
[ad_1]
Previous to Rockset, I spent eight years at Fb constructing out their massive knowledge infrastructure and on-line knowledge infrastructure. All of the software program we wrote was deployed in Fb’s personal knowledge facilities, so it was not until I began constructing on the general public cloud that I absolutely appreciated its true potential.
Fb often is the very definition of a web-scale firm, however getting {hardware} nonetheless required big lead instances and intensive capability planning. The general public cloud, in distinction, gives {hardware} by way of the simplicity of API-based provisioning. It provides, for all intents and functions, infinite compute and storage, requested on demand and relinquished when not wanted.
An Epiphany on Cloud Elasticity
I got here to a easy realization in regards to the energy of cloud economics. Within the cloud, the worth of utilizing 1 CPU for 100 minutes is identical as that of utilizing 100 CPUs for 1 minute. If an information processing job that takes 100 minutes on a single CPU might be reconfigured to run in parallel on 100 CPUs in 1 minute, then the worth of computing this job would stay the identical, however the speedup can be large!
The Evolution to the Cloud
Latest evolutions of information processing state-of-the-art have every sought to take advantage of prevailing {hardware} tendencies. Hadoop and RocksDB are two examples I’ve had the privilege of engaged on personally. The falling worth of SATA disks within the early 2000s was one main issue for the recognition of Hadoop, as a result of it was the one software program that would cobble collectively petabytes of those disks to offer a large-scale storage system. Equally, RocksDB blossomed as a result of it leveraged the price-performance candy spot of SSD storage. At present, the {hardware} platform is in flux as soon as extra, with many purposes transferring to the cloud. This pattern in direction of cloud will once more herald a brand new breed of software program options.

The subsequent iteration of information processing software program will exploit the fluid nature of {hardware} within the cloud. Information workloads will seize and launch compute, reminiscence, and storage sources, as wanted and when wanted, to satisfy efficiency and value necessities. However knowledge processing software program must be reimagined and rewritten for this to develop into a actuality.
Learn how to Construct for the Cloud
Cloud-native knowledge platforms ought to scale dynamically to make use of obtainable cloud sources. Meaning an information request must be parallelized and the {hardware} required to run it immediately acquired. As soon as the mandatory duties are scheduled and the outcomes returned, the platform ought to promptly shed the {hardware} sources used for that request.
Merely processing in parallel doesn’t make a system cloud pleasant. Hadoop was a parallel-processing system, however its focus was on optimizing throughput of information processed inside a hard and fast set of pre-acquired sources. Likewise, many different pre-cloud methods, together with MongoDB and Elasticsearch, have been designed for a world wherein the underlying {hardware}, on which they run, was mounted.
The trade has lately made inroads designing knowledge platforms for the cloud, nonetheless. Qubole morphed Hadoop to be cloud pleasant, whereas Amazon Aurora and Snowflake constructed cloud-optimized relational databases. Listed here are some architectural patterns which are frequent in cloud-native knowledge processing:
Use of shared storage reasonably than shared-nothing storage
The earlier wave of distributed knowledge processing frameworks was constructed for non-cloud infrastructure and utilized shared-nothing architectures. Dr. Stonebraker has written about the benefits of shared-nothing architectures since 1986 (The Case for Shared Nothing), and the appearance of HDFS in 2005 made shared-nothing architectures a widespread actuality. At about the identical time, different distributed software program, like Cassandra, HBase, and MongoDB, which used shared-nothing storage, appeared in the marketplace. Storage was usually JBOD, domestically connected to particular person machines, leading to tightly coupled compute and storage.
However within the cloud period, object shops have develop into the dominant storage. Cloud providers reminiscent of Amazon S3 present shared storage that may be concurrently accessed from a number of nodes utilizing well-defined APIs. Shared storage allows us to decouple compute and storage and scale every independently. This capability leads to cloud-native methods which are orders of magnitude extra environment friendly. Dr. Dewitt, who taught my database lessons on the College of Wisconsin-Madison, postulated in his 2017 place paper that shared storage is again in trend!
Disaggregated structure
A cloud-native system is designed in such a method that it makes use of solely as a lot {hardware} as is actually wanted for the workload it’s serving. The cloud provides us the flexibility to make the most of storage, compute, and community independently of one another. We are able to solely profit from this if we design our service to make use of extra (or much less) of 1 {hardware} useful resource with out altering its consumption of every other {hardware} useful resource.
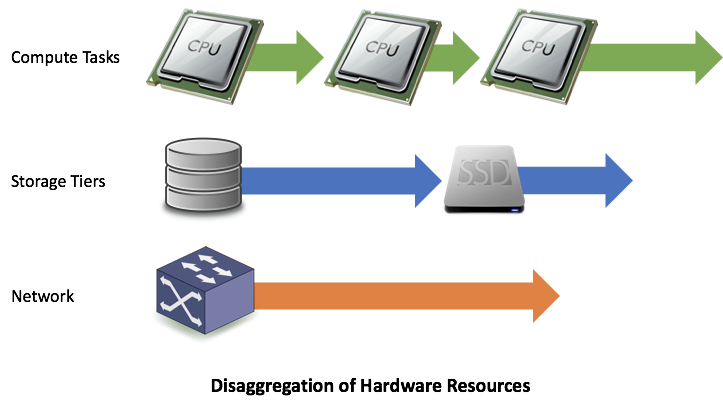
Enter microservices. A software program service could be composed from a set of microservices, with every microservice restricted by just one kind of useful resource. It is a disaggregated structure. If extra compute is required, add extra CPUs to the compute microservice. If extra storage is required, enhance the storage capability of the storage microservice. Discuss with this HotCloud ’18 paper by Prof. Remzi, Andrea, and our very personal Venkat for a extra thorough articulation of cloud-native design ideas.
Cloud-native scheduling to handle each provide and demand
To handle including and eradicating {hardware} sources to and from microservices, we’d like a brand new form of useful resource scheduler. Conventional job schedulers usually solely handle demand, i.e. it schedules job requests among the many accessible {hardware} sources. In distinction, a cloud-native scheduler can handle each provide and demand. Relying on workload and configured insurance policies, a cloud-native scheduler can request new {hardware} sources to be provisioned and concurrently schedule new job requests on provisioned {hardware}.
Conventional knowledge administration software program schedulers should not constructed to shed {hardware}. However within the cloud, it’s crucial {that a} scheduler shed {hardware} when not in use. The faster a system can take away extra {hardware}, the higher its price-performance traits.
Separation of sturdiness and efficiency
Sustaining a number of replicas of person knowledge to offer sturdiness within the occasion of node failure was a typical technique with pre-cloud methods, reminiscent of Hadoop, MongoDB, and Elasticsearch. The draw back of this method was that it value server capability. Having two or three replicas successfully doubled or tripled the {hardware} requirement. A greater method for a cloud-native knowledge platform is to make use of a cloud object retailer to make sure sturdiness, with out the necessity for replicas.
Replicas have a job to play in aiding system efficiency, however within the age of cloud, we will convey replicas on-line solely when there’s a want. If there aren’t any requests for a selected piece of information, it may possibly reside purely in cloud object storage. As requests for knowledge enhance, a number of replicas could be created to serve them. By utilizing cheaper cloud object storage for sturdiness and solely spinning up compute and quick storage for replicas when wanted for efficiency, cloud-native knowledge platforms can present higher price-performance.
Capability to leverage storage hierarchy
The cloud not solely permits us to independently scale storage when wanted, it additionally opens up many extra shared storage choices, reminiscent of distant SSD, distant spinning disks, object shops, and long-term chilly storage. These storage tiers every present totally different cost-latency traits, so we will place knowledge on totally different storage tiers relying on how ceaselessly they’re accessed.
Cloud-native knowledge platforms are generally designed to benefit from the storage hierarchy available within the cloud. In distinction, exploiting the storage hierarchy was by no means a design objective for a lot of current methods as a result of it was troublesome to implement a number of bodily storage tiers within the pre-cloud world. One needed to assemble {hardware} from a number of distributors to arrange a hierarchical storage system. This was cumbersome and time consuming, and solely very refined customers may afford it.
Takeaways
A cloud-only software program stack has properties that have been by no means into account for conventional methods. Disaggregation is essential. Fluid useful resource administration, the place {hardware} provide can carefully hug the demand curve, will develop into the norm—even for stateful methods. Embarrassingly parallel algorithms must be employed at each alternative till methods are hardware-resource certain—if not, it’s a limitation of your software program. You don’t get these benefits by deploying conventional software program onto
cloud nodes; you must construct for the cloud from the bottom up.
[ad_2]