
[ad_1]
We’re excited to announce public preview of GPU and LLM optimization help for Databricks Mannequin Serving! With this launch, you’ll be able to deploy open-source or your individual customized AI fashions of any sort, together with LLMs and Imaginative and prescient fashions, on the Lakehouse Platform. Databricks Mannequin Serving mechanically optimizes your mannequin for LLM Serving, offering best-in-class efficiency with zero configuration.
Databricks Mannequin Serving is the primary serverless GPU serving product developed on a unified information and AI platform. This lets you construct and deploy GenAI functions from information ingestion and fine-tuning, to mannequin deployment and monitoring, all on a single platform.
Customers on Azure must fill out the signup kind to allow GPU and LLM optimization help for Mannequin Serving
Construct Generative AI Apps with Databricks Mannequin Serving
“With Databricks Mannequin Serving, we’re in a position to combine generative AI into our processes to enhance buyer expertise and improve operational effectivity. Mannequin Serving permits us to deploy LLM fashions whereas retaining full management over our information and mannequin.”
— Ben Dias, Director of Information Science and Analytics at easyJet – Be taught extra
Securely host AI fashions with out worrying about Infrastructure Administration
Databricks Mannequin Serving offers a single resolution to deploy any AI mannequin with out the necessity to perceive complicated infrastructure. This implies you’ll be able to deploy any pure language, imaginative and prescient, audio, tabular, or customized mannequin, no matter the way it was educated – whether or not constructed from scratch, sourced from open-source, or fine-tuned with proprietary information. Merely log your mannequin with MLflow, and we are going to mechanically put together a production-ready container with GPU libraries like CUDA and deploy it to serverless GPUs. Our totally managed service will care for all of the heavy lifting for you, eliminating the necessity to handle cases, keep model compatibility, and patch variations. The service will mechanically scale cases to satisfy site visitors patterns, saving infrastructure prices whereas optimizing latency efficiency.
“Databricks Mannequin Serving is accelerating {our capability} to infuse intelligence into a various array of use circumstances, starting from significant semantic search functions to predicting media traits. By abstracting and simplifying the intricate workings of CUDA and GPU server scaling, Databricks permits us to deal with our actual areas of experience, specifically increasing Condé Nast’s use of AI throughout all our functions with out the effort and burden of infrastructure”
— Ben Corridor, Sr. ML Engr at Condé Nast
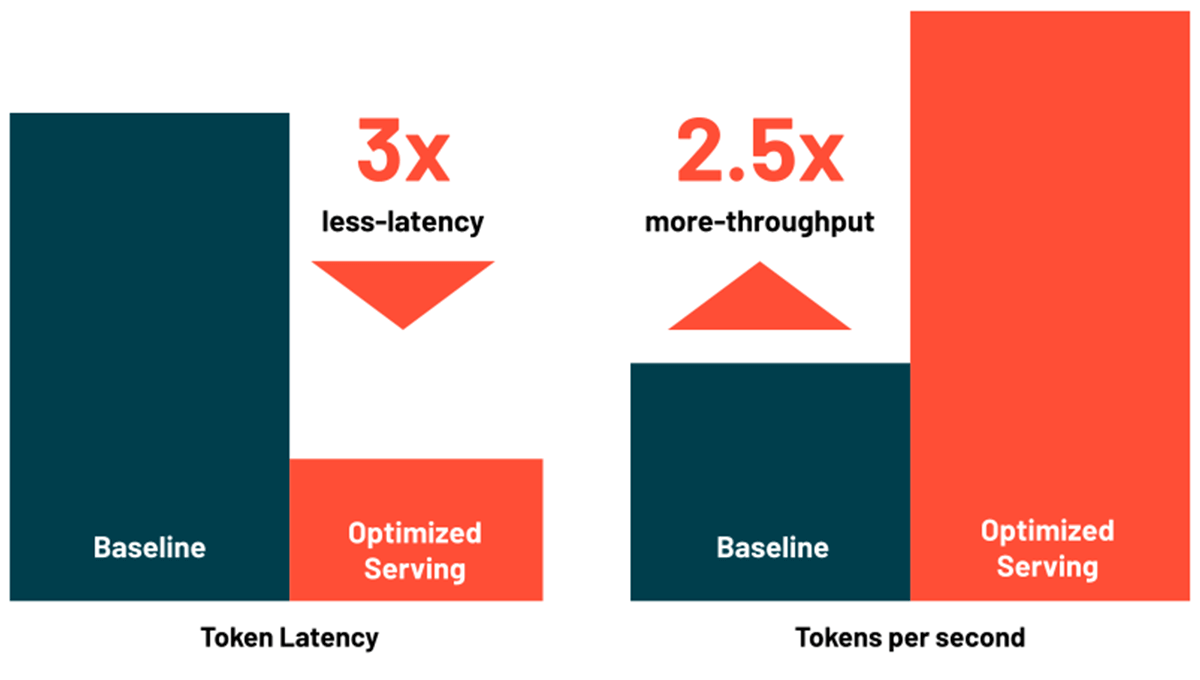
Scale back Latency and Value with Optimized LLM Serving
Databricks Mannequin Serving now consists of optimizations for effectively serving giant language fashions, decreasing latency and value by as much as 3-5x. Utilizing Optimized LLM Serving is extremely simple: simply present the mannequin together with its OSS or fine-tuned weights, and we’ll do the remainder to make sure the mannequin is served with optimized efficiency. This lets you deal with integrating LLM into your software as a substitute of writing low-level libraries for mannequin optimizations. Databricks Mannequin Serving mechanically optimizes the MPT and Llama2 class of fashions, with help for extra fashions forthcoming.
Speed up Deployments by means of Lakehouse AI Integrations
When productionizing LLMs, it isn’t nearly deploying fashions. You additionally must complement the mannequin utilizing strategies comparable to retrieval augmented technology (RAG), parameter-efficient fine-tuning (PEFT), or customary fine-tuning. Moreover, you might want to consider the standard of the LLM and constantly monitor the mannequin for efficiency and security. This usually ends in groups spending substantial time integrating disparate instruments, which will increase operational complexity and creates upkeep overhead.
Databricks Mannequin Serving is constructed on high of a unified information and AI platform enabling you to handle the whole LLMOps, from information ingestion and high-quality tuning to deployment and monitoring, all on a single platform, making a constant view throughout the AI lifecycle that accelerates deployment and minimizes errors. Mannequin Serving integrates with numerous LLM companies throughout the Lakehouse, together with:
- Effective-tuning: Enhance accuracy and differentiate by fine-tuning foundational fashions together with your proprietary information instantly on Lakehouse.
- Vector Search Integration: Combine and seamlessly carry out vector seek for retrieval augmented technology and semantic search use circumstances. Join preview right here.
- Constructed-in LLM Administration: Built-in with Databricks AI Gateway as a central API layer for all of your LLM calls.
- MLflow: Consider, evaluate, and handle LLMs through MLflow’s PromptLab.
- High quality & Diagnostics: Robotically seize requests and responses in a Delta desk to watch and debug fashions. You may moreover mix this information together with your labels to generate coaching datasets by means of our partnership with Labelbox.
- Unified governance: Handle and govern all information and AI property, together with these consumed and produced by Mannequin Serving, with Unity Catalog.
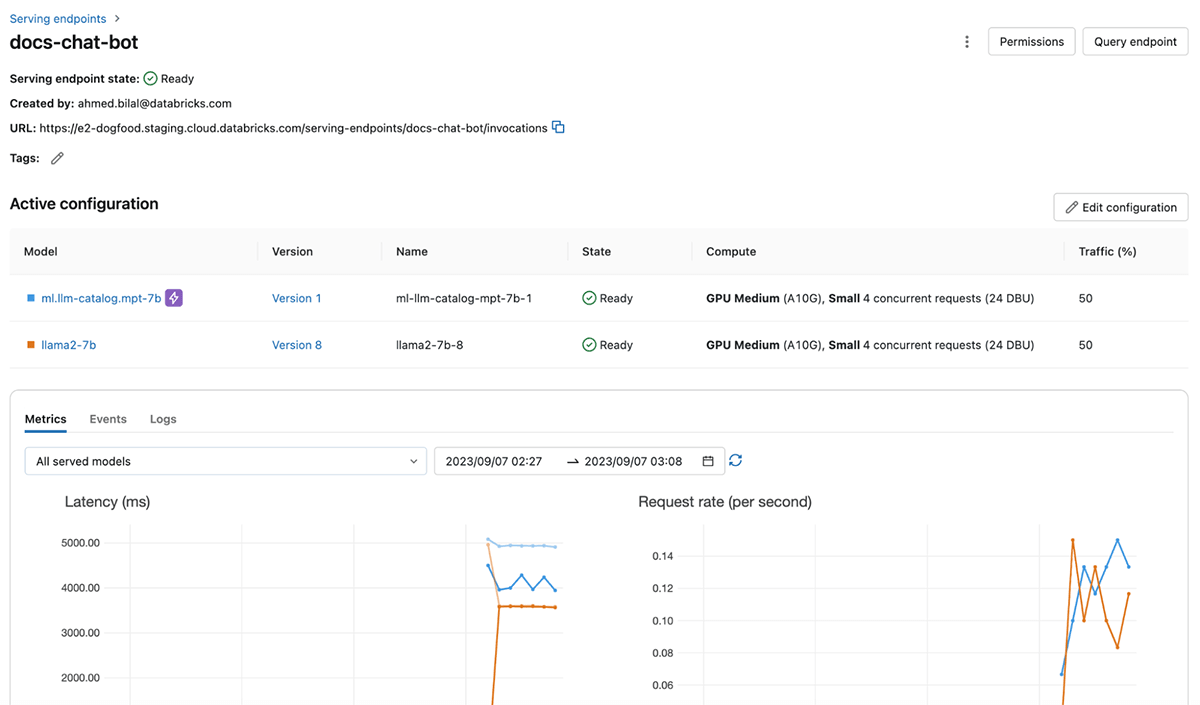
Convey Reliability and Safety to LLM Serving
Databricks Mannequin Serving offers devoted compute sources that allow inference at scale, with full management over the information, mannequin, and deployment configuration. By getting devoted capability in your chosen cloud area, you profit from low overhead latency, predictable efficiency, and SLA-backed ensures. Moreover, your serving workloads are protected by a number of layers of safety, making certain a safe and dependable setting for even probably the most delicate duties. We’ve got carried out a number of controls to satisfy the distinctive compliance wants of extremely regulated industries. For additional particulars, please go to this web page or contact your Databricks account crew.
Getting Began with GPU and LLM Serving
- In case you are on Azure, please join right here to allow GPU and LLM Serving.
- Dive deeper into the Databricks Mannequin Serving documentation.
- Be taught extra about Databricks’ strategy to Generative AI right here.
[ad_2]