
[ad_1]
The inaccuracy and extreme optimism of value estimates are typically cited as dominant elements in DoD value overruns. Causal studying can be utilized to determine particular causal elements which are most chargeable for escalating prices. To comprise prices, it’s important to know the elements that drive prices and which of them may be managed. Though we might perceive the relationships between sure elements, we don’t but separate the causal influences from non-causal statistical correlations.
Causal fashions needs to be superior to conventional statistical fashions for value estimation: By figuring out true causal elements versus statistical correlations, value fashions needs to be extra relevant in new contexts the place the correlations may not maintain. Extra importantly, proactive management of venture and activity outcomes may be achieved by straight intervening on the causes of those outcomes. Till the event of computationally environment friendly causal-discovery algorithms, we didn’t have a strategy to get hold of or validate causal fashions from primarily observational information—randomized management trials in techniques and software program engineering analysis are so impractical that they’re almost inconceivable.
On this weblog publish, I describe the SEI Software program Price Prediction and Management (abbreviated as SCOPE) venture, the place we apply causal-modeling algorithms and instruments to a big quantity of venture information to determine, measure, and check causality. The publish builds on analysis undertaken with Invoice Nichols and Anandi Hira on the SEI, and my former colleagues David Zubrow, Robert Stoddard, and Sarah Sheard. We sought to determine some causes of venture outcomes, equivalent to value and schedule overruns, in order that the price of buying and working software-reliant techniques and their rising functionality is predictable and controllable.
We’re growing causal fashions, together with structural equation fashions (SEMs), that present a foundation for
- calculating the trouble, schedule, and high quality outcomes of software program tasks below totally different eventualities (e.g., Waterfall versus Agile)
- estimating the outcomes of interventions utilized to a venture in response to a change in necessities (e.g., a change in mission) or to assist carry the venture again on monitor towards attaining value, schedule, and technical necessities.
A right away good thing about our work is the identification of causal elements that present a foundation for controlling program prices. A long run profit is the flexibility to make use of causal fashions to barter software program contracts, design coverage, and incentives, and inform could-/should-cost and affordability efforts.
Why Causal Studying?
To systematically cut back prices, we usually should determine and think about the a number of causes of an end result and punctiliously relate them to one another. A robust correlation between an element X and price might stem largely from a typical reason for each X and price. If we fail to look at and regulate for that frequent trigger, we might incorrectly attribute X as a big reason for value and expend vitality (and prices), fruitlessly intervening on X anticipating value to enhance.
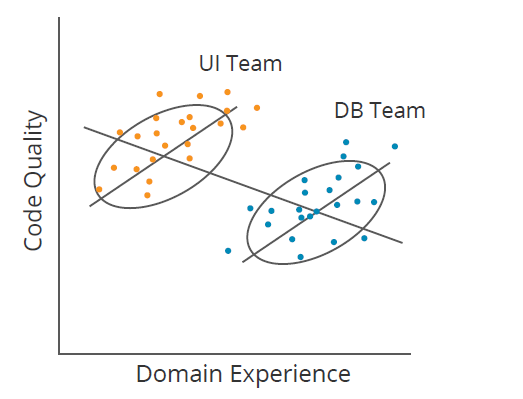
One other problem to correlations is illustrated by Simpson’s Paradox. For instance, in Determine 1 beneath, if a program supervisor didn’t section information by crew (Person Interface [UI] and Database [DB]), they may conclude that rising area expertise reduces code high quality (downward line); nonetheless, inside every crew, the alternative is true (two upward strains). Causal studying identifies when elements like crew membership clarify away (or mediate) correlations. It really works for rather more difficult datasets too.
{kind=link}
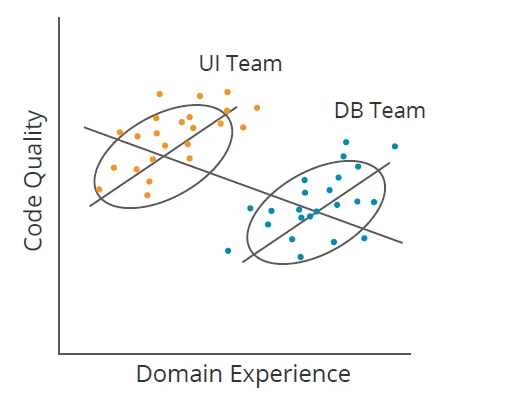
Determine 1: Illustration of Simpson’s Paradox
Causal studying is a type of machine studying that focuses on causal inference. Machine studying produces a mannequin that can be utilized for prediction from a dataset. Causal studying differs from machine studying in its concentrate on modeling the data-generation course of. It solutions questions equivalent to
- How did the information come to be the best way it’s?
- What information is driving which outcomes?
Of explicit curiosity in causal studying is the excellence between conditional dependence and conditional independence. For instance, if I do know what the temperature is exterior, I can discover that the variety of shark assaults and ice cream gross sales are impartial of one another (conditional independence). If I do know {that a} automobile gained’t begin, I can discover that the situation of the fuel tank and battery are depending on one another (conditional dependence) as a result of if I do know one in every of these is okay, the opposite is just not more likely to be nice.
Methods and software program engineering researchers and practitioners who search to optimize observe typically espouse theories about how finest to conduct system and software program improvement and sustainment. Causal studying might help check the validity of such theories. Our work seeks to evaluate the empirical basis for heuristics and guidelines of thumb utilized in managing applications, planning applications, and estimating prices.
A lot prior work has targeted on utilizing regression evaluation and different methods. Nevertheless, regression doesn’t distinguish between causality and correlation, so performing on the outcomes of a regression evaluation may fail to affect outcomes within the desired manner. By deriving usable data from observational information, we generate actionable data and apply it to supply the next degree of confidence that interventions or corrective actions will obtain desired outcomes.
The next examples from our analysis spotlight the significance and problem of figuring out real causal elements to clarify phenomena.
Opposite and Stunning Outcomes
{kind=link}
{kind=link}

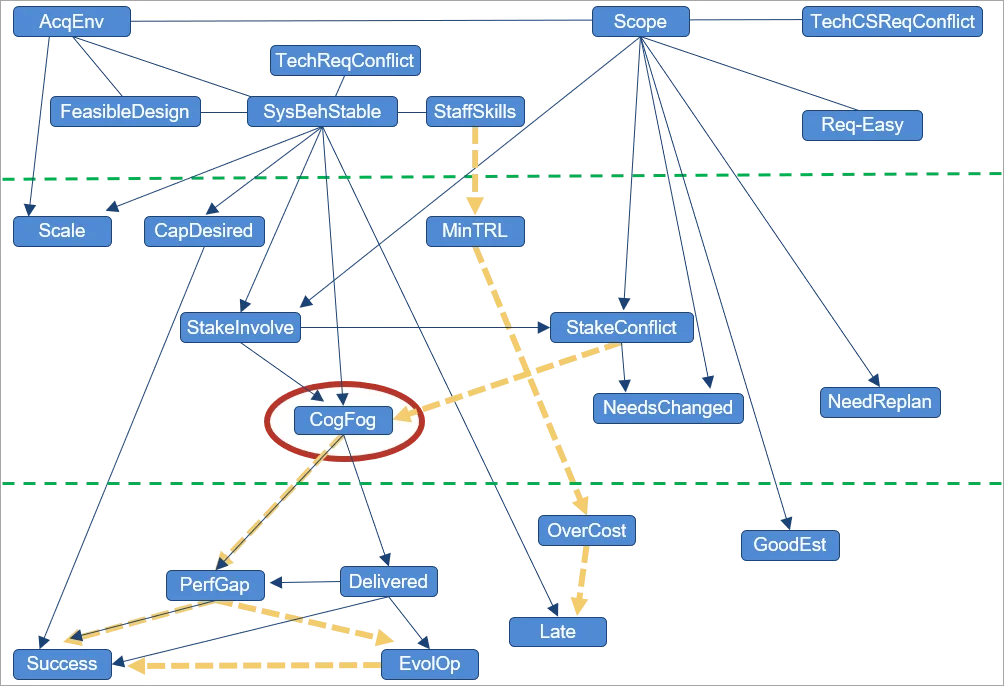
Determine 2: Complexity and Program Success
Determine 2 reveals a dataset developed by Sarah Sheard that comprised roughly 40 measures of complexity (elements), looking for to determine what varieties of complexity drive success versus failure in DoD applications (solely these elements discovered to be causally ancestral to program success are proven). Though many several types of complexity have an effect on program success, the one constant driver of success or failure that we repeatedly discovered is cognitive fog, which includes the lack of mental capabilities, equivalent to considering, remembering, and reasoning, with ample severity to intervene with each day functioning.
Cognitive fog is a state that groups continuously expertise when having to persistently take care of conflicting information or difficult conditions. Stakeholder relationships, the character of stakeholder involvement, and stakeholder battle all have an effect on cognitive fog: The connection is one in every of direct causality (relative to the elements included within the dataset), represented in Determine 2 by edges with arrowheads. This relationship signifies that if all different elements are mounted—and we modify solely the quantity of stakeholder involvement or battle—the quantity of cognitive fog adjustments (and never the opposite manner round).
Sheard’s work recognized what varieties of program complexity drive or impede program success. The eight elements within the high horizontal section of Determine 2 are elements obtainable in the beginning of this system. The underside seven are elements of program success. The center eight are elements obtainable throughout program execution. Sheard discovered three elements within the higher or center bands that had promise for intervention to enhance program success. We utilized causal discovery to the identical dataset and found that one in every of Sheard’s elements, variety of exhausting necessities, appeared to haven’t any causal impact on program success (and thus doesn’t seem within the determine). Cognitive fog, nonetheless, is a dominating issue. Whereas stakeholder relationships additionally play a job, all these arrows undergo cognitive fog. Clearly, the advice for a program supervisor primarily based on this dataset is that sustaining wholesome stakeholder relationships can be certain that applications don’t descend right into a state of cognitive fog.
Direct Causes of Software program Price and Schedule
Readers accustomed to the Constructive Price Mannequin (COCOMO) or Constructive Methods Engineering Price Mannequin (COSYSMO) might surprise what these fashions would have regarded like had causal studying been used of their improvement, whereas sticking with the identical acquainted equation construction utilized by these fashions. We just lately labored with a number of the researchers chargeable for creating and sustaining these fashions [formerly, members of the late Barry Boehm‘s group at the University of Southern California (USC)]. We coached these researchers on how one can apply causal discovery to their proprietary datasets to achieve insights into what drives software program prices.
From among the many greater than 40 elements that COCOMO and COSYSMO describe, these are those that we discovered to be direct drivers of value and schedule:
COCOMO II effort drivers:
- dimension (software program strains of code, SLOC)
- crew cohesion
- platform volatility
- reliability
- storage constraints
- time constraints
- product complexity
- course of maturity
- threat and structure decision
COCOMO II schedule drivers
- dimension (SLOC)
- platform expertise
- schedule constraint
- effort
COSYSMO 3.0 effort drivers
- dimension
- level-of-service necessities
In an effort to recreate value fashions within the model of COCOMO and COSYSMO, however primarily based on causal relationships, we used a device known as Tetrad to derive graphs from the datasets after which instantiate a couple of easy mini-cost-estimation fashions. Tetrad is a collection of instruments utilized by researchers to find, parameterize, estimate, visualize, check, and predict from causal construction. We carried out the next six steps to generate the mini-models, which produce believable value estimates in our testing:
- Disallow value drivers to have direct causal relationships with each other. (Such independence of value drivers is a central design precept for COCOMO and COSYSMO.)
- As a substitute of together with every scale issue as a variable (as we do in effort
multipliers), substitute them with a brand new variable: scale issue occasions LogSize. - Apply causal discovery to the revised dataset to acquire a causal graph.
- Use Tetrad mannequin estimation to acquire parent-child edge coefficients.
- Carry the equations from the ensuing graph to kind the mini-model, reapplying estimation to correctly decide the intercept.
- Consider the match of the ensuing mannequin and its predictability.
{kind=link}
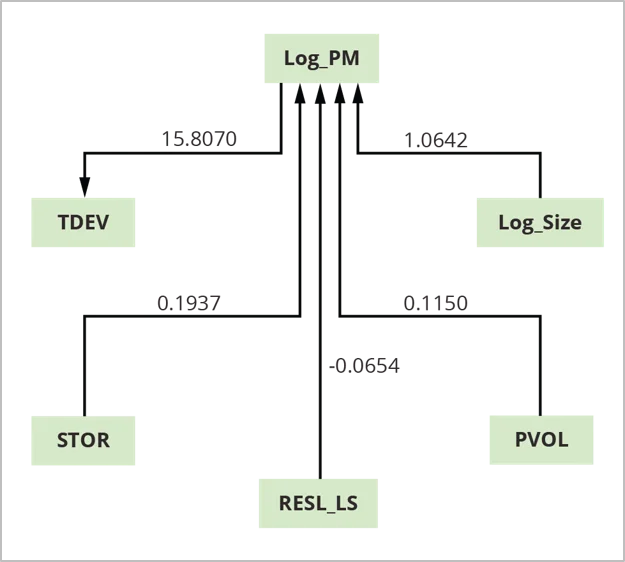
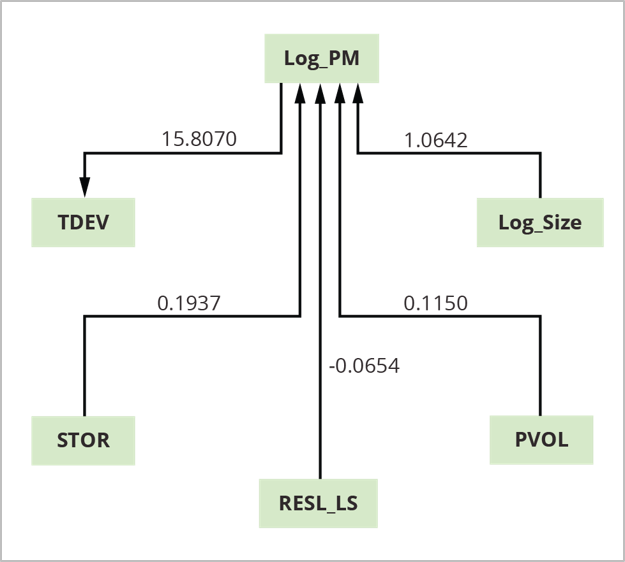
Determine 3: COCOMO II Mini-Price Estimation Mannequin
The benefit of the mini-model is that it identifies which elements, amongst many, usually tend to drive value and schedule. In accordance with this evaluation utilizing COCOMO II calibration information, 4 elements—log dimension (Log_Size), platform volatility (PVOL), dangers from incomplete structure occasions log dimension (RESL_LS), and reminiscence storage (STOR)—are direct causes (drivers) of venture effort (Log_PM). Log_PM is a driver of the time to develop (TDEV).
We carried out the same evaluation of systems-engineering effort to derive the same mini-model expressing the log of effort as a perform of log dimension and degree of service.
In abstract, these outcomes point out that to cut back venture effort, we must always change one in every of its found direct causes. If we have been to intervene on another variable, the impact on effort is more likely to be extra modest, and will affect different fascinating venture outcomes (delivered functionality or high quality). These outcomes are additionally extra generalizable than outcomes from regression, serving to to determine the direct causal relationships that will persist past the bounds of a selected venture inhabitants that was sampled.
Consensus Graph for U.S. Military Software program Sustainment
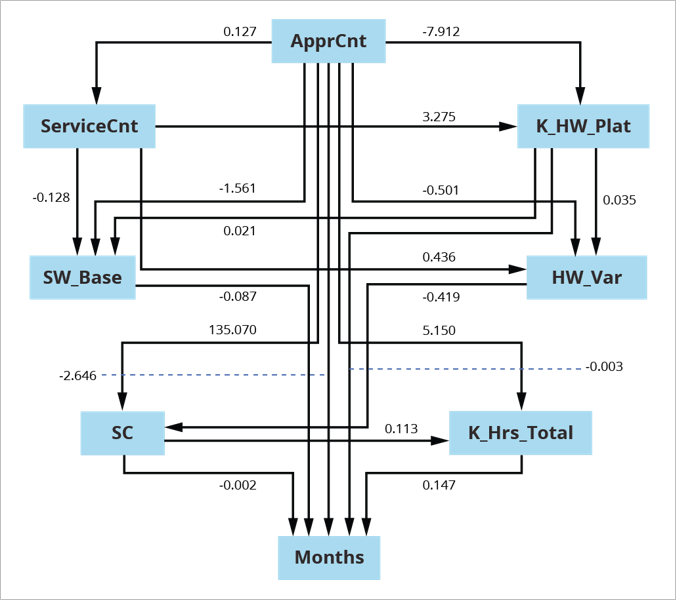{kind=link}
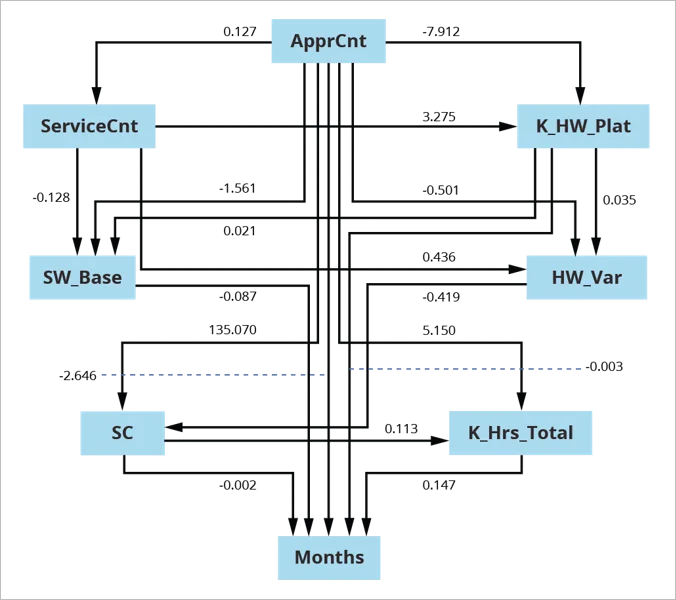
Determine 4: Consensus Graph for U.S. Military Software program Sustainment
On this instance, we segmented a U.S. Military sustainment dataset into [superdomain, acquisition category (ACAT) level] pairs, leading to 5 units of information to go looking and estimate. Segmenting on this manner addressed excessive fan-out for frequent causes, which might result in constructions typical of Simpson’s Paradox. With out segmenting by [superdomain, ACAT-level] pairs, graphs are totally different than once we section the information. We constructed the consensus graph proven in Determine 4 above from the ensuing 5 searched and fitted fashions.
For consensus estimation, we pooled the information from particular person searches with information that was beforehand excluded due to lacking values. We used the ensuing 337 releases to estimate the consensus graph utilizing Mplus with Bootstrap in estimation.
This mannequin is a direct out-of-the-box estimation, attaining good mannequin match on the primary attempt.
Our Resolution for Making use of Causal Studying to Software program Improvement
We’re making use of causal studying of the type proven within the examples above to our datasets and people of our collaborators to ascertain key trigger–impact relationships amongst venture elements and outcomes. We’re making use of causal-discovery algorithms and information evaluation to those cost-related datasets. Our strategy to causal inference is principled (i.e., no cherry choosing) and sturdy (to outliers). This strategy is surprisingly helpful for small samples, when the variety of instances is fewer than 5 to 10 occasions the variety of variables.
If the datasets are proprietary, the SEI trains collaborators to carry out causal searches on their very own as we did with USC. The SEI then wants data solely about what dataset and search parameters have been used in addition to the ensuing causal graph.
Our total technical strategy subsequently consists of 4 threads:
- studying in regards to the algorithms and their totally different settings
- encouraging the creators of those algorithms (Carnegie Mellon Division of Philosophy) to create new algorithms for analyzing the noisy and small datasets extra typical of software program engineering, particularly throughout the DoD
- persevering with to work with our collaborators on the College of Southern California to achieve additional insights into the driving elements that have an effect on software program prices
- presenting preliminary outcomes and thereby soliciting value datasets from value estimators throughout and from the DoD specifically
Accelerating Progress in Software program Engineering with Causal Studying
Understanding which elements drive particular program outcomes is crucial to supply increased high quality and safe software program in a well timed and inexpensive method. Causal fashions provide higher perception for program management than fashions primarily based on correlation. They keep away from the hazard of measuring the mistaken issues and performing on the mistaken alerts.
Progress in software program engineering may be accelerated through the use of causal studying; figuring out deliberate programs of motion, equivalent to programmatic selections and coverage formulation; and focusing measurement on elements recognized as causally associated to outcomes of curiosity.
In coming years, we are going to
- examine determinants and dimensions of high quality
- quantify the energy of causal relationships (known as causal estimation)
- search replication with different datasets and proceed to refine our methodology
- combine the outcomes right into a unified set of decision-making ideas
- use causal studying and different statistical analyses to provide further artifacts to make Quantifying Uncertainty in Early Lifecycle Price Estimation (QUELCE) workshops simpler
We’re satisfied that causal studying will speed up and provide promise in software program engineering analysis throughout many subjects. By confirming causality or debunking typical knowledge primarily based on correlation, we hope to tell when stakeholders ought to act. We imagine that usually the mistaken issues are being measured and actions are being taken on mistaken alerts (i.e., primarily on the idea of perceived or precise correlation).
There may be important promise in persevering with to have a look at high quality and safety outcomes. We additionally will add causal estimation into our mixture of analytical approaches and use further equipment to quantify these causal inferences. For this we’d like your assist, entry to information, and collaborators who will present this information, study this system, and conduct it on their very own information. If you wish to assist, please contact us.
[ad_2]