
[ad_1]
Backtesting is a course of utilized in quantitative finance to guage buying and selling methods utilizing historic knowledge. This helps merchants decide the potential profitability of a technique and determine any dangers related to it, enabling them to optimize it for higher efficiency.
Index rebalancing arbitrage takes benefit of short-term worth discrepancies ensuing from ETF managers’ efforts to attenuate index monitoring error. Main market indexes, resembling S&P 500, are topic to periodic inclusions and exclusions for causes past the scope of this put up (for an instance, consult with CoStar Group, Invitation Properties Set to Be a part of S&P 500; Others to Be a part of S&P 100, S&P MidCap 400, and S&P SmallCap 600). The arbitrage commerce appears to be like to revenue from going lengthy on shares added to an index and shorting those which might be eliminated, with the intention of producing revenue from these worth variations.
On this put up, we glance into the method of utilizing backtesting to guage the efficiency of an index arbitrage profitability technique. We particularly discover how Amazon EMR and the newly developed Apache Iceberg branching and tagging function can handle the problem of look-ahead bias in backtesting. It will allow a extra correct analysis of the efficiency of the index arbitrage profitability technique.
Terminology
Let’s first focus on a number of the terminology used on this put up:
- Analysis knowledge lake on Amazon S3 – A knowledge lake is a big, centralized repository that permits you to handle all of your structured and unstructured knowledge at any scale. Amazon Easy Storage Service (Amazon S3) is a well-liked cloud-based object storage service that can be utilized as the muse for constructing an information lake.
- Apache Iceberg – Apache Iceberg is an open-source desk format that’s designed to offer environment friendly, scalable, and safe entry to massive datasets. It supplies options resembling ACID transactions on high of Amazon S3-based knowledge lakes, schema evolution, partition evolution, and knowledge versioning. With scalable metadata indexing, Apache Iceberg is ready to ship performant queries to a wide range of engines resembling Spark and Athena by lowering planning time.
- Look–forward bias – It is a frequent problem in backtesting, which happens when future info is inadvertently included in historic knowledge used to check a buying and selling technique, resulting in overly optimistic outcomes.
- Iceberg tags – The Iceberg branching and tagging function permits customers to tag particular snapshots of their knowledge tables with significant labels utilizing SQL syntax or the Iceberg library, which correspond to particular occasions notable to inner funding groups. This, mixed with Iceberg’s time journey performance, ensures that correct knowledge enters the analysis pipeline and guards it from hard-to-detect issues resembling look-ahead bias.
Testing scope
For our testing functions, contemplate the next instance, during which a change to the S&P Dow Jones Indices is introduced on September 2, 2022, turns into efficient on September 19, 2022, and doesn’t turn into observable within the ETF holdings knowledge that we’ll be utilizing within the experiment till September 30, 2022. We use Iceberg tags to label market knowledge snapshots to keep away from look-ahead bias within the analysis knowledge lake, which can allow us to check varied commerce entry and exit situations and assess the respective profitability of every.
Experiment
As a part of our experiment, we make the most of a paid, third-party knowledge supplier API to determine SPY ETF holdings modifications and assemble a portfolio. Our mannequin portfolio will purchase shares which might be added to the index, referred to as going lengthy, and can promote an equal quantity of shares faraway from the index, referred to as going brief.
We are going to take a look at short-term holding intervals, resembling 1 day and 1, 2, 3, or 4 weeks, as a result of we assume that the rebalancing impact could be very short-lived and new info, resembling macroeconomics, will drive efficiency past the studied time horizons. Lastly, we simulate totally different entry factors for this commerce:
- Market open the day after announcement day (AD+1)
- Market shut of efficient date (ED0)
- Market open the day after ETF holdings registered the change (MD+1)
Analysis knowledge lake
To run our experiment, we have now have used the next analysis knowledge lake surroundings.
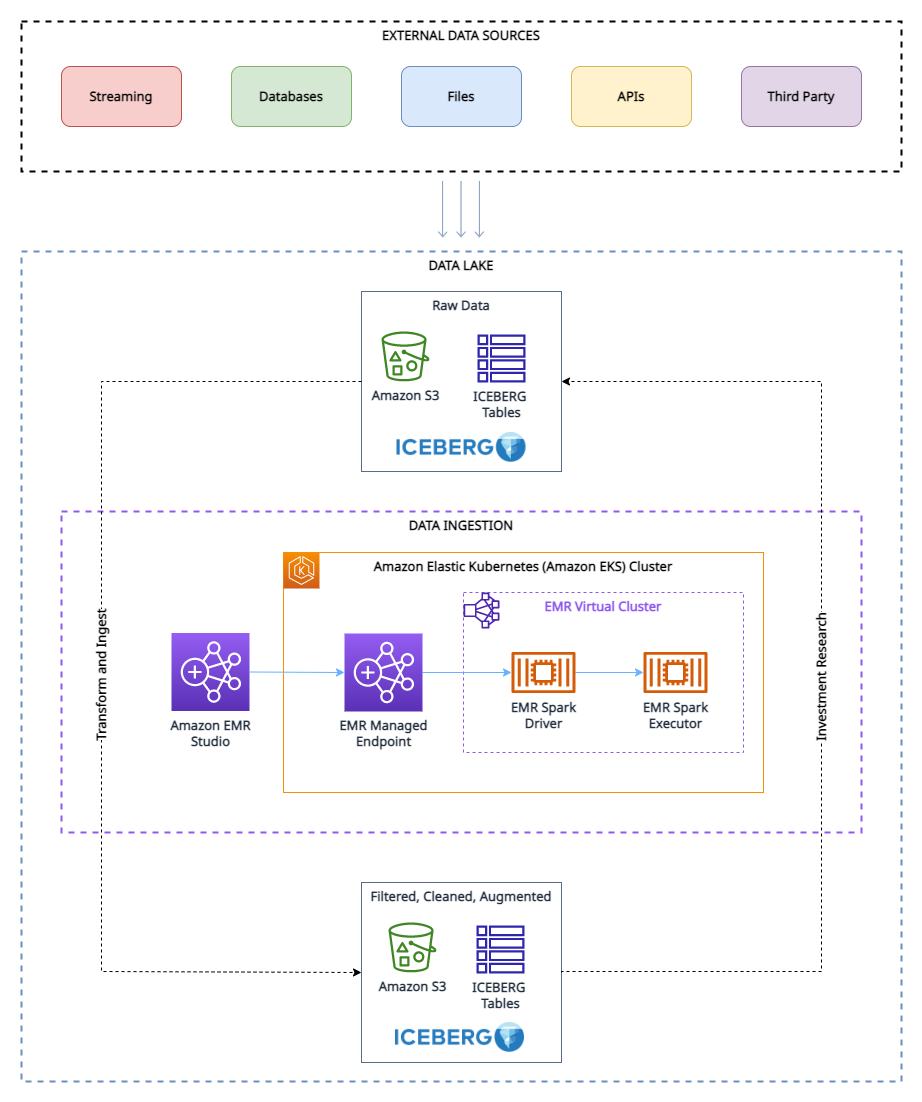
As proven within the structure diagram, the analysis knowledge lake is constructed on Amazon S3 and managed utilizing Apache Iceberg, which is an open desk format bringing the reliability and ease of relational database administration service (RDBMS) tables to knowledge lakes. To keep away from look-ahead bias in backtesting, it’s important to create snapshots of the information at totally different time limits. Nevertheless, managing and organizing these snapshots might be difficult, particularly when coping with a big quantity of information.
That is the place the tagging function in Apache Iceberg is useful. With tagging, researchers can create otherwise named snapshots of market knowledge and observe modifications over time. For instance, they’ll create a snapshot of the information on the finish of every buying and selling day and tag it with the date and any related market circumstances.
Through the use of tags to prepare the snapshots, researchers can simply question and analyze the information based mostly on particular market circumstances or occasions, with out having to fret in regards to the particular dates of the information. This may be notably useful when conducting analysis that’s not time-sensitive or when on the lookout for traits over lengthy intervals of time.
Moreover, the tagging function also can assist with different features of information administration, resembling knowledge retention for GDPR compliance, and sustaining lineages of the desk through totally different branches. Researchers can use Apache Iceberg tagging to make sure the integrity and accuracy of their knowledge whereas additionally simplifying knowledge administration.
Conditions
To comply with together with this walkthrough, you should have the next:
- An AWS account with an IAM function that has enough entry to provision the required assets.
- To adjust to licensing concerns, we can’t present a pattern of the ETF constituents knowledge. Subsequently, it should be bought individually for the dataset onboarding functions.
Answer overview
To arrange and take a look at this experiment, we full the next high-level steps:
- Create an S3 bucket.
- Load the dataset into Amazon S3. For this put up, the ETF knowledge referred to was obtained through API name by way of a third-party supplier, however you can too contemplate the next choices:
- You should utilize the next prescriptive steerage, which describes how you can automate knowledge ingestion from varied knowledge suppliers into an information lake in Amazon S3 utilizing AWS Information Alternate.
- You can too make the most of AWS Information Alternate to pick out from a variety of third-party dataset suppliers. It simplifies the utilization of information information, tables, and APIs on your particular wants.
- Lastly, you can too consult with the next put up on how you can use AWS Information Alternate for Amazon S3 to entry knowledge from a supplier bucket: Analyzing influence of regulatory reform on the inventory market utilizing AWS and Refinitiv knowledge.
- Create an EMR cluster. You should utilize this Getting Began with EMR tutorial or we used CDK to deploy an EMR on EKS surroundings with a customized managed endpoint.
- Create an EMR pocket book utilizing EMR Studio. For our testing surroundings, we used a customized construct Docker picture, which incorporates Iceberg v1.3. For directions on attaching a cluster to a Workspace, consult with Connect a cluster to a Workspace.
- Configure a Spark session. You’ll be able to comply with alongside through the next pattern pocket book.
- Create an Iceberg desk and cargo the take a look at knowledge from Amazon S3 into the desk.
- Tag this knowledge to protect a snapshot of it.
- Carry out updates to our take a look at knowledge and tag the up to date dataset.
- Run simulated backtesting on our take a look at knowledge to search out essentially the most worthwhile entry level for a commerce.
Create the experiment surroundings
We are able to rise up and working with Iceberg by making a desk through Spark SQL from an current view, as proven within the following code:
Now that we’ve created an Iceberg desk, we are able to use it for funding analysis. One of many key options of Iceberg is its help for scalable knowledge versioning. Which means we are able to simply observe modifications to our knowledge and roll again to earlier variations with out making further copies. As a result of this knowledge will get up to date periodically, we would like to have the ability to create named snapshots of the information in order that quant merchants have quick access to constant snapshots of information which have their very own retention coverage. On this case, let’s tag the dataset to point that it represents the ETF holdings knowledge as of Q1 2022:
As we transfer ahead in time and new knowledge turns into accessible by Q3, we could have to replace current datasets to mirror these modifications. Within the following instance, we first use an UPDATE assertion to mark the shares as expired within the current ETF holdings dataset. Then we use the MERGE INTO assertion based mostly on matching circumstances resembling ISIN code. If a match will not be discovered between the prevailing dataset and the brand new dataset, the brand new knowledge shall be inserted as new data within the desk and standing code shall be set to ‘new’ for these data. Equally, if the prevailing dataset has shares that aren’t current within the new dataset, these data will stay expired with a standing code of ‘expired’. Lastly, for data the place a match is discovered, the information within the current dataset shall be up to date with the information from the brand new dataset, and file may have an unchanged standing code. With Iceberg’s help for environment friendly knowledge versioning and transactional consistency, we might be assured that our knowledge updates shall be utilized appropriately and with out knowledge corruption.
As a result of we now have a brand new model of the information, we use Iceberg tagging to offer isolation for every new model of information. On this case, we tag this as Q3_2022 and permit quant merchants and different customers to work on this snapshot of the information with out being affected by ongoing updates to the pipeline:
This makes it very simple to see which shares are being added and deleted. We are able to use Iceberg’s time journey function to learn the information at a given quarterly tag. First, let’s take a look at which shares are added to the index; these are the rows which might be within the Q3 snapshot however not within the Q1 snapshot. Then we’ll take a look at which shares are eliminated; these are the rows which might be within the Q1 snapshot however not within the Q3 snapshot:
Now we use the delta obtained within the previous code to backtest the next technique. As a part of the index rebalancing arbitrage course of, we’re going to lengthy shares which might be added to the index and brief shares which might be faraway from the index, and we’ll take a look at this technique for each the efficient date and announcement date. As a proof of idea from the 2 totally different lists, we picked PVH and PENN as eliminated shares, and CSGP and INVH as added shares.
To comply with together with the examples under, you have to to make use of the pocket book supplied within the Quant Analysis instance GitHub repository.
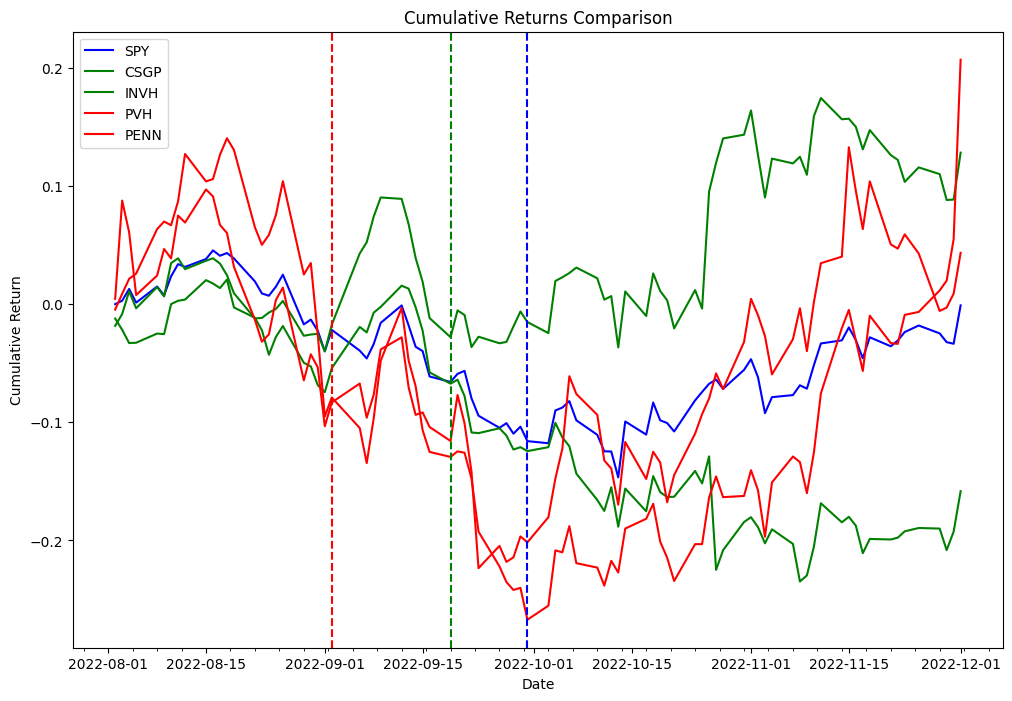
The next desk characterize the portfolio orders data:
| Order Id | Column | Timestamp | Dimension | Value | Charges | Aspect |
|---|---|---|---|---|---|---|
| 0 | (PENN, PENN) | 2022-09-06 | 31948.881789 | 31.66 | 0.0 | Promote |
| 1 | (PVH, PVH) | 2022-09-06 | 18321.729571 | 55.15 | 0.0 | Promote |
| 2 | (INVH, INVH) | 2022-09-06 | 27419.797094 | 38.20 | 0.0 | Purchase |
| 3 | (CSGP, CSGP) | 2022-09-06 | 14106.361969 | 75.00 | 0.0 | Purchase |
| 4 | (CSGP, CSGP) | 2022-11-01 | 14106.361969 | 83.70 | 0.0 | Promote |
| 5 | (INVH, INVH) | 2022-11-01 | 27419.797094 | 31.94 | 0.0 | Promote |
| 6 | (PVH, PVH) | 2022-11-01 | 18321.729571 | 52.95 | 0.0 | Purchase |
| 7 | (PENN, PENN) | 2022-11-01 | 31948.881789 | 34.09 | 0.0 | Purchase |
Experimentation findings
The next desk exhibits Sharpe Ratios for varied holding intervals and two totally different commerce entry factors: announcement and efficient dates.
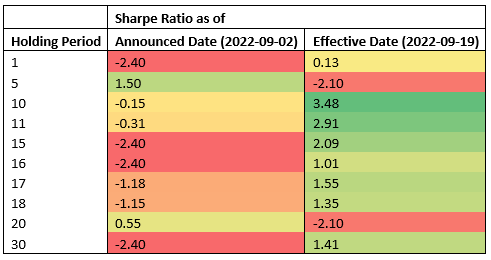
The information means that the efficient date is essentially the most worthwhile entry level throughout most holding intervals, whereas the announcement date is an efficient entry level for short-term holding intervals (5 calendar days, 2 enterprise days). As a result of the outcomes are obtained from testing a single occasion, this isn’t statistically important to simply accept or reject a speculation that index rebalancing occasions can be utilized to generate constant alpha. The infrastructure we used for our testing can be utilized to run the identical experiment required to do speculation testing at scale, however index constituents knowledge will not be available.
Conclusion
On this put up, we demonstrated how the usage of backtesting and the Apache Iceberg tagging function can present invaluable insights into the efficiency of index arbitrage profitability methods. Through the use of a scalable Amazon EMR on Amazon EKS stack, researchers can simply deal with the whole funding analysis lifecycle, from knowledge assortment to backtesting. Moreover, the Iceberg tagging function may also help handle the problem of look-ahead bias, whereas additionally offering advantages resembling knowledge retention management for GDPR compliance and sustaining lineage of the desk through totally different branches. The experiment findings show the effectiveness of this method in evaluating the efficiency of index arbitrage methods and may function a helpful information for researchers within the finance business.
In regards to the Authors
 Boris Litvin is Principal Answer Architect, chargeable for monetary providers business innovation. He’s a former Quant and FinTech founder, and is enthusiastic about systematic investing.
Boris Litvin is Principal Answer Architect, chargeable for monetary providers business innovation. He’s a former Quant and FinTech founder, and is enthusiastic about systematic investing.
 Man Bachar is a Options Architect at AWS, based mostly in New York. He accompanies greenfield prospects and helps them get began on their cloud journey with AWS. He’s enthusiastic about id, safety, and unified communications.
Man Bachar is a Options Architect at AWS, based mostly in New York. He accompanies greenfield prospects and helps them get began on their cloud journey with AWS. He’s enthusiastic about id, safety, and unified communications.
 Noam Ouaknine is a Technical Account Supervisor at AWS, and is predicated in Florida. He helps enterprise prospects develop and obtain their long-term technique by way of technical steerage and proactive planning.
Noam Ouaknine is a Technical Account Supervisor at AWS, and is predicated in Florida. He helps enterprise prospects develop and obtain their long-term technique by way of technical steerage and proactive planning.
 Sercan Karaoglu is Senior Options Architect, specialised in capital markets. He’s a former knowledge engineer and enthusiastic about quantitative funding analysis.
Sercan Karaoglu is Senior Options Architect, specialised in capital markets. He’s a former knowledge engineer and enthusiastic about quantitative funding analysis.
 Jack Ye is a software program engineer within the Athena Information Lake and Storage workforce. He’s an Apache Iceberg Committer and PMC member.
Jack Ye is a software program engineer within the Athena Information Lake and Storage workforce. He’s an Apache Iceberg Committer and PMC member.
 Amogh Jahagirdar is a Software program Engineer within the Athena Information Lake workforce. He’s an Apache Iceberg Committer.
Amogh Jahagirdar is a Software program Engineer within the Athena Information Lake workforce. He’s an Apache Iceberg Committer.
[ad_2]