
[ad_1]
This weblog publish is co-written with Ori Nakar from Imperva.
Imperva Cloud WAF protects lots of of 1000’s of internet sites and blocks billions of safety occasions day-after-day. Occasions and lots of different safety knowledge sorts are saved in Imperva’s Menace Analysis Multi-Area knowledge lake.
Imperva harnesses knowledge to enhance their enterprise outcomes. To allow this transformation to a data-driven group, Imperva brings collectively knowledge from structured, semi-structured, and unstructured sources into a knowledge lake. As a part of their answer, they’re utilizing Amazon QuickSight to unlock insights from their knowledge.
Imperva’s knowledge lake is predicated on Amazon Easy Storage Service (Amazon S3), the place knowledge is regularly loaded. Imperva’s knowledge lake has a couple of dozen totally different datasets, within the scale of petabytes. Every day, TBs of latest knowledge is added to the information lake, which is then reworked, aggregated, partitioned, and compressed.
On this publish, we clarify how Imperva’s answer allows customers throughout the group to discover, visualize, and analyze knowledge utilizing Amazon Redshift Serverless, Amazon Athena, and QuickSight.
Challenges and desires
A contemporary knowledge technique provides you a complete plan to handle, entry, analyze, and act on knowledge. AWS offers essentially the most full set of companies for all the end-to-end knowledge journey for all workloads, all sorts of knowledge, and all desired enterprise outcomes. In flip, this makes AWS one of the best place to unlock worth out of your knowledge and switch it into perception.
Redshift Serverless is a serverless possibility of Amazon Redshift that lets you run and scale analytics with out having to provision and handle knowledge warehouse clusters. Redshift Serverless robotically provisions and intelligently scales knowledge warehouse capability to ship excessive efficiency for all of your analytics. You simply must load and question your knowledge, and also you solely pay for the compute used at some point of the workloads on a per-second foundation. Redshift Serverless is right when it’s tough to foretell compute wants similar to variable workloads, periodic workloads with idle time, and steady-state workloads with spikes.
Athena is an interactive question service that makes it simple to investigate knowledge in Amazon S3 utilizing normal SQL. Athena is serverless, simple to make use of, and makes it easy for anybody with SQL expertise to rapidly analyze large-scale datasets in a number of Areas.
QuickSight is a cloud-native enterprise intelligence (BI) service that you should utilize to visually analyze knowledge and share interactive dashboards with all customers within the group. QuickSight is totally managed and serverless, requires no consumer downloads for dashboard creation, and has a pay-per-session pricing mannequin that lets you pay for dashboard consumption. Imperva makes use of QuickSight to allow customers with no technical experience, from totally different groups similar to advertising, product, gross sales, and others, to extract perception from the information with out the assistance of knowledge or analysis groups.
QuickSight provides SPICE, an in-memory, cloud-native knowledge retailer that permits end-users to interactively discover knowledge. SPICE offers constantly quick question efficiency and robotically scales for prime concurrency. With SPICE, you save time and value since you don’t must retrieve knowledge from the information supply (whether or not a database or knowledge warehouse) each time you modify an evaluation or replace a visible, and also you take away the load of concurrent entry or analytical complexity off the underlying knowledge supply with the information.
To ensure that QuickSight to devour knowledge from the information lake, among the knowledge undergoes extra transformations, filters, joins, and aggregations. Imperva cleans their knowledge by filtering incomplete data, decreasing the variety of data by aggregations, and making use of inner logic to curate hundreds of thousands of safety incidents out of lots of of hundreds of thousands of data.
Imperva had the next necessities for his or her answer:
- Excessive efficiency with low question latency to allow interactive dashboards
- Repeatedly replace and append knowledge to queryable sources from the information lake
- Information freshness of as much as 1 day
- Low price
- Engineering effectivity
The problem confronted by Imperva and lots of different firms is the way to create an enormous knowledge extract, rework, and cargo (ETL) pipeline answer that matches these necessities.
On this publish, we evaluation two approaches Imperva applied to deal with their challenges and meet their necessities. The options could be simply applied whereas sustaining engineering effectivity, particularly with the introduction of Redshift Serverless.
Imperva’s options
Imperva wanted to have the information lake’s knowledge obtainable by way of QuickSight repeatedly. The next options have been chosen to attach the information lake to QuickSight:
- QuickSight caching layer, SPICE – Use Athena to question the information right into a QuickSight SPICE dataset
- Redshift Serverless – Copy the information to Redshift Serverless and use it as a knowledge supply
Our advice is to make use of an answer based mostly on the use case. Every answer has its personal benefits and challenges, which we talk about as a part of this publish.
The high-level movement is the next:
- Information is repeatedly up to date from the information lake into both Redshift Serverless or the QuickSight caching layer, SPICE
- An inner person can create an evaluation and publish it as a dashboard for different inner or exterior customers
The next structure diagram exhibits the high-level movement.

Within the following sections, we talk about the main points concerning the movement and the totally different options, together with a comparability between them, which can assist you select the fitting answer for you.
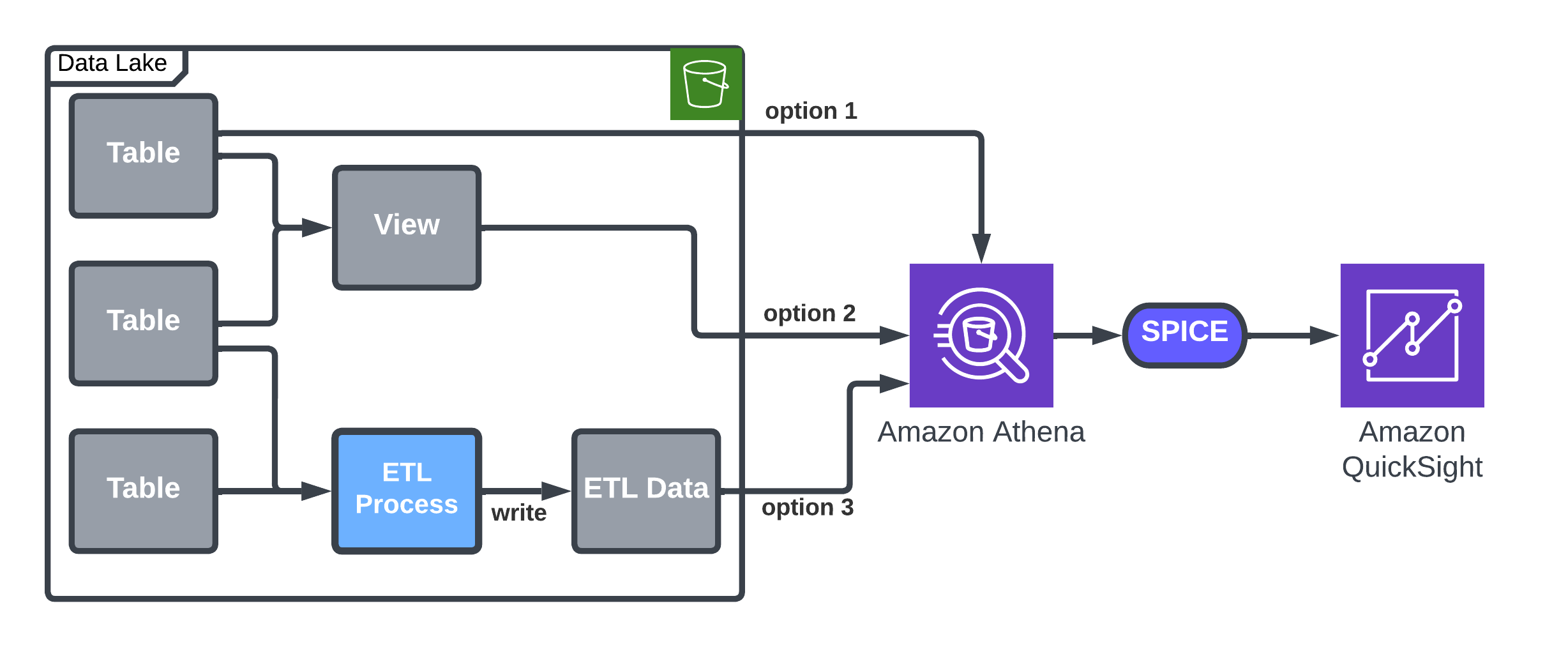
Resolution 1: Question with Athena and import to SPICE
QuickSight offers inherent capabilities to add knowledge utilizing Athena into SPICE, which is an easy strategy that meets Imperva’s necessities relating to easy knowledge administration. For instance, it fits steady knowledge flows with out frequent exceptions, which can lead to SPICE full refresh.
You should utilize Athena to load knowledge right into a QuickSight SPICE dataset, after which use the SPICE incremental add choice to load new knowledge to the dataset. A QuickSight dataset will probably be related to a desk or a view accessible by Athena. A time column (like day or hour) is used for incremental updates. The next desk summarizes the choices and particulars.
| Choice | Description | Professionals/Cons |
| Current desk | Use the built-in possibility by QuickSight. | Not versatile—the desk is imported as is within the knowledge lake. |
| Devoted view |
A view will allow you to higher management the information in your dataset. It permits becoming a member of knowledge, aggregation, or selecting a filter just like the date you wish to begin importing knowledge from. Be aware that QuickSight permits constructing a dataset based mostly on customized SQL, however this selection doesn’t permit incremental updates. |
Massive Athena useful resource consumption on a full refresh. |
| Devoted ETL |
Create a devoted ETL course of, which has similarities to a view, however in contrast to the view, it permits reuse of the ends in case of a full refresh. In case your ETL or view comprises grouping or different complicated operations, you realize that these operations will probably be achieved solely by the ETL course of, in line with the schedule you outline. |
Most versatile, however requires ETL improvement and implementation and extra Amazon S3 storage. |
The next structure diagram particulars the choices for loading knowledge by Athena into SPICE.
The next code offers a SQL instance for a view creation. We assume the existence of two tables, clients and occasions, with one be a part of column referred to as customer_id. The view is used to do the next:
- Combination the information from each day to weekly, and scale back the variety of rows
- Management the beginning date of the dataset (on this case, 30 weeks again)
- Be part of the information so as to add extra columns (
customer_type) and filter it
Resolution 2: Load knowledge into Redshift Serverless
Redshift Serverless offers full visibility to the information, which could be considered or edited at any time. For instance, if there’s a delay in including knowledge to the information lake or the information isn’t correctly added, with Redshift Serverless, you’ll be able to edit knowledge utilizing SQL statements or retry knowledge loading. Redshift Serverless is a scalable answer that doesn’t have a dataset dimension limitation.
Redshift Serverless is used as a serving layer for the datasets which are for use in QuickSight. The pricing mannequin for Redshift Serverless is predicated on storage utilization and the run of queries; idle compute assets don’t have any related price. Organising a cluster is easy and doesn’t require you to decide on node sorts or quantity of storage. You merely load the information to tables you create and begin working.
To create a brand new dataset, you have to create an Amazon Redshift desk and run the next course of each time knowledge is added:
- Rework the information utilizing an ETL course of (optionally available):
- Learn knowledge from the tables.
- Rework to the QuickSight dataset schema.
- Write the information to an S3 bucket and cargo it to Amazon Redshift.
- Delete outdated knowledge if it exists to keep away from duplicate knowledge.
- Load the information utilizing the COPY command.
The next structure diagram particulars the choices to load knowledge into Redshift Serverless with or with out an ETL course of.

The Amazon Redshift COPY command is easy and quick. For instance, to repeat each day partition Parquet knowledge, use the next code:
Use the next COPY command to load the output file of the ETL course of. Values will probably be truncated in line with Amazon Redshift column dimension. The column truncation is vital as a result of, in contrast to within the knowledge lake, in Amazon Redshift, the column dimension have to be set. This feature prevents COPY failures:
The Amazon Redshift COPY operation offers many advantages and choices. It helps a number of codecs in addition to column mapping, escaping, and extra. It additionally permits extra management over knowledge format, object dimension, and choices to tune the COPY operation for improved efficiency. Not like knowledge within the knowledge lake, Amazon Redshift has column size specs. We use TRUNCATECOLUMNS to truncates the information in columns to the suitable variety of characters in order that it matches the column specification.
Utilizing this methodology offers full management over the information. In case of an issue, we are able to restore components of the desk by deleting outdated knowledge and loading the information once more. It’s additionally doable to make use of the QuickSight dataset JOIN possibility, which isn’t obtainable in SPICE when utilizing incremental replace.
Further advantage of this strategy is that the information is obtainable for different shoppers and companies wanting to make use of the identical knowledge, similar to SQL shoppers or notebooks servers similar to Apache Zeppelin.
Conclusion
QuickSight permits Imperva to show enterprise knowledge to varied departments inside a corporation. Within the publish, we explored approaches for importing knowledge from a knowledge lake to QuickSight, whether or not repeatedly or incrementally.
Nonetheless, it’s vital to notice that there isn’t a one-size-fits-all answer; the optimum strategy will rely upon the particular use case. Each choices—steady and incremental updates—are scalable and versatile, with no vital price variations noticed for our dataset and entry patterns.
Imperva discovered incremental refresh to be very helpful and makes use of it for easy knowledge administration. For extra complicated datasets, Imperva has benefitted from the higher scalability and adaptability supplied by Redshift Serverless.
In circumstances the place the next diploma of management over the datasets was required, Imperva selected Redshift Serverless in order that knowledge points might be addressed promptly by deleting, updating, or inserting new data as crucial.
With the mixing of dashboards, people can now entry knowledge that was beforehand inaccessible to them. Furthermore, QuickSight has performed an important function in streamlining our knowledge distribution processes, enabling knowledge accessibility throughout all departments inside the group.
To be taught extra, go to Amazon QuickSight.
Concerning the Authors

Eliad Maimon is a Senior Startups Options Architect at AWS in Tel-Aviv with over 20 years of expertise in architecting, constructing, and sustaining software program merchandise. He creates architectural finest practices and collaborates with clients to leverage cloud and innovation, remodeling companies and disrupting markets. Eliad is specializing in machine studying on AWS, with a spotlight in areas similar to generative AI, MLOps, and Amazon SageMaker.

Ori Nakar is a principal cyber-security researcher, a knowledge engineer, and a knowledge scientist at Imperva Menace Analysis group. Ori has a few years of expertise as a software program engineer and engineering supervisor, centered on cloud applied sciences and large knowledge infrastructure.
[ad_2]