
[ad_1]
Breaking Unhealthy… Knowledge Silos
We haven’t fairly found out how one can keep away from utilizing relational databases. Of us have positively tried, and whereas Apache Kafka® has develop into the usual for event-driven architectures, it nonetheless struggles to interchange your on a regular basis PostgreSQL database occasion within the trendy utility stack. No matter what the long run holds for databases, we have to remedy knowledge silo issues. To do that, Rockset has partnered with Confluent, the unique creators of Kafka who present the cloud-native knowledge streaming platform Confluent Cloud. Collectively, we’ve constructed an answer with fully-managed companies that unlocks relational database silos and supplies a real-time analytics surroundings for the trendy knowledge utility.
My first sensible publicity to databases was in a university course taught by Professor Karen Davis, now a professor at Miami College in Oxford, Ohio. Our senior mission, primarily based on the LAMP stack (Perl in our case) and sponsored with an NFS grant, put me on a path that unsurprisingly led me to the place I’m at present. Since then, databases have been a significant a part of my skilled life and trendy, on a regular basis life for most people.
Within the curiosity of full disclosure, it’s value mentioning that I’m a former Confluent worker, now working at Rockset. At Confluent I talked typically in regards to the fanciful sounding “Stream and Desk Duality”. It’s an concept that describes how a desk can generate a stream and a stream may be reworked right into a desk. The connection is described on this order, with tables first, as a result of that’s typically how most people question their knowledge. Nevertheless, even inside the database itself, all the pieces begins as an occasion in a log. Typically this takes the type of a transaction log or journal, however whatever the implementation, most databases internally retailer a stream of occasions and remodel them right into a desk.
If your organization solely has one database, you’ll be able to most likely cease studying now; knowledge silos aren’t your downside. For everybody else, it’s necessary to have the ability to get knowledge from one database to a different. The merchandise and instruments to perform this activity make up an virtually $12 billion greenback market, they usually basically all do the identical factor in several methods. The idea of Change Knowledge Seize (CDC) has been round for some time however particular options have taken many shapes. The latest of those, and probably essentially the most attention-grabbing, is real-time CDC enabled by the identical inner database logging techniques used to construct tables. Every thing else, together with query-based CDC, file diffs, and full desk overwrites is suboptimal by way of knowledge freshness and native database impression. For this reason Oracle acquired the extremely popular GoldenGate software program firm in 2009 and the core product continues to be used at present for real-time CDC on a wide range of supply techniques. To be a real-time CDC stream we must be occasion pushed; something much less is batch and modifications our resolution capabilities.
Actual-Time CDC Is The Approach
Hopefully now you’re curious how Rockset and Confluent aid you break down knowledge silos utilizing real-time CDC. As you’ll anticipate, it begins along with your database of alternative, though ideally one which helps a transaction log that can be utilized to generate real-time CDC occasions. PostgreSQL, MySQL, SQL Server, and even Oracle are standard selections, however there are various others that can work high quality. For our tutorial we’ll give attention to PostgreSQL, however the ideas will probably be comparable whatever the database.
Subsequent, we want a software to generate CDC occasions in actual time from PostgreSQL. There are just a few choices and, as you could have guessed, Confluent Cloud has a built-in and totally managed PostgreSQL CDC supply connector primarily based on Debezium’s open-source connector. This connector is particularly designed to observe row-level modifications after an preliminary snapshot and write the output to Confluent Cloud subjects. Capturing occasions this manner is each handy and offers you a production-quality knowledge stream with built-in help and availability.
Confluent Cloud can also be an ideal alternative for storing real-time CDC occasions. Whereas there are a number of advantages to utilizing Confluent Cloud, a very powerful is the discount in operational burden. With out Confluent Cloud, you’ll be spending weeks getting a Kafka cluster stood up, months understanding and implementing correct safety after which dedicating a number of of us to sustaining it indefinitely. With Confluent Cloud, you’ll be able to have all of that in a matter of minutes with a bank card and an online browser. You’ll be able to study extra about Confluent vs. Kafka over on Confluent’s website.
Final, however certainly not least, Rockset will probably be configured to learn from Confluent Cloud subjects and course of CDC occasions into a set that appears very very like our supply desk. Rockset brings three key options to the desk in relation to dealing with CDC occasions.
- Rockset integrates with a number of sources as a part of the managed service (together with DynamoDB and MongoDB). Much like Confluent’s managed PostgreSQL CDC connector, Rockset has a managed integration with Confluent Cloud. With a fundamental understanding of your supply mannequin, like the first key for every desk, you could have all the pieces it is advisable course of these occasions.
- Rockset additionally makes use of a schemaless ingestion mannequin that enables knowledge to evolve with out breaking something. If you’re within the particulars, we’ve been schemaless since 2019 as blogged about right here. That is essential for CDC knowledge as new attributes are inevitable and also you don’t need to spend time updating your pipeline or suspending utility modifications.
- Rockset’s Converged Index™ is totally mutable, which provides Rockset the flexibility to deal with modifications to current information in the identical means the supply database would, normally an upsert or delete operation. This provides Rockset a singular benefit over different extremely listed techniques that require heavy lifting to make any modifications, usually involving vital reprocessing and reindexing steps.
Databases and knowledge warehouses with out these options typically have elongated ETL or ELT pipelines that improve knowledge latency and complexity. Rockset usually maps 1 to 1 between supply and goal objects with little or no want for advanced transformations. I’ve at all times believed that in case you can draw the structure you’ll be able to construct it. The design drawing for this structure is each elegant and easy. Under you’ll discover the design for this tutorial, which is totally manufacturing prepared. I’m going to interrupt the tutorial up into two essential sections: organising Confluent Cloud and organising Rockset.

Streaming Issues With Confluent Cloud
Step one in our tutorial is configuring Confluent Cloud to seize our change knowledge from PostgreSQL. When you don’t have already got an account, getting began with Confluent is free and straightforward. Moreover, Confluent already has a properly documented tutorial for organising the PostgreSQL CDC connector in Confluent Cloud. There are just a few notable configuration particulars to spotlight:
- Rockset can course of occasions whether or not “after.state.solely” is ready to “true” or “false”. For our functions, the rest of the tutorial will assume it’s “true”, which is the default.
- ”output.knowledge.format” must be set to both “JSON” or “AVRO”. Presently Rockset doesn’t help “PROTOBUF” or “JSON_SR”. If you’re not certain to utilizing Schema Registry and also you’re simply setting this up for Rockset, “JSON” is the simplest method.
- Set “Tombstones on delete” to “false”, this may cut back noise as we solely want the only delete occasion to correctly delete in Rockset.
-
I additionally needed to set the desk’s reproduction identification to “full” to ensure that delete to work as anticipated, however this may be configured already in your database.
ALTER TABLE cdc.demo.occasions REPLICA IDENTITY FULL; - In case you have tables with high-frequency modifications, contemplate dedicating a single connector to them since “duties.max” is proscribed to 1 per connector. The connector, by default, screens all non-system tables, so be certain to make use of “desk.includelist” if you would like a subset per connector.
There are different settings which may be necessary to your surroundings however shouldn’t have an effect on the interplay between Rockset and Confluent Cloud. When you do run into points between PostgreSQL and Confluent Cloud, it’s probably both a niche within the logging setup on PostgreSQL, permissions on both system, or networking. Whereas it’s tough to troubleshoot by way of weblog, my finest advice is to overview the documentation and speak to Confluent help. In case you have accomplished all the pieces right up so far, it’s best to see knowledge like this in Confluent Cloud:

Actual Time With Rockset
Now that PostgreSQL CDC occasions are flowing by means of Confluent Cloud, it’s time to configure Rockset to devour and course of these occasions. The excellent news is that it’s simply as simple to arrange an integration to Confluent Cloud because it was to arrange the PostgreSQL CDC connector. Begin by making a Rockset integration to Confluent Cloud utilizing the console. This may also be accomplished programmatically utilizing our REST API or Terraform supplier, however these examples are much less visually gorgeous.
Step 1. Add a brand new integration.

Step 2. Choose the Confluent Cloud tile within the catalog.

Step 3. Fill out the configuration fields (together with Schema Registry if utilizing Avro).

Step 4. Create a brand new assortment from this integration.

Step 5. Fill out the info supply configuration.
- Subject identify
- Beginning offset (suggest earliest if the subject is comparatively small or static)
- Knowledge Format (ours will probably be JSON)
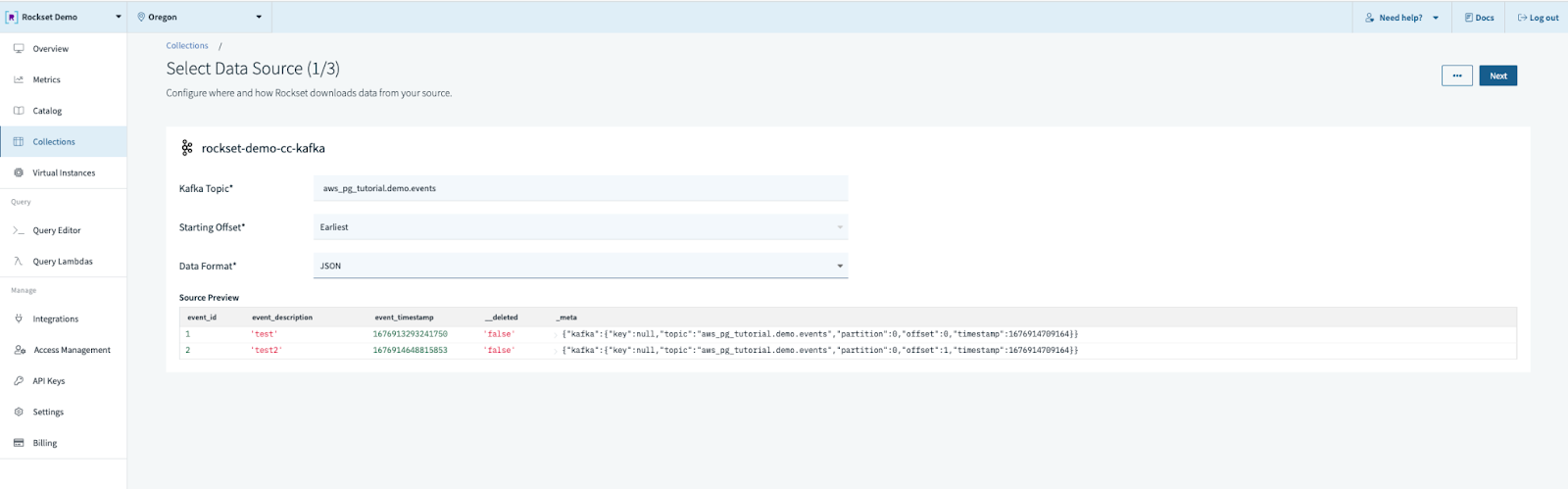

Step 6. Select the “Debezium” template in “CDC codecs” and choose “major key”. The default Debezium template assumes we now have each a earlier than and after picture. In our case we don’t, so the precise SQL transformation will probably be just like this:
SELECT
IF(enter.__deleted = 'true', 'DELETE', 'UPSERT') AS _op,
CAST(_input.event_id AS string) AS _id,
TIMESTAMP_MICROS(CAST(_input.event_timestamp as int)) as event_timestamp,
_input.* EXCEPT(event_id, event_timestamp, __deleted)
FROM _input
Rockset has template help for a lot of frequent CDC occasions, and we even have specialised _op codes for “_op” to fit your wants. In our instance we’re solely involved with deletes; we deal with all the pieces else as an upsert.

Step 7. Fill out the workspace, identify, and outline, and select a retention coverage. For this model of CDC materialization we must always set the retention coverage to “Hold all paperwork”.

As soon as the gathering state says “Prepared” you can begin operating queries. In just some minutes you could have arrange a set which mimics your PostgreSQL desk, robotically stays up to date with simply 1-2 seconds of knowledge latency, and is ready to run millisecond-latency queries.
Talking of queries, you too can flip your question right into a Question Lambda, which is a managed question service. Merely write your question within the question editor, put it aside as a Question Lambda, and now you’ll be able to run that question by way of a REST endpoint managed by Rockset. We’ll monitor modifications to the question over time utilizing variations, and even report on metrics for each frequency and latency over time. It’s a option to flip your data-as-a-service mindset right into a query-as-a-service mindset with out the burden of constructing out your individual SQL technology and API layer.

The Superb Database Race
As an beginner herpetologist and common fan of biology, I discover expertise follows an identical technique of evolution by means of pure choice. After all, within the case of issues like databases, the “pure” half can typically appear a bit “unnatural”. Early databases had been strict by way of format and construction however fairly predictable by way of efficiency. Later, in the course of the Huge Knowledge craze, we relaxed the construction and spawned a department of NoSQL databases identified for his or her loosey-goosey method to knowledge fashions and lackluster efficiency. Right now, many corporations have embraced real-time resolution making as a core enterprise technique and are on the lookout for one thing that mixes each efficiency and adaptability to energy their actual time resolution making ecosystem.
Fortuitously, just like the fish with legs that may ultimately develop into an amphibian, Rockset and Confluent have risen from the ocean of batch and onto the land of actual time. Rockset’s potential to deal with excessive frequency ingestion, a wide range of knowledge fashions, and interactive question workloads makes it distinctive, the primary in a brand new species of databases that can develop into ever extra frequent. Confluent has develop into the enterprise normal for real-time knowledge streaming with Kafka and event-driven architectures. Collectively, they supply a real-time CDC analytics pipeline that requires zero code and nil infrastructure to handle. This lets you give attention to the purposes and companies that drive your small business and rapidly derive worth out of your knowledge.
You may get began at present with a free trial for each Confluent Cloud and Rockset. New Confluent Cloud signups obtain $400 to spend throughout their first 30 days — no bank card required. Rockset has an identical deal – $300 in credit score and no bank card required.
[ad_2]