
[ad_1]
Boba is an experimental AI co-pilot for product technique & generative ideation,
designed to enhance the artistic ideation course of. It’s an LLM-powered
software that we’re constructing to study:
An AI co-pilot refers to a synthetic intelligence-powered assistant designed
to assist customers with varied duties, usually offering steering, assist, and automation
in several contexts. Examples of its software embody navigation methods,
digital assistants, and software program improvement environments. We like to consider a co-pilot
as an efficient companion {that a} person can collaborate with to carry out a particular area
of duties.
Boba as an AI co-pilot is designed to enhance the early phases of technique ideation and
idea technology, which rely closely on speedy cycles of divergent
pondering (also referred to as generative ideation). We sometimes implement generative ideation
by carefully collaborating with our friends, prospects and material specialists, in order that we are able to
formulate and check progressive concepts that handle our prospects’ jobs, pains and features.
This begs the query, what if AI might additionally take part in the identical course of? What if we
might generate and consider extra and higher concepts, quicker in partnership with AI? Boba begins to
allow this through the use of OpenAI’s LLM to generate concepts and reply questions
that may assist scale and speed up the artistic pondering course of. For the primary prototype of
Boba, we determined to deal with rudimentary variations of the next capabilities:
1. Analysis indicators and developments: Search the net for
articles and information that will help you reply qualitative analysis questions,
like:
2. Inventive Matrix: The artistic matrix is a concepting technique for
sparking new concepts on the intersections of distinct classes or
dimensions. This includes stating a strategic immediate, usually as a “How would possibly
we” query, after which answering that query for every
mixture/permutation of concepts on the intersection of every dimension. For
instance:
3. Situation constructing: Situation constructing is a means of
producing future-oriented tales by researching indicators of change in
enterprise, tradition, and expertise. Eventualities are used to socialize learnings
in a contextualized narrative, encourage divergent product pondering, conduct
resilience/desirability testing, and/or inform strategic planning. For
instance, you’ll be able to immediate Boba with the next and get a set of future
situations based mostly on completely different time horizons and ranges of optimism and
realism:
4. Technique ideation: Utilizing the Taking part in to Win technique
framework, brainstorm “the place to play” and “easy methods to win” decisions
based mostly on a strategic immediate and attainable future situations. For instance you
can immediate it with:
5. Idea technology: Based mostly on a strategic immediate, reminiscent of a “how would possibly we” query, generate
a number of product or characteristic ideas, which embody worth proposition pitches and hypotheses to check.
6. Storyboarding: Generate visible storyboards based mostly on a easy
immediate or detailed narrative based mostly on present or future state situations. The
key options are:
Utilizing Boba
Boba is an online software that mediates an interplay between a human
person and a Giant-Language Mannequin, at the moment GPT 3.5. A easy internet
front-end to an LLM simply provides the flexibility for the person to converse with
the LLM. That is useful, however means the person must learn to
successfully work together the LLM. Even within the brief time that LLMs have seized
the general public curiosity, we have discovered that there’s appreciable ability to
developing the prompts to the LLM to get a helpful reply, leading to
the notion of a “Immediate Engineer”. A co-pilot software like Boba provides
a variety of UI components that construction the dialog. This permits a person
to make naive prompts which the appliance can manipulate, enriching
easy requests with components that can yield a greater response from the
LLM.
Boba may help with various product technique duties. We can’t
describe all of them right here, simply sufficient to provide a way of what Boba does and
to offer context for the patterns later within the article.
When a person navigates to the Boba software, they see an preliminary
display screen just like this
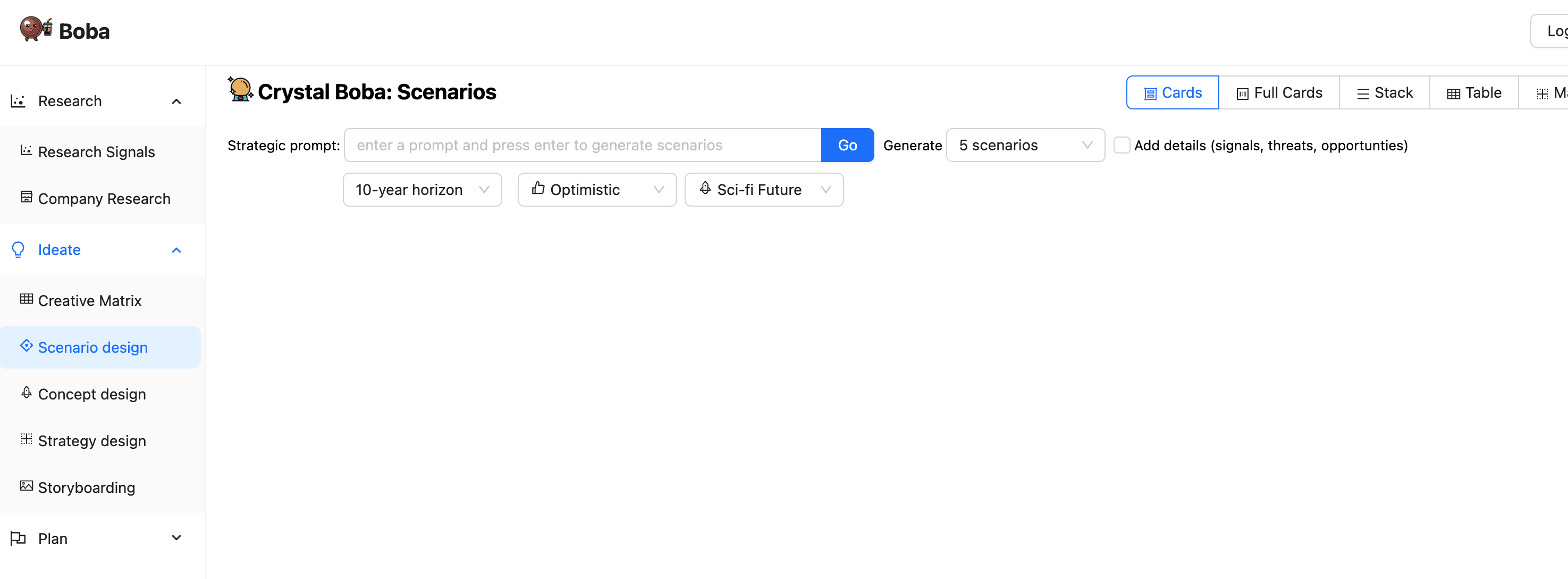
The left panel lists the varied product technique duties that Boba
helps. Clicking on one in every of these modifications the primary panel to the UI for
that process. For the remainder of the screenshots, we’ll ignore that process panel
on the left.
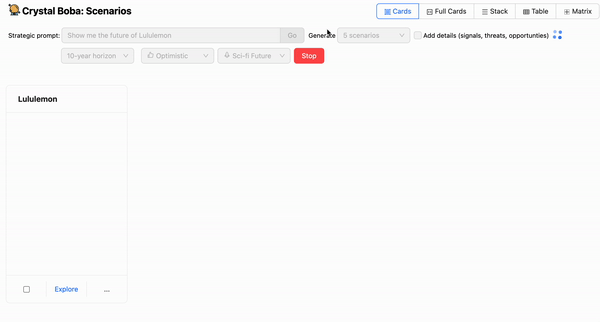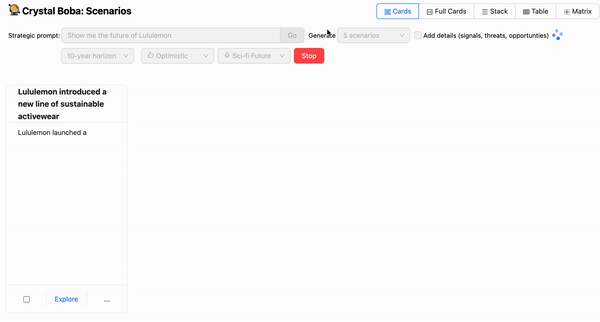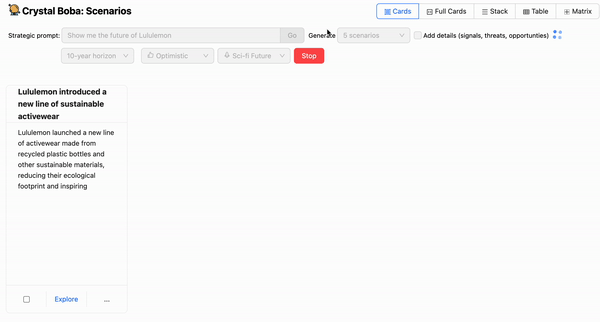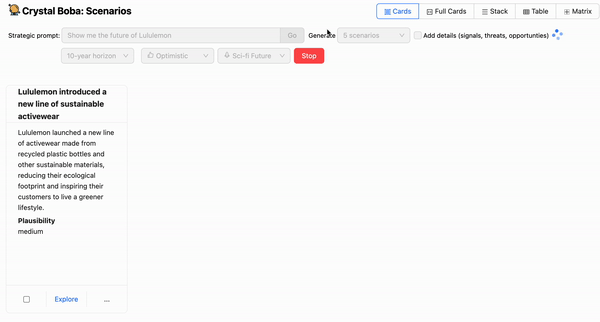
The above screenshot seems on the situation design process. This invitations
the person to enter a immediate, reminiscent of “Present me the way forward for retail”.
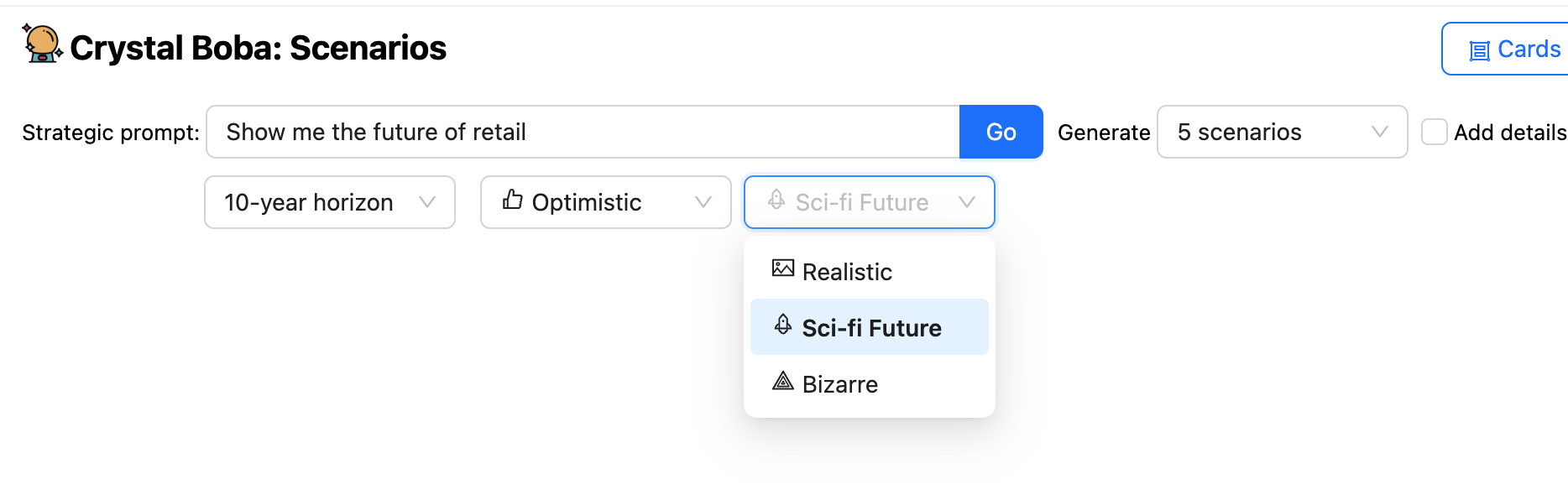
The UI provides various drop-downs along with the immediate, permitting
the person to recommend time-horizons and the character of the prediction. Boba
will then ask the LLM to generate situations, utilizing Templated Immediate to counterpoint the person’s immediate
with extra components each from normal data of the situation
constructing process and from the person’s alternatives within the UI.
Boba receives a Structured Response from the LLM and shows the
consequence as set of UI components for every situation.
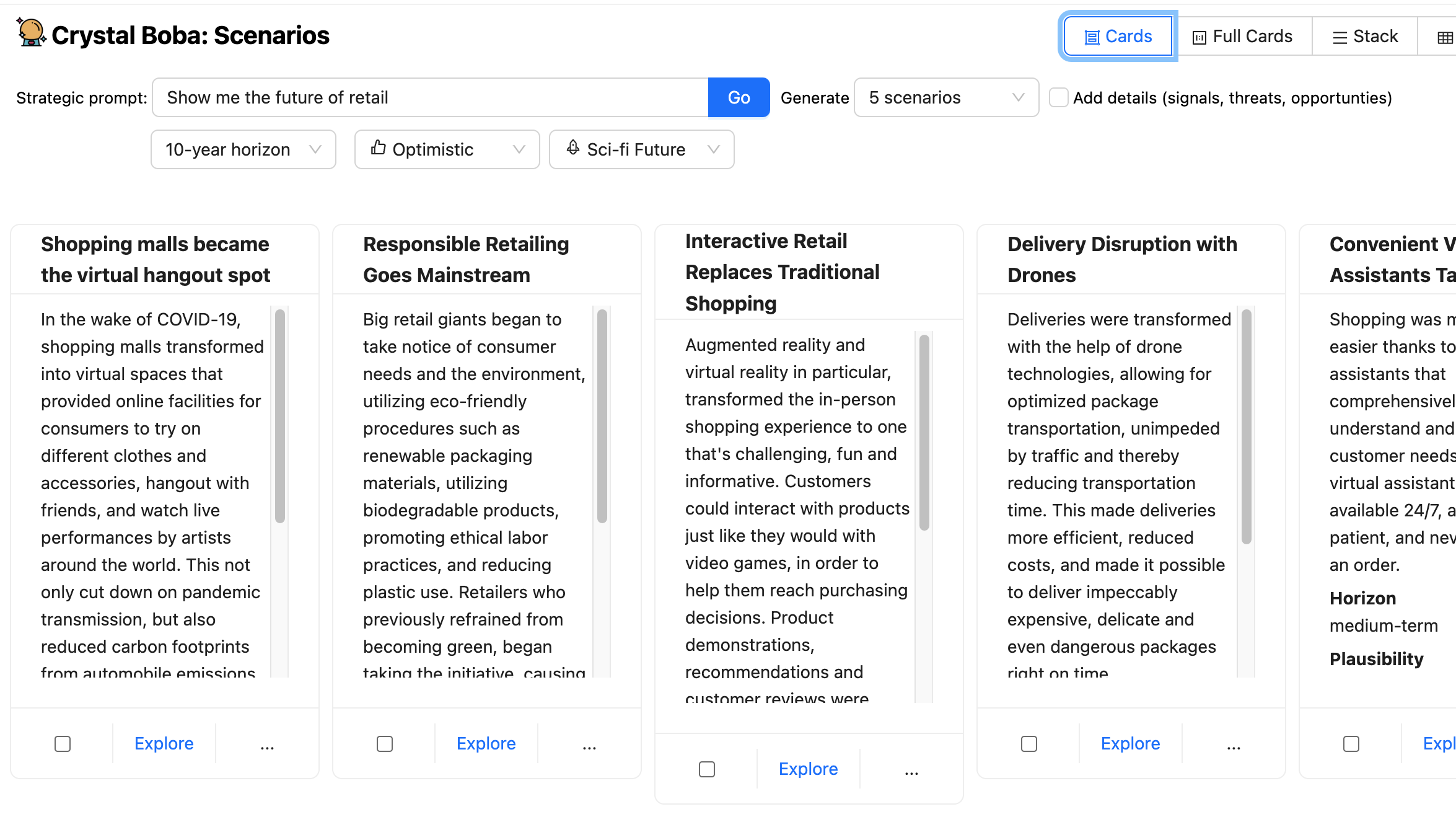
The person can then take one in every of these situations and hit the discover
button, citing a brand new panel with an additional immediate to have a Contextual Dialog with Boba.
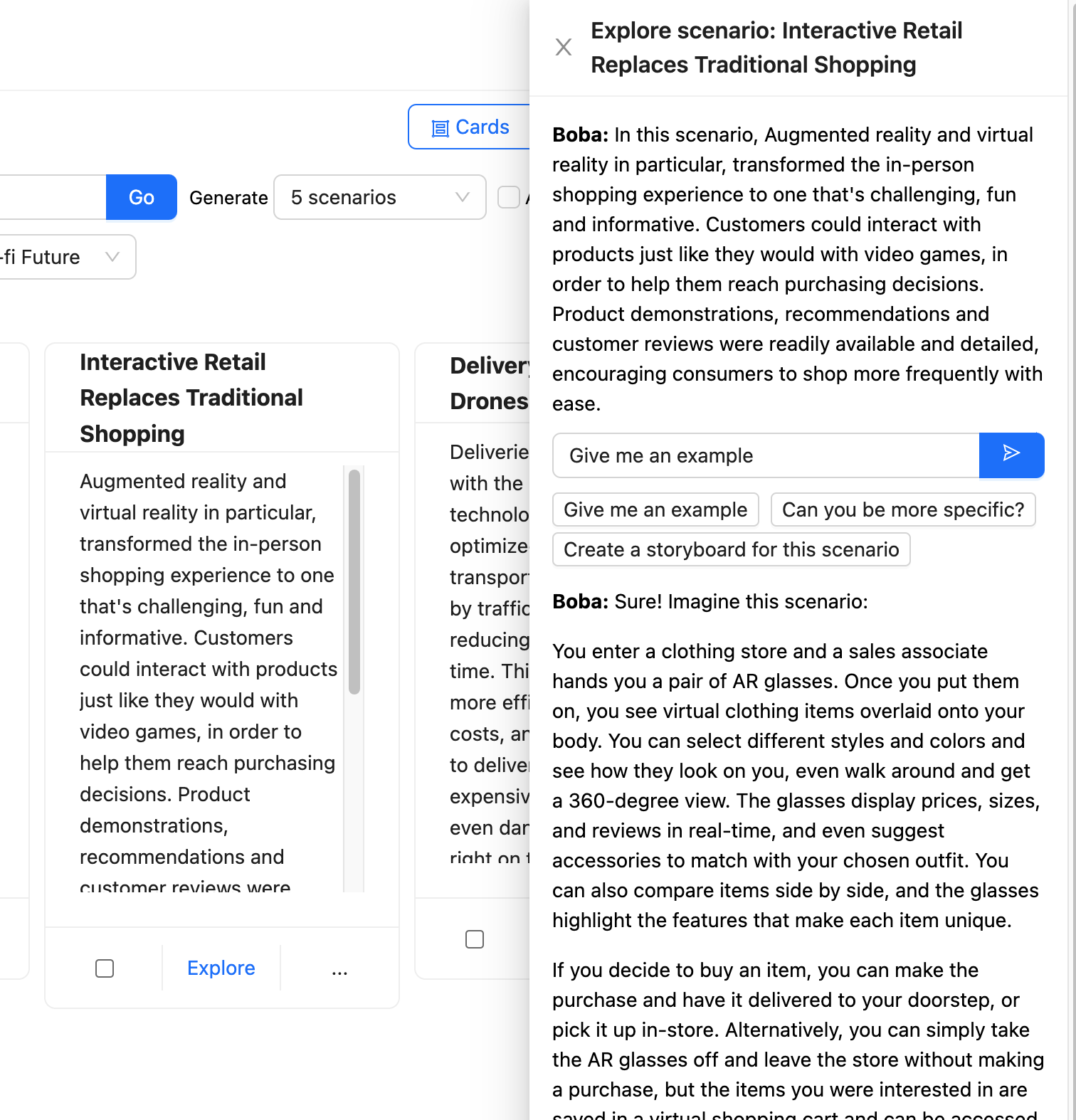
Boba takes this immediate and enriches it to deal with the context of the
chosen situation earlier than sending it to the LLM.
Boba makes use of Choose and Carry Context
to carry onto the varied components of the person’s interplay
with the LLM, permitting the person to discover in a number of instructions with out
having to fret about supplying the appropriate context for every interplay.
One of many difficulties with utilizing an
LLM is that it is skilled solely on knowledge as much as some level prior to now, making
them ineffective for working with up-to-date data. Boba has a
characteristic known as analysis indicators that makes use of Embedded Exterior Information
to mix the LLM with common search
amenities. It takes the prompted analysis question, reminiscent of “How is the
lodge trade utilizing generative AI in the present day?”, sends an enriched model of
that question to a search engine, retrieves the advised articles, sends
every article to the LLM to summarize.
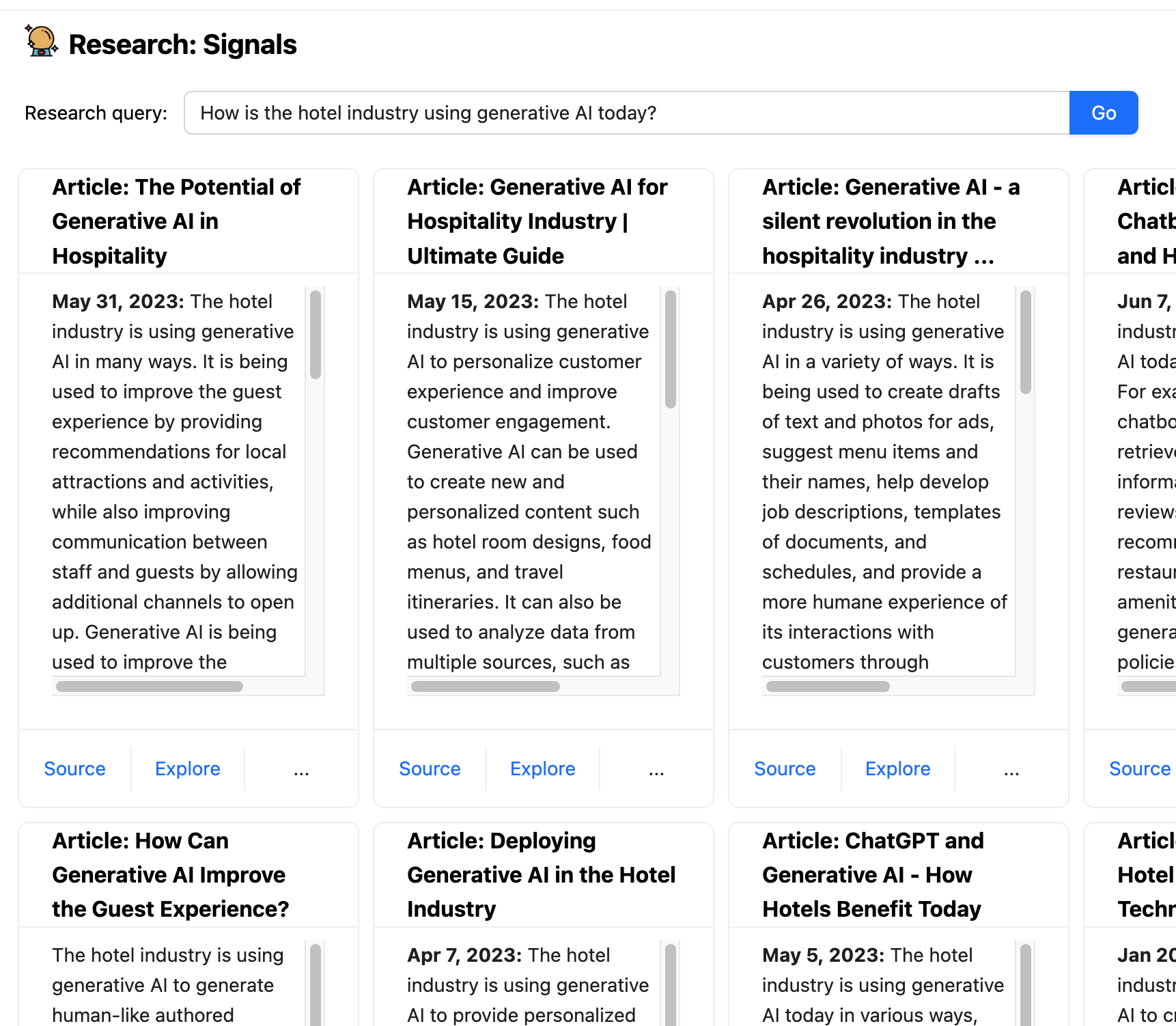
That is an instance of how a co-pilot software can deal with
interactions that contain actions that an LLM alone is not appropriate for. Not
simply does this present up-to-date data, we are able to additionally guarantee we
present supply hyperlinks to the person, and people hyperlinks will not be hallucinations
(so long as the search engine is not partaking of the unsuitable mushrooms).
Some patterns for constructing generative co-pilot purposes
In constructing Boba, we learnt quite a bit about completely different patterns and approaches
to mediating a dialog between a person and an LLM, particularly Open AI’s
GPT3.5/4. This listing of patterns isn’t exhaustive and is proscribed to the teachings
we have learnt up to now whereas constructing Boba.
Templated Immediate
Use a textual content template to counterpoint a immediate with context and construction
The primary and easiest sample is utilizing a string templates for the prompts, additionally
often called chaining. We use Langchain, a library that gives a typical
interface for chains and end-to-end chains for widespread purposes out of
the field. For those who’ve used a Javascript templating engine, reminiscent of Nunjucks,
EJS or Handlebars earlier than, Langchain offers simply that, however is designed particularly for
widespread immediate engineering workflows, together with options for perform enter variables,
few-shot immediate templates, immediate validation, and extra refined composable chains of prompts.
For instance, to brainstorm potential future situations in Boba, you’ll be able to
enter a strategic immediate, reminiscent of “Present me the way forward for funds” or perhaps a
easy immediate just like the identify of an organization. The person interface seems like
this:

The immediate template that powers this technology seems one thing like
this:
You're a visionary futurist. Given a strategic immediate, you'll create
{num_scenarios} futuristic, hypothetical situations that occur
{time_horizon} from now. Every situation should be a {optimism} model of the
future. Every situation should be {realism}.
Strategic immediate: {strategic_prompt}
As you’ll be able to think about, the LLM’s response will solely be nearly as good because the immediate
itself, so that is the place the necessity for good immediate engineering is available in.
Whereas this text isn’t meant to be an introduction to immediate
engineering, you’ll discover some strategies at play right here, reminiscent of beginning
by telling the LLM to Undertake a
Persona,
particularly that of a visionary futurist. This was a way we relied on
extensively in varied components of the appliance to provide extra related and
helpful completions.
As a part of our test-and-learn immediate engineering workflow, we discovered that
iterating on the immediate immediately in ChatGPT provides the shortest path from
concept to experimentation and helps construct confidence in our prompts shortly.
Having stated that, we additionally discovered that we spent far more time on the person
interface (about 80%) than the AI itself (about 20%), particularly in
engineering the prompts.
We additionally stored our immediate templates so simple as attainable, devoid of
conditional statements. Once we wanted to drastically adapt the immediate based mostly
on the person enter, reminiscent of when the person clicks “Add particulars (indicators,
threats, alternatives)”, we determined to run a unique immediate template
altogether, within the curiosity of retaining our immediate templates from changing into
too complicated and arduous to take care of.
Structured Response
Inform the LLM to reply in a structured knowledge format
Virtually any software you construct with LLMs will more than likely must parse
the output of the LLM to create some structured or semi-structured knowledge to
additional function on on behalf of the person. For Boba, we needed to work with
JSON as a lot as attainable, so we tried many various variations of getting
GPT to return well-formed JSON. We have been fairly shocked by how nicely and
persistently GPT returns well-formed JSON based mostly on the directions in our
prompts. For instance, right here’s what the situation technology response
directions would possibly appear like:
You'll reply with solely a legitimate JSON array of situation objects.
Every situation object could have the next schema:
"title": <string>, //Have to be a whole sentence written prior to now tense
"abstract": <string>, //Situation description
"plausibility": <string>, //Plausibility of situation
"horizon": <string>
We have been equally shocked by the truth that it might assist pretty complicated
nested JSON schemas, even once we described the response schemas in pseudo-code.
Right here’s an instance of how we would describe a nested response for technique
technology:
You'll reply in JSON format containing two keys, "questions" and "methods", with the respective schemas beneath:
"questions": [<list of question objects, with each containing the following keys:>]
"query": <string>,
"reply": <string>
"methods": [<list of strategy objects, with each containing the following keys:>]
"title": <string>,
"abstract": <string>,
"problem_diagnosis": <string>,
"winning_aspiration": <string>,
"where_to_play": <string>,
"how_to_win": <string>,
"assumptions": <string>
An fascinating facet impact of describing the JSON response schema was that we
might additionally nudge the LLM to offer extra related responses within the output. For
instance, for the Inventive Matrix, we wish the LLM to consider many various
dimensions (the immediate, the row, the columns, and every concept that responds to the
immediate on the intersection of every row and column):
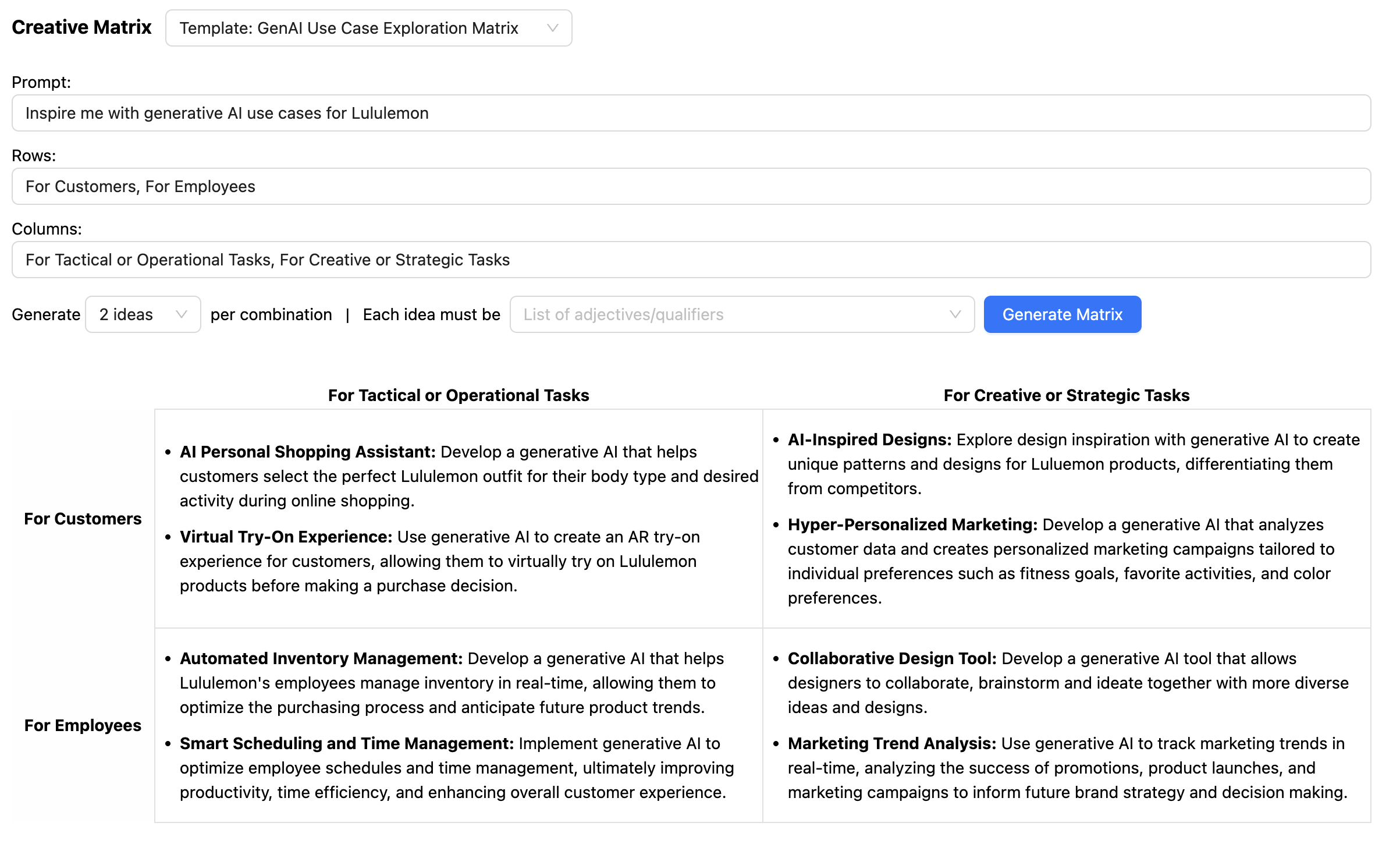
By offering a few-shot immediate that features a particular instance of the output
schema, we have been in a position to get the LLM to “assume” in the appropriate context for every
concept (the context being the immediate, row and column):
You'll reply with a legitimate JSON array, by row by column by concept. For instance:
If Rows = "row 0, row 1" and Columns = "column 0, column 1" then you'll reply
with the next:
[
{{
"row": "row 0",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 0 and column 0",
"description": "idea 0 for prompt and row 0 and column 0"
}}
]
}},
{{
"column": "column 1",
"concepts": [
{{
"title": "Idea 0 title for prompt and row 0 and column 1",
"description": "idea 0 for prompt and row 0 and column 1"
}}
]
}},
]
}},
{{
"row": "row 1",
"columns": [
{{
"column": "column 0",
"ideas": [
{{
"title": "Idea 0 title for prompt and row 1 and column 0",
"description": "idea 0 for prompt and row 1 and column 0"
}}
]
}},
{{
"column": "column 1",
"concepts": [
{{
"title": "Idea 0 title for prompt and row 1 and column 1",
"description": "idea 0 for prompt and row 1 and column 1"
}}
]
}}
]
}}
]
We might have alternatively described the schema extra succinctly and
typically, however by being extra elaborate and particular in our instance, we
efficiently nudged the standard of the LLM’s response within the route we
needed. We consider it’s because LLMs “assume” in tokens, and outputting (ie
repeating) the row and column values earlier than outputting the concepts offers extra
correct context for the concepts being generated.
On the time of this writing, OpenAI has launched a brand new characteristic known as
Perform
Calling, which
offers a unique option to obtain the purpose of formatting responses. On this
strategy, a developer can describe callable perform signatures and their
respective schemas as JSON, and have the LLM return a perform name with the
respective parameters offered in JSON that conforms to that schema. That is
significantly helpful in situations once you wish to invoke exterior instruments, reminiscent of
performing an online search or calling an API in response to a immediate. Langchain
additionally offers comparable performance, however I think about they may quickly present native
integration between their exterior instruments API and the OpenAI perform calling
API.
Actual-Time Progress
Stream the response to the UI so customers can monitor progress
One of many first few stuff you’ll notice when implementing a graphical
person interface on high of an LLM is that ready for all the response to
full takes too lengthy. We don’t discover this as a lot with ChatGPT as a result of
it streams the response character by character. This is a vital person
interplay sample to remember as a result of, in our expertise, a person can
solely wait on a spinner for therefore lengthy earlier than shedding persistence. In our case, we
didn’t need the person to attend quite a lot of seconds earlier than they began
seeing a response, even when it was a partial one.
Therefore, when implementing a co-pilot expertise, we extremely advocate
exhibiting real-time progress throughout the execution of prompts that take extra
than a couple of seconds to finish. In our case, this meant streaming the
generations throughout the complete stack, from the LLM again to the UI in real-time.
Happily, the Langchain and OpenAI APIs present the flexibility to just do
that:
const chat = new ChatOpenAI({
temperature: 1,
modelName: 'gpt-3.5-turbo',
streaming: true,
callbackManager: onTokenStream ?
CallbackManager.fromHandlers({
async handleLLMNewToken(token) {
onTokenStream(token)
},
}) : undefined
});
This allowed us to offer the real-time progress wanted to create a smoother
expertise for the person, together with the flexibility to cease a technology
mid-completion if the concepts being generated didn’t match the person’s
expectations:
Nevertheless, doing so provides a number of extra complexity to your software
logic, particularly on the view and controller. Within the case of Boba, we additionally had
to carry out best-effort parsing of JSON and preserve temporal state throughout the
execution of an LLM name. On the time of scripting this, some new and promising
libraries are popping out that make this simpler for internet builders. For instance,
the Vercel AI SDK is a library for constructing
edge-ready AI-powered streaming textual content and chat UIs.
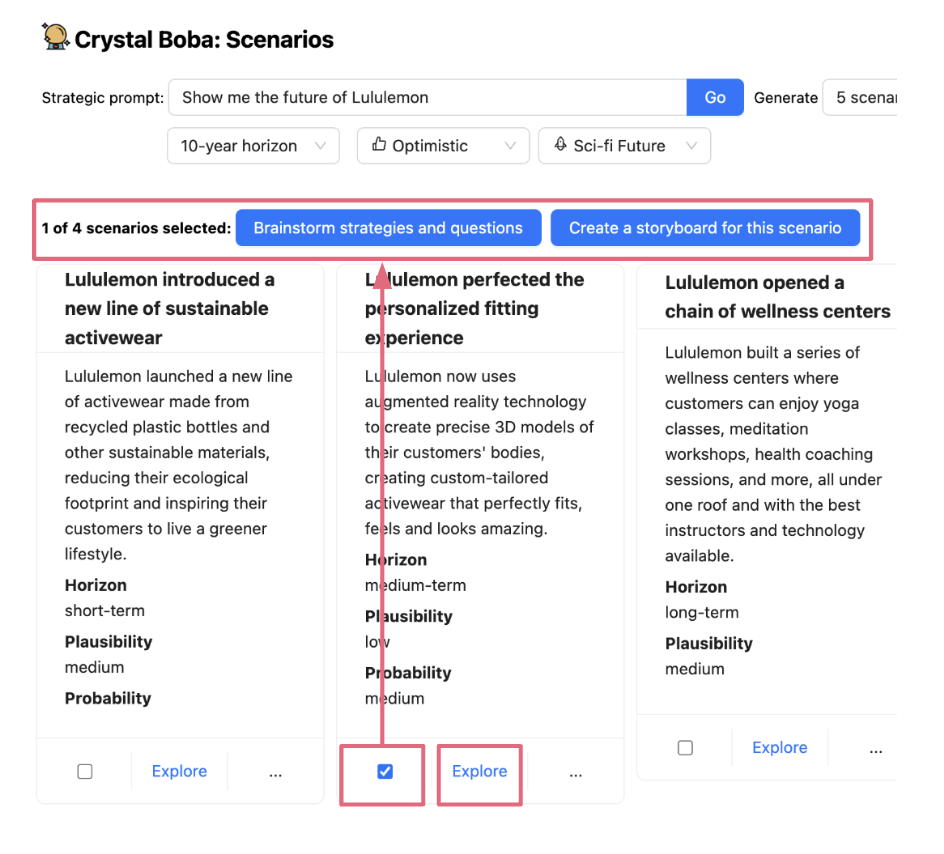
Choose and Carry Context
Seize and add related context data to subsequent motion
One of many greatest limitations of a chat interface is {that a} person is
restricted to a single-threaded context: the dialog chat window. When
designing a co-pilot expertise, we advocate pondering deeply about easy methods to
design UX affordances for performing actions throughout the context of a
choice, just like our pure inclination to level at one thing in actual
life within the context of an motion or description.
Choose and Carry Context permits the person to slim or broaden the scope of
interplay to carry out subsequent duties – also referred to as the duty context. That is sometimes
completed by choosing a number of components within the person interface after which performing an motion on them.
Within the case of Boba, for instance, we use this sample to permit the person to have
a narrower, targeted dialog about an concept by choosing it (eg a situation, technique or
prototype idea), in addition to to pick and generate variations of a
idea. First, the person selects an concept (both explicitly with a checkbox or implicitly by clicking a hyperlink):
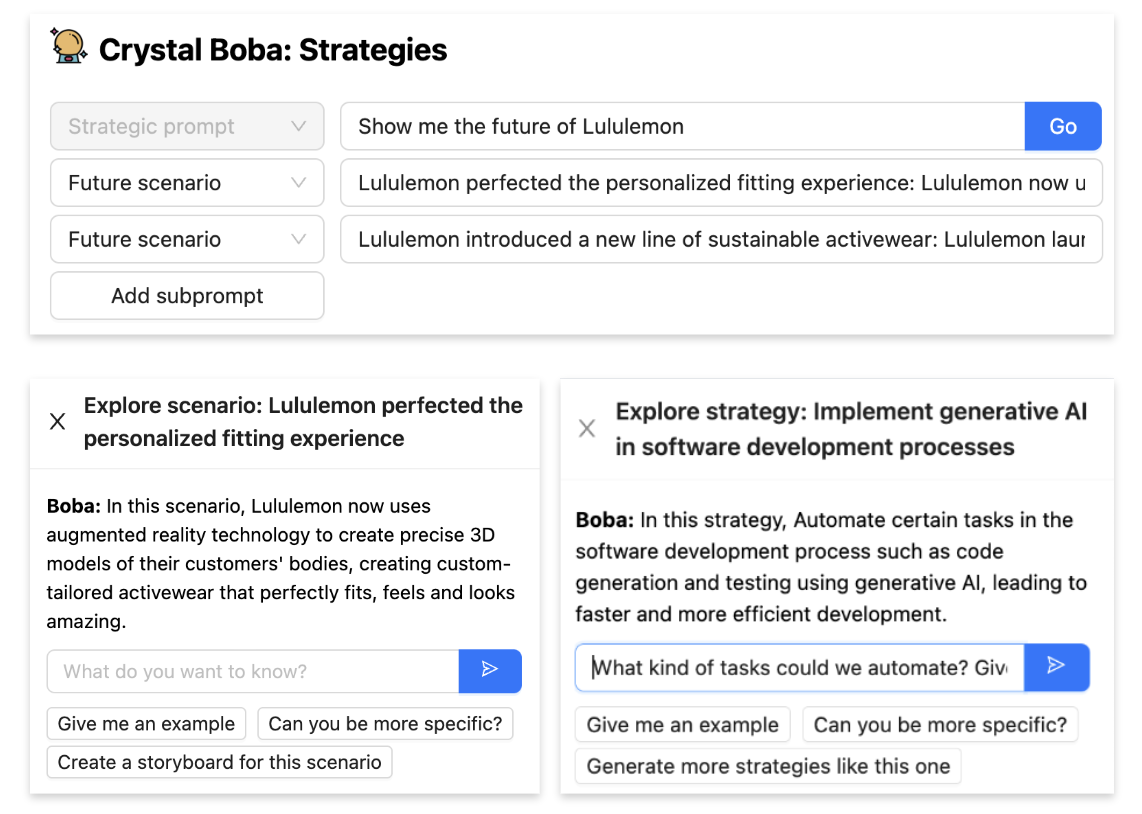
Then, when the person performs an motion on the choice, the chosen merchandise(s) are carried over as context into the brand new process,
for instance as situation subprompts for technique technology when the person clicks “Brainstorm methods and questions for this situation”,
or as context for a pure language dialog when the person clicks Discover:
Relying on the character and size of the context
you want to set up for a phase of dialog/interplay, implementing
Choose and Carry Context may be wherever from very simple to very troublesome. When
the context is transient and might match right into a single LLM context window (the utmost
dimension of a immediate that the LLM helps), we are able to implement it by way of immediate
engineering alone. For instance, in Boba, as proven above, you’ll be able to click on “Discover”
on an concept and have a dialog with Boba about that concept. The best way we
implement this within the backend is to create a multi-message chat
dialog:
const chatPrompt = ChatPromptTemplate.fromPromptMessages([
HumanMessagePromptTemplate.fromTemplate(contextPrompt),
HumanMessagePromptTemplate.fromTemplate("{input}"),
]);
const formattedPrompt = await chatPrompt.formatPromptValue({
enter: enter
})
One other strategy of implementing Choose and Carry Context is to take action inside
the immediate by offering the context inside tag delimiters, as proven beneath. In
this case, the person has chosen a number of situations and desires to generate
methods for these situations (a way usually utilized in situation constructing and
stress testing of concepts). The context we wish to carry into the technique
technology is assortment of chosen situations:
Your questions and techniques should be particular to realizing the next
potential future situations (if any)
<situations>
{scenarios_subprompt}
</situations>
Nevertheless, when your context outgrows an LLM’s context window, or in case you want
to offer a extra refined chain of previous interactions, you might have to
resort to utilizing exterior short-term reminiscence, which generally includes utilizing a
vector retailer (in-memory or exterior). We’ll give an instance of easy methods to do
one thing comparable in Embedded Exterior Information.
If you wish to study extra in regards to the efficient use of choice and
context in generative purposes, we extremely advocate a chat given by
Linus Lee, of Notion, on the LLMs in Manufacturing convention: “Generative Experiences Past Chat”.
Contextual Dialog
Permit direct dialog with the LLM inside a context.
This can be a particular case of Choose and Carry Context.
Whereas we needed Boba to interrupt out of the chat window interplay mannequin
as a lot as attainable, we discovered that it’s nonetheless very helpful to offer the
person a “fallback” channel to converse immediately with the LLM. This permits us
to offer a conversational expertise for interactions we don’t assist in
the UI, and assist instances when having a textual pure language
dialog does take advantage of sense for the person.
Within the instance beneath, the person is chatting with Boba a couple of idea for
personalised spotlight reels offered by Rogers Sportsnet. The whole
context is talked about as a chat message (“On this idea, Uncover a world of
sports activities you’re keen on…”), and the person has requested Boba to create a person journey for
the idea. The response from the LLM is formatted and rendered as Markdown:
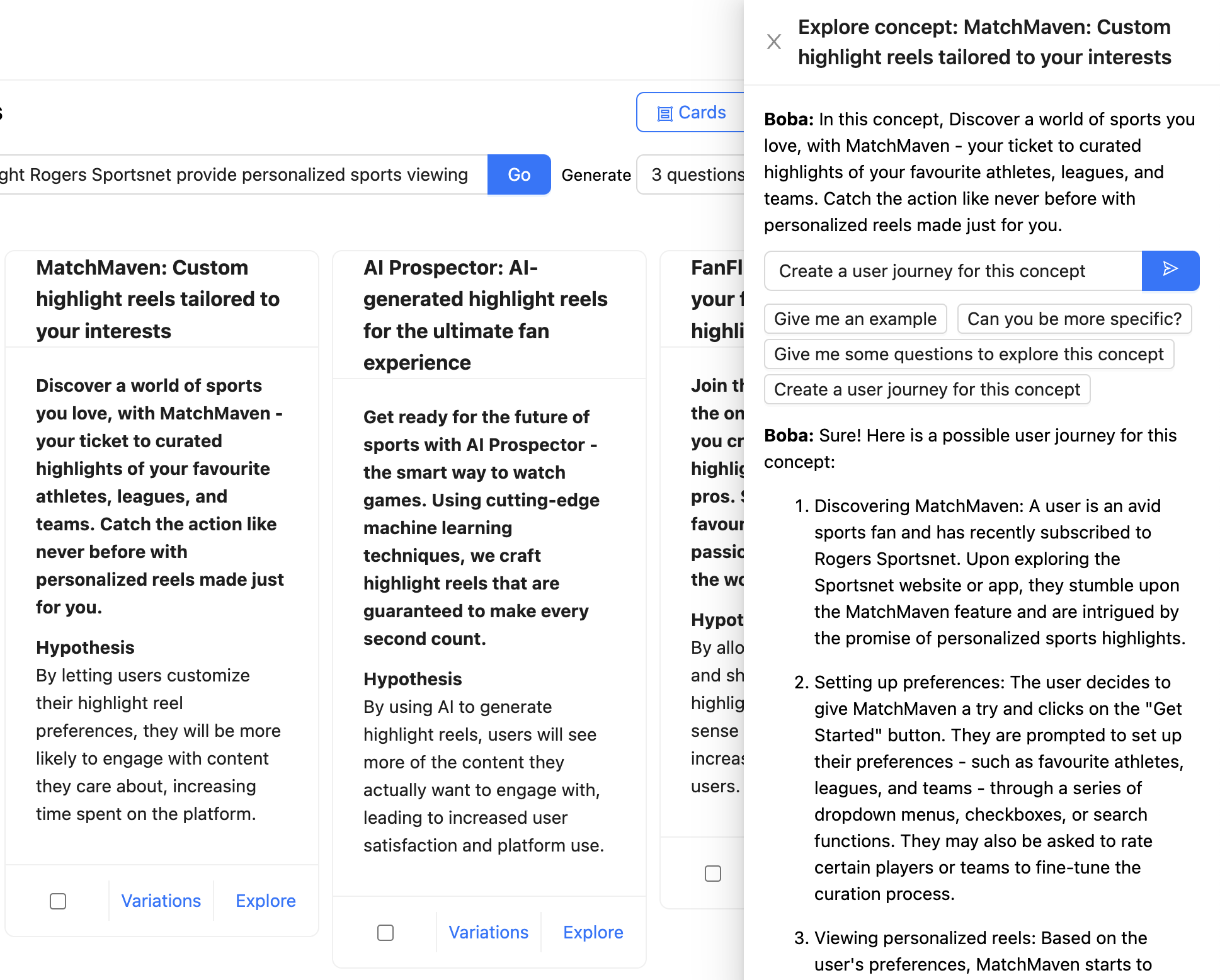
When designing generative co-pilot experiences, we extremely advocate
supporting contextual conversations along with your software. Ensure that to
provide examples of helpful messages the person can ship to your software so
they know what sort of conversations they’ll interact in. Within the case of
Boba, as proven within the screenshot above, these examples are provided as
message templates underneath the enter field, reminiscent of “Are you able to be extra
particular?”
Out-Loud Pondering
Inform LLM to generate intermediate outcomes whereas answering
Whereas LLMs don’t really “assume”, it’s value pondering metaphorically
a couple of phrase by Andrei Karpathy of OpenAI: “LLMs ‘assume’ in
tokens.” What he means by this
is that GPTs are inclined to make extra reasoning errors when making an attempt to reply a
query instantly, versus once you give them extra time (i.e. extra tokens)
to “assume”. In constructing Boba, we discovered that utilizing Chain of Thought (CoT)
prompting, or extra particularly, asking for a sequence of reasoning earlier than an
reply, helped the LLM to purpose its manner towards higher-quality and extra
related responses.
In some components of Boba, like technique and idea technology, we ask the
LLM to generate a set of questions that increase on the person’s enter immediate
earlier than producing the concepts (methods and ideas on this case).
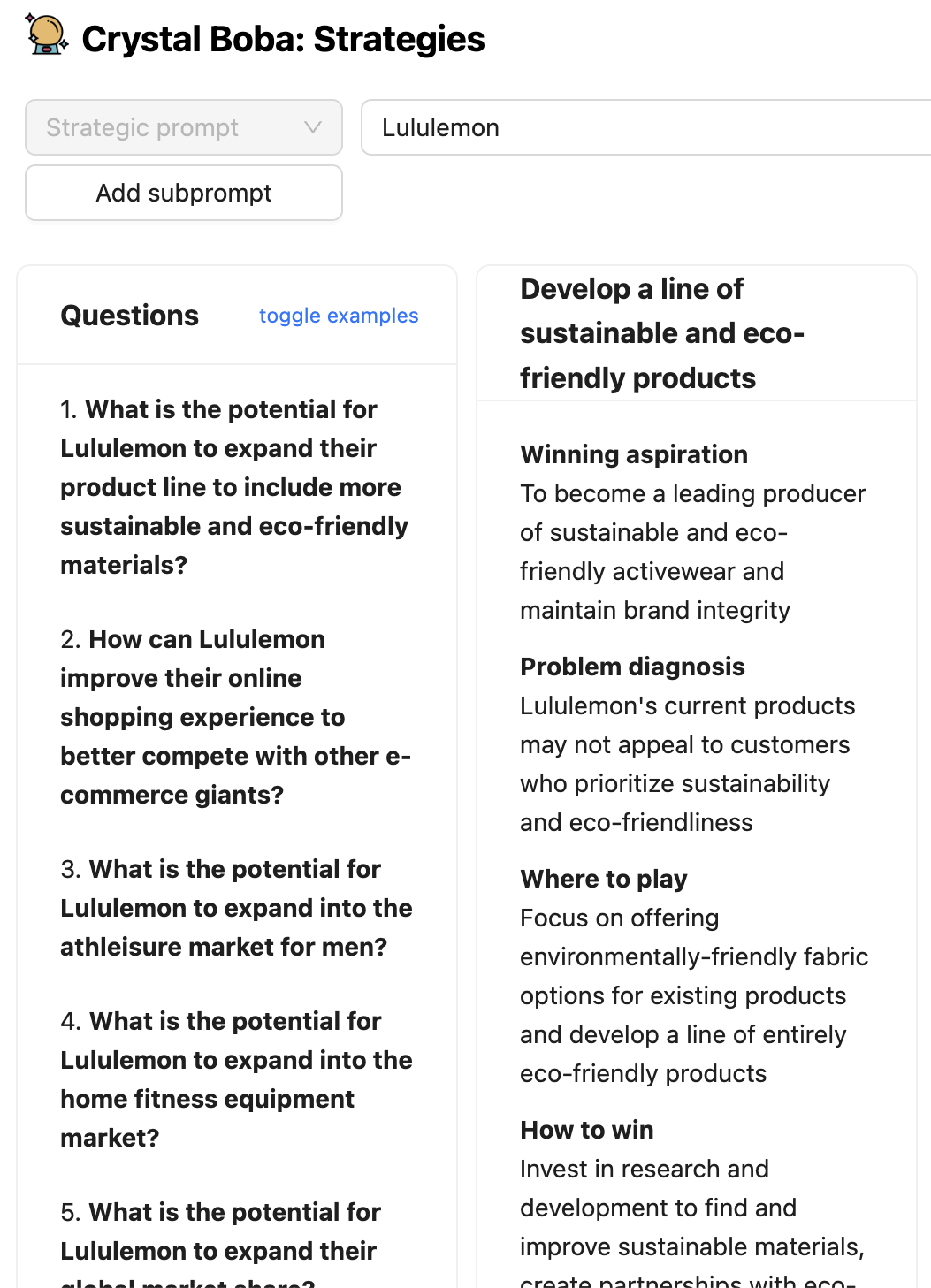
Whereas we show the questions generated by the LLM, an equally efficient
variant of this sample is to implement an inner monologue that the person is
not uncovered to. On this case, we might ask the LLM to assume by way of their
response and put that inside monologue right into a separate a part of the response, that
we are able to parse out and ignore within the outcomes we present to the person. A extra elaborate
description of this sample may be present in OpenAI’s GPT Finest Practices
Information, within the
part Give GPTs time to
“assume”
As a person expertise sample for generative purposes, we discovered it useful
to share the reasoning course of with the person, wherever applicable, in order that the
person has extra context to iterate on the following motion or immediate. For
instance, in Boba, understanding the sorts of questions that Boba considered provides the
person extra concepts about divergent areas to discover, or to not discover. It additionally
permits the person to ask Boba to exclude sure lessons of concepts within the subsequent
iteration. For those who do go down this path, we advocate making a UI affordance
for hiding a monologue or chain of thought, reminiscent of Boba’s characteristic to toggle
examples proven above.
Iterative Response
Present affordances for the person to have a back-and-forth
interplay with the co-pilot
LLMs are certain to both misunderstand the person’s intent or just
generate responses that don’t meet the person’s expectations. Therefore, so is
your generative software. One of the highly effective capabilities that
distinguishes ChatGPT from conventional chatbots is the flexibility to flexibly
iterate on and refine the route of the dialog, and therefore enhance
the standard and relevance of the responses generated.
Equally, we consider that the standard of a generative co-pilot
expertise depends upon the flexibility of a person to have a fluid back-and-forth
interplay with the co-pilot. That is what we name the Iterate on Response
sample. This may contain a number of approaches:
- Correcting the unique enter offered to the appliance/LLM
- Refining part of the co-pilot’s response to the person
- Offering suggestions to nudge the appliance in a unique route
One instance of the place we’ve applied Iterative Response
in
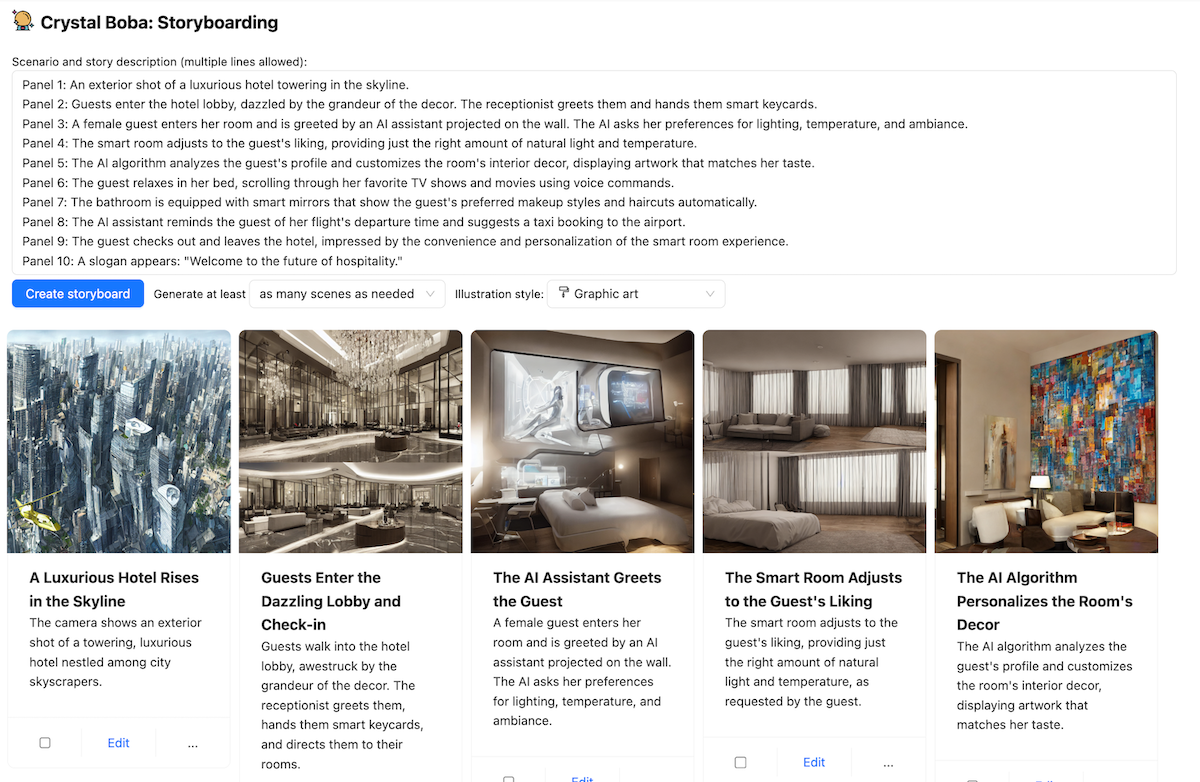
Boba is in Storyboarding. Given a immediate (both transient or elaborate), Boba
can generate a visible storyboard, which incorporates a number of scenes, with every
scene having a story script and a picture generated with Steady
Diffusion. For instance, beneath is a partial storyboard describing the expertise of a
“Resort of the Future”:
Since Boba makes use of the LLM to generate the Steady Diffusion immediate, we don’t
understand how good the photographs will end up–so it’s a little bit of a hit and miss with
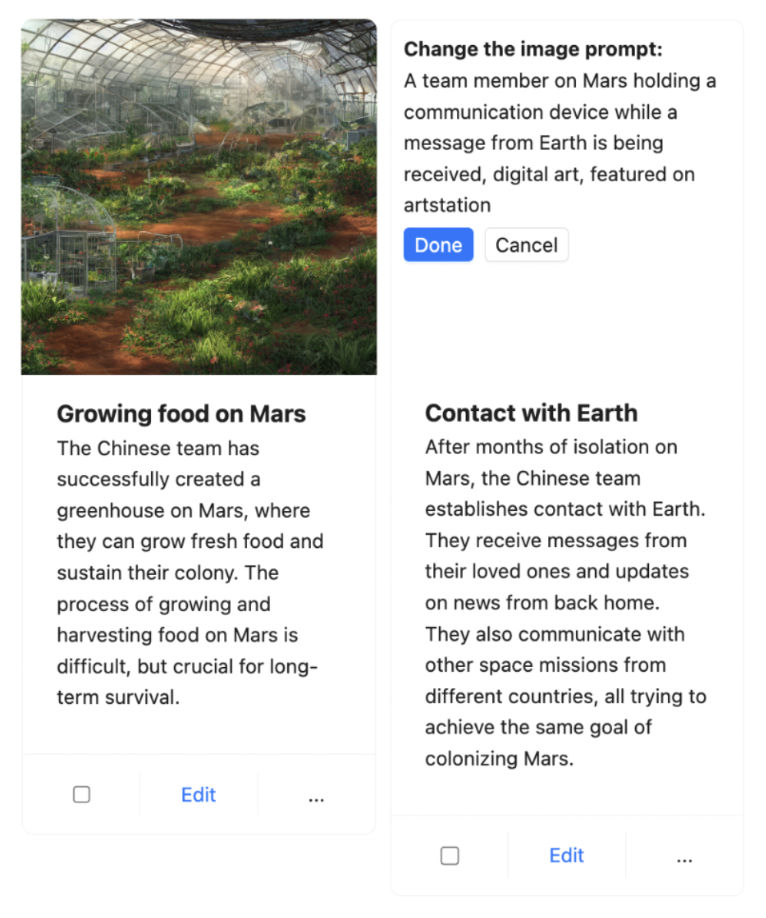
this characteristic. To compensate for this, we determined to offer the person the
means to iterate on the picture immediate in order that they’ll refine the picture for
a given scene. The person would do that by merely clicking on the picture,
updating the Steady Diffusion immediate, and urgent Achieved, upon which Boba
would generate a brand new picture with the up to date immediate, whereas preserving the
remainder of the storyboard:
One other instance Iterative Response that we
are at the moment engaged on is a characteristic for the person to offer suggestions
to Boba on the standard of concepts generated, which might be a mix
of Choose and Carry Context and Iterative Response. One
strategy could be to provide a thumbs up or thumbs down on an concept, and
letting Boba incorporate that suggestions into a brand new or subsequent set of
suggestions. One other strategy could be to offer conversational
suggestions within the type of pure language. Both manner, we want to
do that in a method that helps reinforcement studying (the concepts get
higher as you present extra suggestions). A superb instance of this could be
Github Copilot, which demotes code recommendations which have been ignored by
the person in its rating of subsequent greatest code recommendations.
We consider that this is among the most essential, albeit
generically-framed, patterns to implementing efficient generative
experiences. The difficult half is incorporating the context of the
suggestions into subsequent responses, which is able to usually require implementing
short-term or long-term reminiscence in your software due to the restricted
dimension of context home windows.
Embedded Exterior Information
Mix LLM with different data sources to entry knowledge past
the LLM’s coaching set
As alluded to earlier on this article, oftentimes your generative
purposes will want the LLM to include exterior instruments (reminiscent of an API
name) or exterior reminiscence (short-term or long-term). We bumped into this
situation once we have been implementing the Analysis characteristic in Boba, which
permits customers to reply qualitative analysis questions based mostly on publicly
accessible data on the net, for instance “How is the lodge trade
utilizing generative AI in the present day?”:
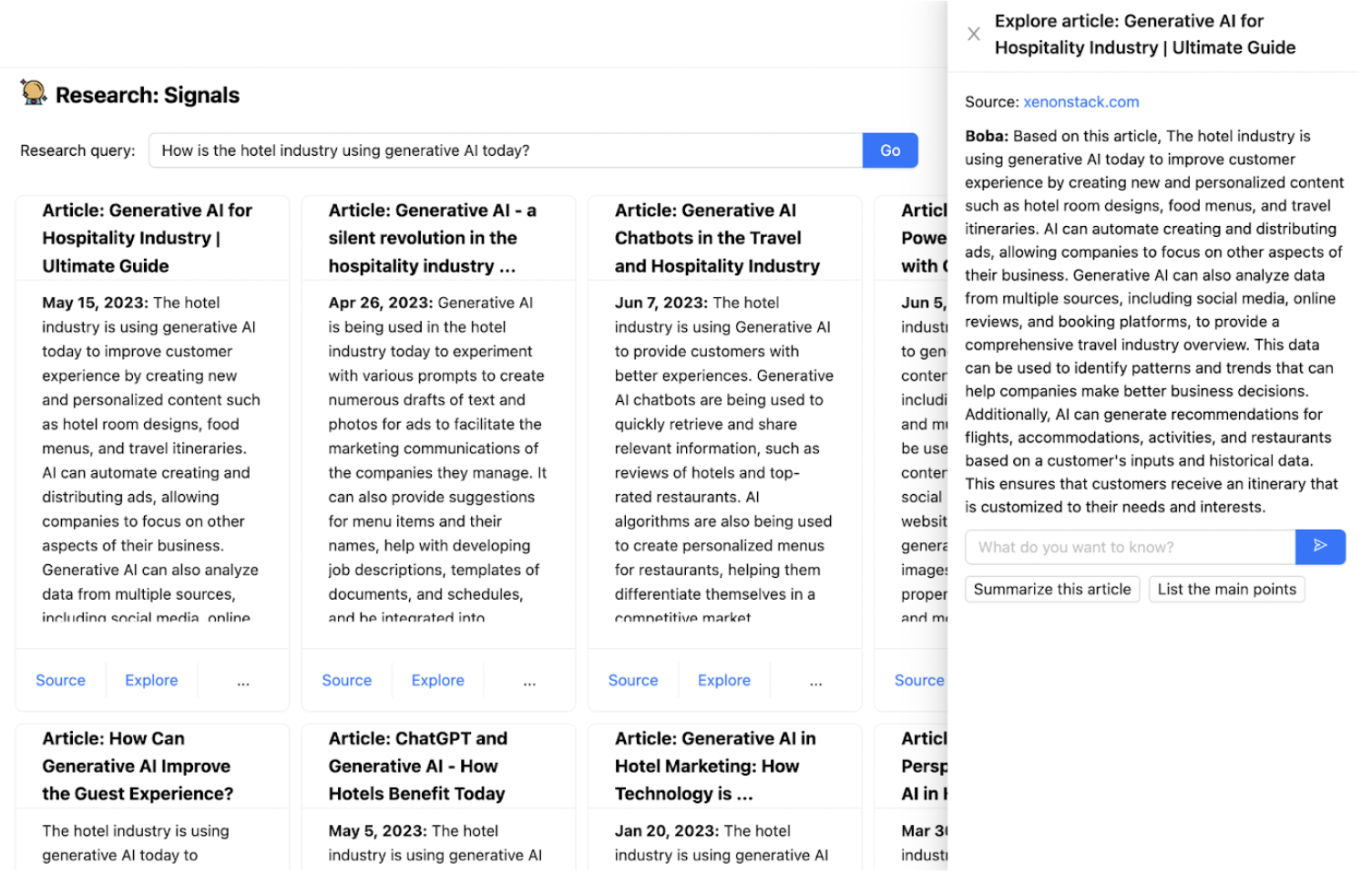
To implement this, we needed to “equip” the LLM with Google as an exterior
internet search software and provides the LLM the flexibility to learn probably lengthy
articles that won’t match into the context window of a immediate. We additionally
needed Boba to have the ability to chat with the person about any related articles the
person finds, which required implementing a type of short-term reminiscence. Lastly,
we needed to offer the person with correct hyperlinks and references that have been
used to reply the person’s analysis query.
The best way we applied this in Boba is as follows:
- Use a Google SERP API to carry out the net search based mostly on the person’s question
and get the highest 10 articles (search outcomes) - Learn the complete content material of every article utilizing the Extract API
- Save the content material of every article in short-term reminiscence, particularly an
in-memory vector retailer. The embeddings for the vector retailer are generated utilizing
the OpenAI API, and based mostly on chunks of every article (versus embedding all the
article itself). - Generate an embedding of the person’s search question
- Question the vector retailer utilizing the embedding of the search question
- Immediate the LLM to reply the person’s unique question in pure language,
whereas prefixing the outcomes of the vector retailer question as context into the LLM
immediate.
This will sound like a number of steps, however that is the place utilizing a software like
Langchain can velocity up your course of. Particularly, Langchain has an
end-to-end chain known as VectorDBQAChain, and utilizing that to carry out the
question-answering took only some strains of code in Boba:
const researchArticle = async (article, immediate) => {
const mannequin = new OpenAI({});
const textual content = article.textual content;
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000 });
const docs = await textSplitter.createDocuments([text]);
const vectorStore = await HNSWLib.fromDocuments(docs, new OpenAIEmbeddings());
const chain = VectorDBQAChain.fromLLM(mannequin, vectorStore);
const res = await chain.name({
input_documents: docs,
question: immediate + ". Be detailed in your response.",
});
return { research_answer: res.textual content };
};
The article textual content incorporates all the content material of the article, which can not
match inside a single immediate. So we carry out the steps described above. As you’ll be able to
see, we used an in-memory vector retailer known as HNSWLib (Hierarchical Navigable
Small World). HNSW graphs are among the many top-performing indexes for vector
similarity search. Nevertheless, for bigger scale use instances and/or long-term reminiscence,
we advocate utilizing an exterior vector DB like Pinecone or Weaviate.
We additionally might have additional streamlined our workflow through the use of Langchain’s
exterior instruments API to carry out the Google search, however we determined in opposition to it
as a result of it offloaded an excessive amount of determination making to Langchain, and we have been getting
combined, gradual and harder-to-parse outcomes. One other strategy to implementing
exterior instruments is to make use of Open AI’s just lately launched Perform Calling
API, which we
talked about earlier on this article.
To summarize, we mixed two distinct strategies to implement Embedded Exterior Information:
- Use Exterior Software: Search and skim articles utilizing Google SERP and Extract
APIs - Use Exterior Reminiscence: Quick-term reminiscence utilizing an in-memory vector retailer
(HNSWLib)
[ad_2]