
[ad_1]
Introduction
Retrieval Augmented Technology has been right here for some time. Many instruments and purposes are being constructed round this idea, like vector shops, retrieval frameworks, and LLMs, making it handy to work with customized paperwork, particularly Semi-structured Information with Langchain. Working with lengthy, dense texts has by no means been really easy and enjoyable. The standard RAG works effectively with unstructured text-heavy recordsdata like DOC, PDFs, and so forth. Nevertheless, this method doesn’t sit effectively with semi-structured information, akin to embedded tables in PDFs.
Whereas working with semi-structured information, there are normally two considerations.
- The standard extraction and text-splitting strategies don’t account for tables in PDFs. They normally find yourself breaking apart the tables. Therefore leading to data loss.
- Embedding tables might not translate to express semantic search.
So, on this article, we are going to construct a Retrieval era pipeline for semi-structured information with Langchain to handle these two considerations with semistructured information.
Studying Goals
- Perceive the distinction between structured, unstructured, and semi-structured information.
- A gentle refresher on Retrieval Augement Technology and Langchain.
- Discover ways to construct a multi-vector retriever to deal with semi-structured information with Langchain.
This text was revealed as part of the Information Science Blogathon.
Sorts of Information
There are normally three forms of information. Structured, Semi-structured, and Unstructured.
- Structured Information: The structured information is the standardized information. The information follows a pre-defined schema, akin to rows and columns. SQL databases, Spreadsheets, information frames, and so forth.
- Unstructured Information: Unstructured information, not like structured information, follows no information mannequin. The information is as random as it might probably get. For instance, PDFs, Texts, Photographs, and so forth.
- Semi-structured Information: It’s the mixture of the previous information sorts. In contrast to the structured information, it doesn’t have a inflexible pre-defined schema. Nevertheless, the info nonetheless maintains a hierarchical order based mostly on some markers, which is in distinction to unstructured sorts. For instance, CSVs, HTML, Embedded tables in PDFs, XMLs, and so forth.

What’s RAG?
RAG stands for Retrieval Augmented Technology. It’s the easiest technique to feed the Massive language fashions with novel data. So, let’s have a fast primer on RAG.
In a typical RAG pipeline, we’ve information sources, akin to native recordsdata, Internet pages, databases, and so forth, an embedding mannequin, a vector database, and an LLM. We accumulate the info from varied sources, cut up the paperwork, get the embeddings of textual content chunks, and retailer them in a vector database. Now, we cross the embeddings of queries to the vector retailer, retrieve the paperwork from the vector retailer, and eventually generate solutions with the LLM.
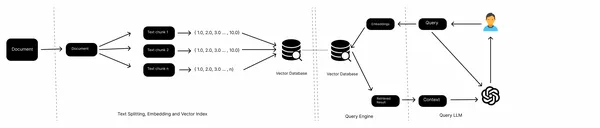
It is a workflow of a traditional RAG and works effectively with unstructured information like texts. Nevertheless, relating to semi-structured information, for instance, embedded tables in a PDF, it usually fails to carry out effectively. On this article, we are going to discover ways to deal with these embedded tables.
What’s Langchain?
The Langchain is an open-source framework for constructing LLM-based purposes. Since its launch, the venture has garnered broad adoption amongst software program builders. It supplies a unified vary of instruments and applied sciences to construct AI purposes quicker. Langchain homes instruments akin to vector shops, doc loaders, retrievers, embedding fashions, textual content splitters, and so forth. It’s a one-stop resolution for constructing AI purposes. However there may be two core worth proposition that makes it stand aside.
- LLM chains: Langchain supplies a number of chains. These chains chain collectively a number of instruments to perform a single process. For instance, ConversationalRetrievalChain chains collectively an LLM, Vector retailer retriever, embedding mannequin, and a chat historical past object to generate responses for a question. The instruments are exhausting coded and must be outlined explicitly.
- LLM brokers: In contrast to LLM chains, AI brokers should not have hard-coded instruments. As an alternative of chaining one instrument after one other, we let the LLM determine which one to pick out and when based mostly on textual content descriptions of instruments. This makes it best for constructing advanced LLM purposes involving reasoning and decision-making.
Constructing The RAG pipeline
Now that we’ve a primer on the ideas. Let’s focus on the method to constructing the pipeline. Working with semi-structured information might be tough because it doesn’t comply with a traditional schema for storing data. And to work with unstructured information, we want specialised instruments tailored for extracting data. So, on this venture, we are going to use one such instrument known as “unstructured”; it’s an open-source instrument for extracting data from completely different unstructured information codecs, akin to tables in PDFs, HTML, XML, and so forth. Unstructured makes use of Tesseract and Poppler beneath the hood to course of a number of information codecs in recordsdata. So, let’s arrange the environment and set up dependencies earlier than diving into the coding half.
Set-up Dev Env
Like every other Python venture, open a Python atmosphere and set up Poppler and Tesseract.
!sudo apt set up tesseract-ocr
!sudo apt-get set up poppler-utilsNow, set up the dependencies that we’ll want in our venture.
!pip set up "unstructured[all-docs]" Langchain openaiNow that we’ve put in the dependencies, we are going to extract information from a PDF file.
from unstructured.partition.pdf import partition_pdf
pdf_elements = partition_pdf(
"mistral7b.pdf",
chunking_strategy="by_title",
extract_images_in_pdf=True,
max_characters=3000,
new_after_n_chars=2800,
combine_text_under_n_chars=2000,
image_output_dir_path="./"
)Operating it would set up a number of dependencies like YOLOx which are wanted for OCR and return object sorts based mostly on extracted information. Enabling extract_images_in_pdf will let unstructured extract embedded photographs from recordsdata. This will help implement multi-modal options.
Now, let’s discover the classes of components from our PDF.
# Create a dictionary to retailer counts of every kind
category_counts = {}
for factor in pdf_elements:
class = str(kind(factor))
if class in category_counts:
category_countsDatabase += 1
else:
category_countsDatabase = 1
# Unique_categories could have distinctive components
unique_categories = set(category_counts.keys())
category_countsOperating it will output factor classes and their rely.
Now, we separate the weather for straightforward dealing with. We create an Aspect kind that inherits from Langchain’s Doc kind. That is to make sure extra organized information, which is simpler to take care of.
from unstructured.paperwork.components import CompositeElement, Desk
from langchain.schema import Doc
class Aspect(Doc):
kind: str
# Categorize by kind
categorized_elements = []
for factor in pdf_elements:
if isinstance(factor, Desk):
categorized_elements.append(Aspect(kind="desk", page_content=str(factor)))
elif isinstance(factor, CompositeElement):
categorized_elements.append(Aspect(kind="textual content", page_content=str(factor)))
# Tables
table_elements = [e for e in categorized_elements if e.type == "table"]
# Textual content
text_elements = [e for e in categorized_elements if e.type == "text"]Multi-vector Retriever
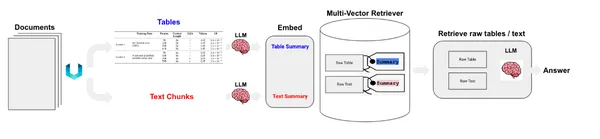
We now have desk and textual content components. Now, there are two methods we will deal with these. We will retailer the uncooked components in a doc retailer or retailer summaries of texts. Tables may pose a problem to semantic search; in that case, we create the summaries of tables and retailer them in a doc retailer together with the uncooked tables. To attain this, we are going to use MultiVectorRetriever. This retriever will handle a vector retailer the place we retailer the embeddings of abstract texts and a easy in-memory doc retailer to retailer uncooked paperwork.
First, construct a summarizing chain to summarize the desk and textual content information we extracted earlier.
from langchain.chat_models import cohere
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
prompt_text = """You're an assistant tasked with summarizing tables and textual content.
Give a concise abstract of the desk or textual content. Desk or textual content chunk: {factor} """
immediate = ChatPromptTemplate.from_template(prompt_text)
mannequin = cohere.ChatCohere(cohere_api_key="your_key")
summarize_chain = {"factor": lambda x: x} | immediate | mannequin | StrOutputParser()
tables = [i.page_content for i in table_elements]
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
texts = [i.page_content for i in text_elements]
text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})I’ve used Cohere LLM for summarizing information; you could use OpenAI fashions like GPT-4. Higher fashions will yield higher outcomes. Generally, the fashions might not completely seize desk particulars. So, it’s higher to make use of succesful fashions.
Now, we create the MultivectorRetriever.
from langchain.retrievers import MultiVectorRetriever
from langchain.prompts import ChatPromptTemplate
import uuid
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.doc import Doc
from langchain.storage import InMemoryStore
from langchain.vectorstores import Chroma
# The vectorstore to make use of to index the kid chunks
vectorstore = Chroma(collection_name="assortment",
embedding_function=OpenAIEmbeddings(openai_api_key="api_key"))
# The storage layer for the father or mother paperwork
retailer = InMemoryStore()
id_key = ""id"
# The retriever
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=retailer,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(record(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(record(zip(table_ids, tables)))
We used Chroma vector retailer for storing abstract embeddings of texts and tables and an in-memory doc retailer to retailer uncooked information.
RAG
Now that our retriever is prepared, we will construct an RAG pipeline utilizing Langchain Expression Language.
from langchain.schema.runnable import RunnablePassthrough
# Immediate template
template = """Reply the query based mostly solely on the next context,
which might embrace textual content and tables::
{context}
Query: {query}
"""
immediate = ChatPromptTemplate.from_template(template)
# LLM
mannequin = ChatOpenAI(temperature=0.0, openai_api_key="api_key")
# RAG pipeline
chain = (
{"context": retriever, "query": RunnablePassthrough()}
| immediate
| mannequin
| StrOutputParser()
)
Now, we will ask questions and obtain solutions based mostly on retrieved embeddings from the vector retailer.
chain.invoke(enter = "What's the MT bench rating of Llama 2 and Mistral 7B Instruct??")Conclusion
A variety of data stays hidden in semi-structured information format. And it’s difficult to extract and carry out standard RAG on these information. On this article, we went from extracting texts and embedded tables within the PDF to constructing a multi-vector retriever and RAG pipeline with Langchain. So, listed below are the important thing takeaways from the article.
Key Takeaways
- Typical RAG usually faces challenges coping with semi-structured information, akin to breaking apart tables throughout textual content splitting and imprecise semantic searches.
- Unstructured, an open-source instrument for semi-structured information, can extract embedded tables from PDFs or comparable semi-structured information.
- With Langchain, we will construct a multi-vector retriever for storing tables, texts, and summaries in doc shops for higher semantic search.
Incessantly Requested Questions
A: Semi-structured information, not like structured information, doesn’t have a inflexible schema however has different types of markers to implement hierarchies.
A. Semi-structured information examples are CSV, Emails, HTML, XML, parquet recordsdata, and so forth.
A. LangChain is an open-source framework that simplifies the creation of purposes utilizing giant language fashions. It may be used for varied duties, together with chatbots, RAG, question-answering, and generative duties.
A. A RAG pipeline retrieves paperwork from exterior information shops, processes them to retailer them in a information base, and supplies instruments to question them.
A. Llama Index explicitly designs search and retrieval purposes, whereas Langchain affords flexibility for creating customized AI brokers.
The media proven on this article is just not owned by Analytics Vidhya and is used on the Creator’s discretion.
Associated
[ad_2]