
[ad_1]
1000’s of builders use Apache Flink to construct streaming purposes to rework and analyze information in actual time. Apache Flink is an open supply framework and engine for processing information streams. It’s extremely out there and scalable, delivering excessive throughput and low latency for essentially the most demanding stream-processing purposes. Monitoring and scaling your purposes is essential to maintain your purposes working efficiently in a manufacturing surroundings.
Amazon Managed Service for Apache Flink is a totally managed service that reduces the complexity of constructing and managing Apache Flink purposes. Amazon Managed Service for Apache Flink manages the underlying Apache Flink parts that present sturdy utility state, metrics, logs, and extra.
On this publish, we present a simplified solution to routinely scale up and down the variety of KPUs (Kinesis Processing Items; 1 KPU is 1 vCPU and 4 GB of reminiscence) of your Apache Flink purposes with Amazon Managed Service for Apache Flink. We present you scale by utilizing metrics similar to CPU, reminiscence, backpressure, or any customized metric of your selection. Moreover, we present carry out scheduled scaling, permitting you to regulate your utility’s capability at particular occasions, significantly when coping with predictable workloads. We additionally share an AWS CloudFormation utility that will help you implement auto scaling shortly together with your Amazon Managed Service for Apache Flink purposes.
Metric-based scaling
This part describes implement a scaling resolution for Amazon Managed Service for Apache Flink primarily based on Amazon CloudWatch metrics. Amazon Managed Service for Apache Flink comes with an auto scaling possibility out of the field that scales out when container CPU utilization is above 75% for quarter-hour. This works nicely for a lot of use instances; nevertheless, for some purposes, you might must scale primarily based on a distinct metric, or set off the scaling motion at a sure time limit or by a distinct issue. You may customise your scaling insurance policies and save prices by right-sizing your Amazon Managed Apache Flink purposes the deploying this resolution.
To carry out metric-based scaling, we use CloudWatch alarms, Amazon EventBridge, AWS Step Capabilities, and AWS Lambda. You may select from metrics coming from the supply similar to Amazon Kinesis Information Streams or Amazon Managed Streaming for Apache Kafka (Amazon MSK), or metrics from the Amazon Managed Service for Apache Flink utility. You will discover these parts within the CloudFormation template within the GitHub repo.
The next diagram reveals scale an Amazon Managed Service for Apache Flink utility in response to a CloudWatch alarm.

This resolution makes use of the metric chosen and creates two CloudWatch alarms that, relying on the edge you utilize, set off a rule in EventBridge to start out working a Step Capabilities state machine. The next diagram illustrates the state machine workflow.
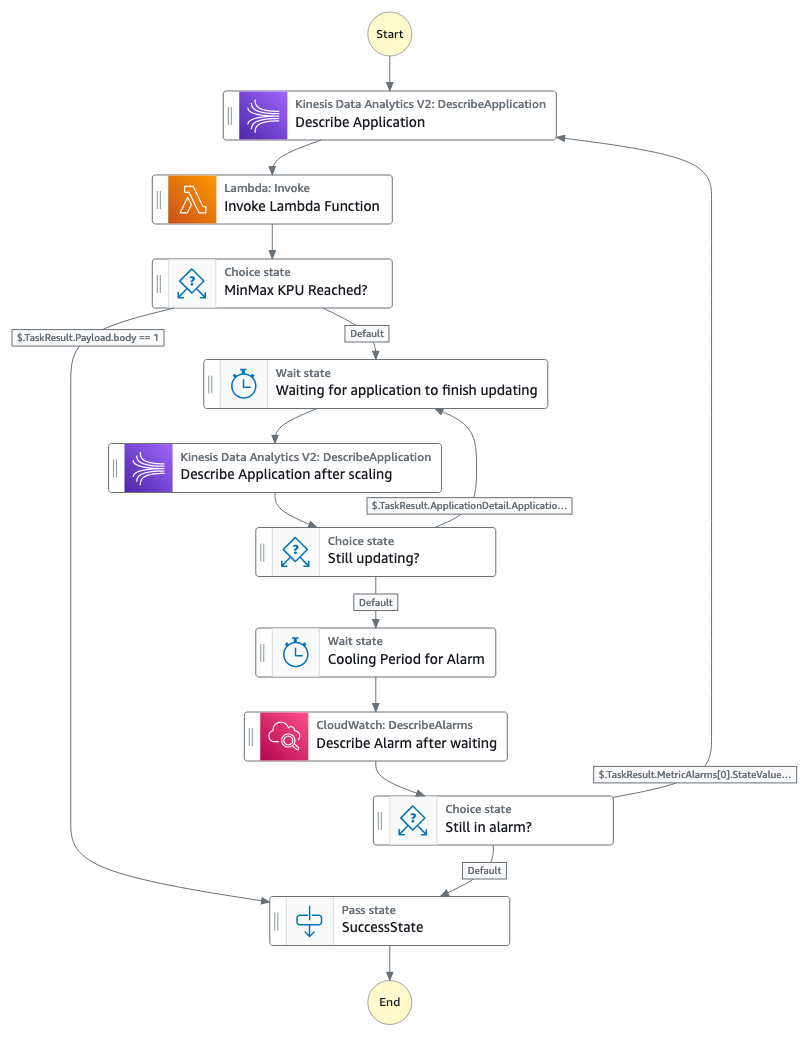
Word: Amazon Kinesis Information Analytics was renamed to Amazon Managed Service for Apache Flink August 2023
The Step Capabilities workflow consists of the next steps:
- The state machine describes the Amazon Managed Service for Apache Flink utility, which is able to present info associated to the present variety of KPUs within the utility, as nicely if the applying is being up to date or is it working.
- The state machine invokes a Lambda operate that, relying on which alarm was triggered, will scale the applying up or down, following the parameters set within the CloudFormation template. When scaling the applying, it’s going to use the rise issue (both add/subtract or a number of/divide primarily based on that issue) outlined within the CloudFormation template. You may have various factors for scaling in or out. If you wish to take a extra cautious method to scaling, you need to use add/subtract and use a rise issue for scaling in/out of 1.
- If the applying has reached the utmost or minimal variety of KPUs set within the parameters of the CloudFormation template, the workflow stops. Take into account that Amazon Managed Service for Apache Flink purposes have a default most of 64 KPUs (you may request to extend this restrict). Don’t specify a most worth above 64 KPUs when you have not requested to extend the quota, as a result of the scaling resolution will get caught by failing to replace.
- If the workflow continues, as a result of the allotted KPUs haven’t reached the utmost or minimal values, the workflow will look forward to a time frame you specify, after which describe the applying and see if it has completed updating.
- The workflow will proceed to attend till the applying has completed updating. When the applying is up to date, the workflow will look forward to a time frame you specify within the CloudFormation template, to permit the metric to fall inside the threshold and have the CloudWatch rule change from ALARM state to OK.
- If the metric remains to be in ALARM state, the workflow will begin once more and proceed to scale the applying both up or down. If the metric is in OK state, the workflow will cease.
For purposes that learn from a Kinesis Information Streams supply, you need to use the metric millisBehindLatest. If utilizing a Kafka supply, you need to use information lag max for scaling occasions. These metrics seize how far behind your utility is from the pinnacle of the stream. You can too use a customized metric that you’ve got registered in your Apache Flink purposes.
The pattern CloudFormation template means that you can choose one of many following metrics:
- Amazon Managed Service for Apache Flink utility metrics – Requires an utility title:
- ContainerCPUUtilization – Total share of CPU utilization throughout activity supervisor containers within the Flink utility cluster.
- ContainerMemoryUtilization – Total share of reminiscence utilization throughout activity supervisor containers within the Flink utility cluster.
- BusyTimeMsPerSecond – Time in milliseconds the applying is busy (neither idle nor again pressured) per second.
- BackPressuredTimeMsPerSecond – Time in milliseconds the applying is again pressured per second.
- LastCheckpointDuration – Time in milliseconds it took to finish the final checkpoint.
- Kinesis Information Streams metrics – Requires the info stream title:
- MillisBehindLatest – The variety of milliseconds the patron is behind the pinnacle of the stream, indicating how far behind the present time the patron is.
- IncomingRecords – The variety of information efficiently put to the Kinesis information stream over the desired time interval. If no information are coming, this metric can be null and also you gained’t have the ability to scale down.
- Amazon MSK metrics – Requires the cluster title, matter title, and client group title):
- MaxOffsetLag – The utmost offset lag throughout all partitions in a subject.
- SumOffsetLag – The aggregated offset lag for all of the partitions in a subject.
- EstimatedMaxTimeLag – The time estimate (in seconds) to empty MaxOffsetLag.
- Customized metrics – Metrics you may outline as a part of your Apache Flink purposes. Most typical metrics are counters (constantly improve) or gauges (may be up to date with final worth). For this resolution, it is advisable to add the kinesisAnalytics dimension to the metric group. You additionally want to supply the customized metric title as a parameter within the CloudFormation template. If it is advisable to use extra dimensions in your customized metric, it is advisable to modify the CloudWatch alarm so it’s ready to make use of your particular metric. For extra info on customized metrics, see Utilizing Customized Metrics with Amazon Managed Service for Apache Flink.
The CloudFormation template deploys the assets in addition to the auto scaling code. You solely must specify the title of the Amazon Managed Service for Apache Flink utility, the metric to which you wish to scale your utility in or out, and the thresholds for triggering an alarm. The answer by default will use the typical aggregation for metrics and a interval period of 60 seconds for every information level. You may configure the analysis intervals and information factors to alarm when defining the CloudFormation template.
Scheduled scaling
This part describes implement a scaling resolution for Amazon Managed Service for Apache Flink primarily based on a schedule. To carry out scheduled scaling, we use EventBridge and Lambda, as illustrated within the following determine.

These parts can be found within the CloudFormation template within the GitHub repo.
The EventBridge scheduler is triggered primarily based on the parameters set when deploying the CloudFormation template. You outline the KPU of the purposes when working at peak occasions, in addition to the KPU for non-peak occasions. The appliance runs with these KPU parameters relying on the time of day.
As with the earlier instance for metric-based scaling, the CloudFormation template deploys the assets and scaling code required. You solely must specify the title of the Amazon Managed Service for Apache Flink utility and the schedule for the scaler to switch the applying to the set variety of KPUs.
Issues for scaling Flink purposes utilizing metric-based or scheduled scaling
Concentrate on the next when contemplating these options:
- When scaling Amazon Managed Service for Apache Flink purposes in or out, you may select to both improve the general utility parallelism or modify the parallelism per KPU. The latter means that you can set the variety of parallel duties that may be scheduled per KPU. This pattern solely updates the general parallelism, not the parallelism per KPU.
- If SnapshotsEnabled is ready to true in ApplicationSnapshotConfiguration, Amazon Managed Service for Apache Flink will routinely pause the applying, take a snapshot, after which restore the applying with the up to date configuration every time it’s up to date or scaled. This course of might end in downtime for the applying, relying on the state measurement, however there can be no information loss. When utilizing metric-based scaling, you need to select a minimal and a most threshold of KPU the applying can have. Relying on by how a lot you carry out the scaling, if the brand new desired KPU is greater or decrease than your thresholds, the answer will replace the KPUs to be equal to your thresholds.
- When utilizing metric-based scaling, you even have to decide on a cooling down interval. That is the period of time you need your utility to attend after being up to date, to see if the metric has gone from ALARM standing to OK standing. This worth depends upon how lengthy are you prepared to attend earlier than one other scaling occasion to happen.
- With the metric-based scaling resolution, you might be restricted to selecting the metrics which might be listed within the CloudFormation template. Nonetheless, you may modify the alarms to make use of any out there metric in CloudWatch.
- In case your utility is required to run with out interruptions for intervals of time, we suggest utilizing scheduled scaling, to restrict scaling to non-critical occasions.
Abstract
On this publish, we lined how one can allow customized scaling for Amazon Managed Service for Apache Flink purposes utilizing enhanced monitoring options from CloudWatch built-in with Step Capabilities and Lambda. We additionally confirmed how one can configure a schedule to scale an utility utilizing EventBridge. Each of those samples and plenty of extra may be discovered within the GitHub repo.
In regards to the Authors
 Deepthi Mohan is a Principal PMT on the Amazon Managed Service for Apache Flink crew.
Deepthi Mohan is a Principal PMT on the Amazon Managed Service for Apache Flink crew.
 Francisco Morillo is a Streaming Options Architect at AWS. Francisco works with AWS prospects, serving to them design real-time analytics architectures utilizing AWS companies, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
Francisco Morillo is a Streaming Options Architect at AWS. Francisco works with AWS prospects, serving to them design real-time analytics architectures utilizing AWS companies, supporting Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink.
[ad_2]