
[ad_1]
Computerized speech recognition (ASR) is a well-established know-how that’s extensively adopted for numerous functions reminiscent of convention calls, streamed video transcription and voice instructions. Whereas the challenges for this know-how are centered round noisy audio inputs, the visible stream in multimodal movies (e.g., TV, on-line edited movies) can present sturdy cues for bettering the robustness of ASR programs — that is referred to as audiovisual ASR (AV-ASR).
Though lip movement can present sturdy indicators for speech recognition and is the commonest space of focus for AV-ASR, the mouth is commonly in a roundabout way seen in movies within the wild (e.g., attributable to selfish viewpoints, face coverings, and low decision) and due to this fact, a brand new rising space of analysis is unconstrained AV-ASR (e.g., AVATAR), which investigates the contribution of whole visible frames, and never simply the mouth area.
Constructing audiovisual datasets for coaching AV-ASR fashions, nevertheless, is difficult. Datasets reminiscent of How2 and VisSpeech have been created from educational movies on-line, however they’re small in measurement. In distinction, the fashions themselves are sometimes giant and encompass each visible and audio encoders, and they also are likely to overfit on these small datasets. Nonetheless, there have been various just lately launched large-scale audio-only fashions which are closely optimized by way of large-scale coaching on huge audio-only knowledge obtained from audio books, reminiscent of LibriLight and LibriSpeech. These fashions comprise billions of parameters, are available, and present sturdy generalization throughout domains.
With the above challenges in thoughts, in “AVFormer: Injecting Imaginative and prescient into Frozen Speech Fashions for Zero-Shot AV-ASR”, we current a easy technique for augmenting present large-scale audio-only fashions with visible data, on the identical time performing light-weight area adaptation. AVFormer injects visible embeddings right into a frozen ASR mannequin (much like how Flamingo injects visible data into giant language fashions for vision-text duties) utilizing light-weight trainable adaptors that may be skilled on a small quantity of weakly labeled video knowledge with minimal further coaching time and parameters. We additionally introduce a easy curriculum scheme throughout coaching, which we present is essential to allow the mannequin to collectively course of audio and visible data successfully. The ensuing AVFormer mannequin achieves state-of-the-art zero-shot efficiency on three totally different AV-ASR benchmarks (How2, VisSpeech and Ego4D), whereas additionally crucially preserving respectable efficiency on conventional audio-only speech recognition benchmarks (i.e., LibriSpeech).
 |
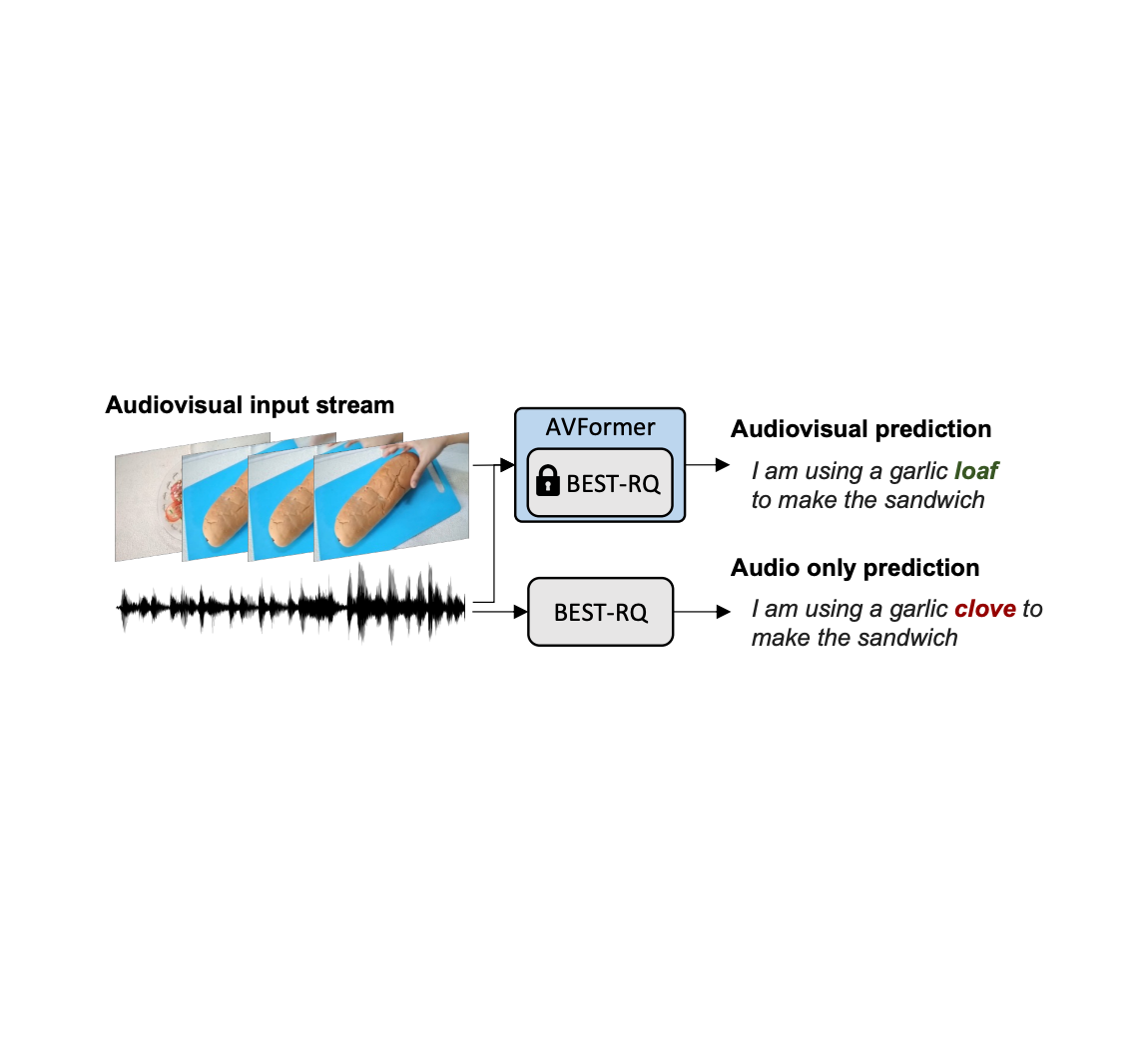
| Unconstrained audiovisual speech recognition. We inject imaginative and prescient right into a frozen speech mannequin (BEST-RQ, in gray) for zero-shot audiovisual ASR by way of light-weight modules to create a parameter- and data-efficient mannequin referred to as AVFormer (blue). The visible context can present useful clues for strong speech recognition particularly when the audio sign is noisy (the visible loaf of bread helps appropriate the audio-only mistake “clove” to “loaf” within the generated transcript). |
Injecting imaginative and prescient utilizing light-weight modules
Our purpose is so as to add visible understanding capabilities to an present audio-only ASR mannequin whereas sustaining its generalization efficiency to varied domains (each AV and audio-only domains).
To realize this, we increase an present state-of-the-art ASR mannequin (Greatest-RQ) with the next two parts: (i) linear visible projector and (ii) light-weight adapters. The previous tasks visible options within the audio token embedding house. This course of permits the mannequin to correctly join individually pre-trained visible function and audio enter token representations. The latter then minimally modifies the mannequin so as to add understanding of multimodal inputs from movies. We then practice these further modules on unlabeled net movies from the HowTo100M dataset, together with the outputs of an ASR mannequin as pseudo floor fact, whereas retaining the remainder of the Greatest-RQ mannequin frozen. Such light-weight modules allow data-efficiency and robust generalization of efficiency.
We evaluated our prolonged mannequin on AV-ASR benchmarks in a zero-shot setting, the place the mannequin is rarely skilled on a manually annotated AV-ASR dataset.
Curriculum studying for imaginative and prescient injection
After the preliminary analysis, we found empirically that with a naïve single spherical of joint coaching, the mannequin struggles to be taught each the adapters and the visible projectors in a single go. To mitigate this situation, we launched a two-phase curriculum studying technique that decouples these two elements — area adaptation and visible function integration — and trains the community in a sequential method. Within the first section, the adapter parameters are optimized with out feeding visible tokens in any respect. As soon as the adapters are skilled, we add the visible tokens and practice the visible projection layers alone within the second section whereas the skilled adapters are saved frozen.
The primary stage focuses on audio area adaptation. By the second section, the adapters are utterly frozen and the visible projector should merely be taught to generate visible prompts that venture the visible tokens into the audio house. On this means, our curriculum studying technique permits the mannequin to include visible inputs in addition to adapt to new audio domains in AV-ASR benchmarks. We apply every section simply as soon as, as an iterative software of alternating phases results in efficiency degradation.
 |
| General structure and coaching process for AVFormer. The structure consists of a frozen Conformer encoder-decoder mannequin, and a frozen CLIP encoder (frozen layers proven in grey with a lock image), along side two light-weight trainable modules – (i) visible projection layer (orange) and bottleneck adapters (blue) to allow multimodal area adaptation. We suggest a two-phase curriculum studying technique: the adapters (blue) are first skilled with none visible tokens, after which the visible projection layer (orange) is tuned whereas all the opposite elements are saved frozen. |
The plots under present that with out curriculum studying, our AV-ASR mannequin is worse than the audio-only baseline throughout all datasets, with the hole rising as extra visible tokens are added. In distinction, when the proposed two-phase curriculum is utilized, our AV-ASR mannequin performs considerably higher than the baseline audio-only mannequin.
 |
| Results of curriculum studying. Crimson and blue traces are for audiovisual fashions and are proven on 3 datasets within the zero-shot setting (decrease WER % is healthier). Utilizing the curriculum helps on all 3 datasets (for How2 (a) and Ego4D (c) it’s essential for outperforming audio-only efficiency). Efficiency improves up till 4 visible tokens, at which level it saturates. |
Ends in zero-shot AV-ASR
We examine AVFormer to BEST-RQ, the audio model of our mannequin, and AVATAR, the state-of-the-art in AV-ASR, for zero-shot efficiency on the three AV-ASR benchmarks: How2, VisSpeech and Ego4D. AVFormer outperforms AVATAR and BEST-RQ on all, even outperforming each AVATAR and BEST-RQ when they’re skilled on LibriSpeech and the total set of HowTo100M. That is notable as a result of for BEST-RQ, this entails coaching 600M parameters, whereas AVFormer solely trains 4M parameters and due to this fact requires solely a small fraction of the coaching dataset (5% of HowTo100M). Furthermore, we additionally consider efficiency on LibriSpeech, which is audio-only, and AVFormer outperforms each baselines.
.png) |
| Comparability to state-of-the-art strategies for zero-shot efficiency throughout totally different AV-ASR datasets. We additionally present performances on LibriSpeech which is audio-only. Outcomes are reported as WER % (decrease is healthier). AVATAR and BEST-RQ are finetuned end-to-end (all parameters) on HowTo100M whereas AVFormer works successfully even with 5% of the dataset because of the small set of finetuned parameters. |
Conclusion
We introduce AVFormer, a light-weight technique for adapting present, frozen state-of-the-art ASR fashions for AV-ASR. Our strategy is sensible and environment friendly, and achieves spectacular zero-shot efficiency. As ASR fashions get bigger and bigger, tuning your entire parameter set of pre-trained fashions turns into impractical (much more so for various domains). Our technique seamlessly permits each area switch and visible enter mixing in the identical, parameter environment friendly mannequin.
Acknowledgements
This analysis was performed by Paul Hongsuck Search engine marketing, Arsha Nagrani and Cordelia Schmid.
[ad_2]