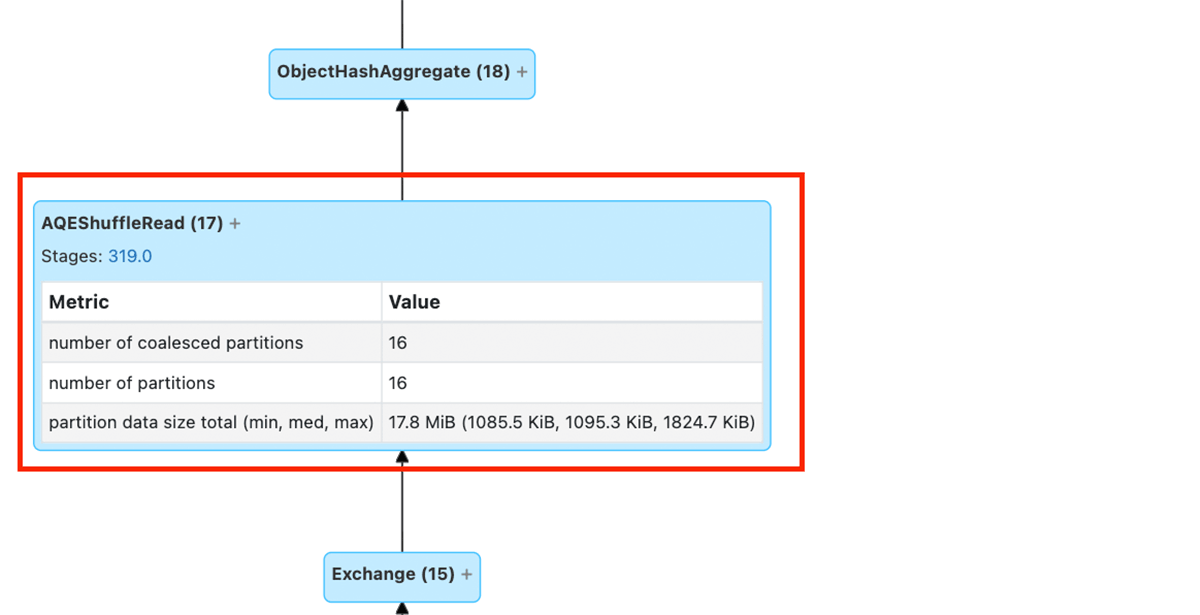
The snippet beneath reveals that AQE utilized dynamic coalescing of small partitions on this explicit instance.
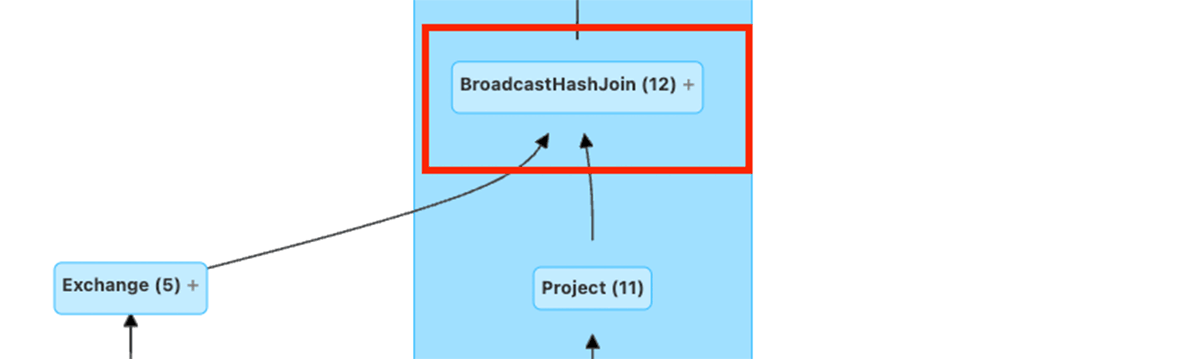
Evaluating plan variations on this instance additionally reveals that AQE dynamically switched from a SortMergeJoin to a BroadcastHashJoin, which might considerably pace up the be part of.
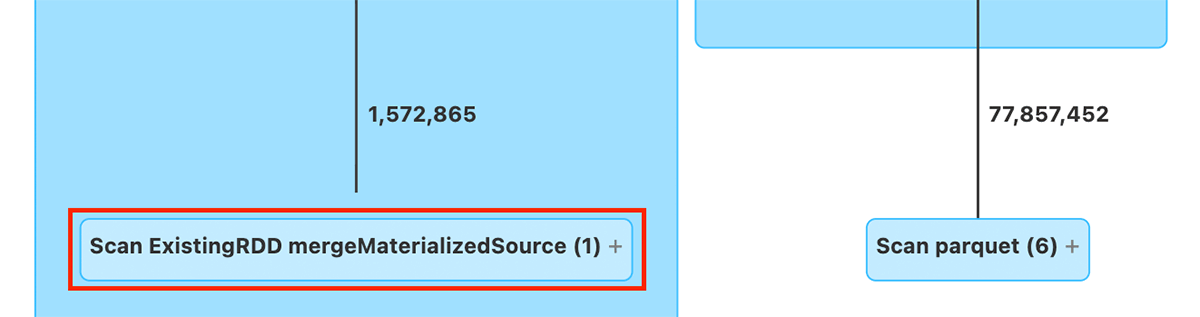
As proven beneath, one of many leaf nodes of the question plan is an RDD Scan which reads the materialized micro-batch knowledge from the streaming subplan which can include stateful operators.
If the identical question was executed in Photon, as an alternative of an RDD Scan, the execution plan would incorporate all downstream operators, together with the information stream supply.
Efficiency Outcomes
Leveraging AQE, stateless benchmark queries bottlenecked by costly joins and aggregations sometimes skilled a speedup starting from 1.2x to 2x, with one question that had notably poor static planning experiencing a 16x speedup. Partition dimension re-optimizations and dynamic be part of technique alternatives had been noticed within the speedup queries. As anticipated, AQE didn’t impression the efficiency for stateful queries and queries with few transformations.
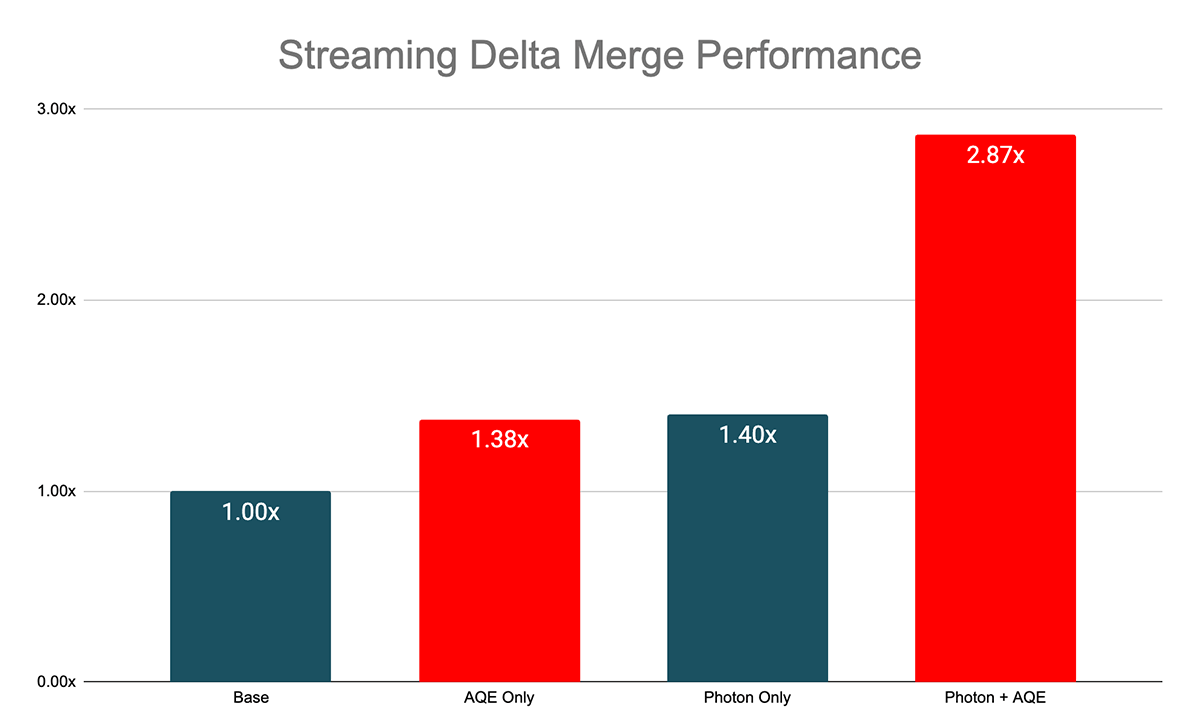
The extra dynamic filters enabled by AQE and be part of re-optimizations will be notably efficient with Delta MERGE, which is a standard streaming use case. As proven within the chart beneath, inside benchmarks demonstrated a median 1.38x speedup with simply AQE and 2.87x speedup if AQE is enabled together with the Photon engine.
Trying Ahead
AQE in streaming shall be enabled by default in Runtime 13.1 for non-Photon clusters and in Runtime 13.2 for Photon clusters. With AQE in ForeachBatch, prospects can now profit from the identical dynamic optimizations utilized in batch queries for his or her streaming workloads. Additionally, stay up for the approaching enhancements to AQE, together with Adaptive Be a part of Fallback and different AI-powered options enabled by AQE.
[ad_2]