
[ad_1]
Rockset is a real-time search and analytics database within the cloud. One of many methods Rockset maximizes price-performance for our clients is by individually scaling compute and storage. This improves effectivity and elasticity, however is difficult to implement for a real-time system. Actual-time methods reminiscent of Elasticsearch have been designed to work off of instantly hooked up storage to permit for quick entry within the face of real-time updates. On this weblog, we’ll stroll by means of how Rockset supplies compute-storage separation whereas making real-time information out there to queries.
The Problem: Reaching Compute-Storage Separation with out Efficiency Degradation
Historically databases have been designed to work off of methods with instantly hooked up storage. This simplifies the system’s structure and permits excessive bandwidth, low latency entry to the information at question time. Trendy SSD {hardware} can carry out many small random reads, which helps indexes carry out properly. This structure is well-suited for on-premise infrastructure, the place capability is pre-allocated and workloads are restricted by the out there capability. Nevertheless, in a cloud first world, capability and infrastructure ought to adapt to the workload.
There are a number of challenges when utilizing a tightly coupled structure for real-time search and analytics:
- Overprovisioning sources: You can not scale compute and storage sources independently, resulting in inefficient useful resource utilization.
- Gradual to scale: The system requires time for added sources to be spun up and made out there to customers, so clients have to plan for peak capability.
- A number of copies of the dataset: Operating a number of compute clusters on the identical underlying dataset requires replicating the information onto every compute cluster.
If we might retailer all information in a shared location accessible by all compute nodes, and nonetheless obtain attached-SSD-equivalent efficiency, we’d resolve all of the above issues.
Scaling compute clusters would then rely on compute necessities alone, and could be extra elastic as we don’t have to obtain the complete dataset as a part of every scaling operation. We will load bigger datasets by simply scaling the storage capability. This permits a number of compute nodes to entry the identical dataset with out rising the variety of underlying copies of the information. An extra profit is the flexibility to provision cloud {hardware} particularly tuned for compute or storage effectivity.
A Primer on Rockset’s Cloud-Native Structure
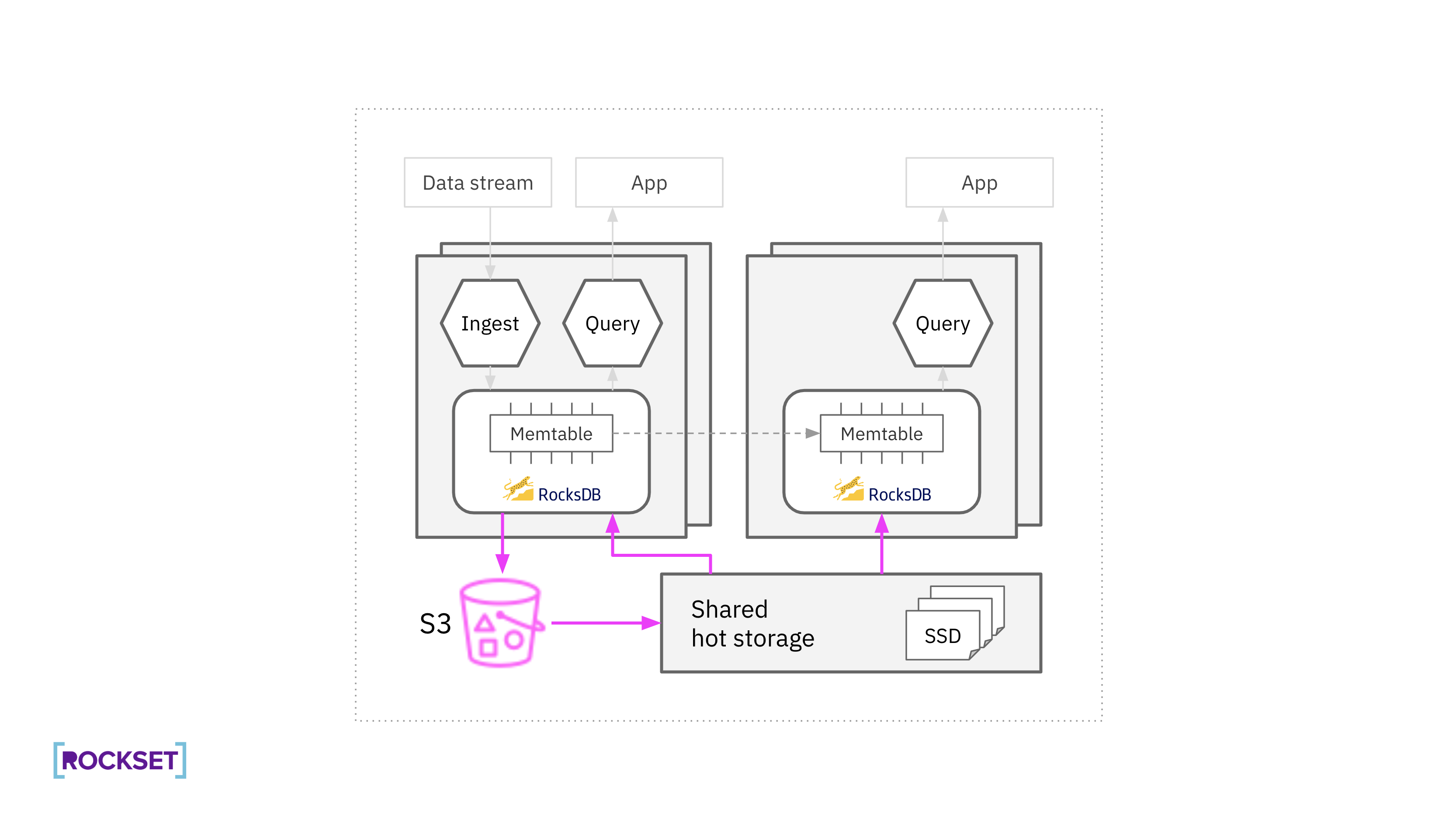
Rockset separates compute from storage. Digital cases (VIs) are allocations of compute and reminiscence sources accountable for information ingestion, transformations, and queries. Individually, Rockset has a scorching storage layer composed of many storage nodes with hooked up SSDs for elevated efficiency.
Below the hood, Rockset makes use of RocksDB as its embedded storage engine which is designed for mutability. Rockset created the RocksDB-Cloud library on high of RocksDB to reap the benefits of new cloud-based architectures. RocksDB-Cloud supplies information sturdiness even within the face of machine failures by integrating with cloud providers like Amazon S3. This permits Rockset to have a tiered storage structure the place one copy of scorching information is saved on SSDs for efficiency and replicas in S3 for sturdiness. This tiered storage structure delivers higher price-performance for Rockset clients.
After we designed the recent storage layer, we saved the next design rules in thoughts:
- Related question efficiency to tightly coupled compute-storage structure
- No efficiency degradation throughout deployments or when scaling up/down
- Fault tolerance
How We Use RocksDB at Rockset
RocksDB is a well-liked Log Structured Merge (LSM) tree storage engine that’s designed to deal with excessive write charges. In an LSM tree structure, new writes are written to an in-memory memtable and memtables are flushed, after they refill, into immutable sorted strings desk (SST) information. Rockset performs fine-grained replication of the RocksDB memtable in order that the real-time replace latency will not be tied to the SST file creation and distribution course of.
The SST information are compressed into uniform storage blocks for extra environment friendly storage. When there’s a information change, RocksDB deletes the outdated SST file and creates a brand new one with the up to date information. This compaction course of, much like rubbish assortment in language runtimes, runs periodically, eradicating stale variations of the information and stopping database bloat.
New SST information are uploaded to S3, to make sure sturdiness. The recent storage layer then fetches the information from S3, for efficiency. The information are immutable, which simplifies the position of the recent storage layer: it solely wants to find and retailer newly created SST information and evict outdated SST information.
When executing queries, RocksDB requests blocks of knowledge, with every block represented by offset and measurement in a file, from the recent storage layer. RocksDB additionally caches just lately accessed blocks within the compute node for quick retrieval.
Along with the information information, RocksDB additionally shops metadata data in MANIFEST information that monitor the information information that characterize the present model of the database. These metadata information are a set quantity per database occasion and they’re small in measurement. Metadata information are mutable and up to date when new SST information are created, however are not often learn and by no means learn throughout question execution.
In distinction to SST information, metadata information are saved regionally on the compute nodes and in S3 for sturdiness however not on the recent storage layer. Since metadata information are small and solely learn from S3 not often, storing them on the compute nodes doesn’t impression scalability or efficiency. Furthermore, this simplifies the storage layer because it solely must help immutable information.
Information Placement within the Sizzling Storage Layer
At a excessive stage, Rockset’s scorching storage layer is an S3 cache. Information are thought of to be sturdy as soon as they’re written to S3, and are downloaded from S3 into the recent storage layer on demand. Not like an everyday cache, nonetheless, Rockset’s scorching storage layer makes use of a broad vary of methods to realize a cache hit charge of 99.9999%.
Distributing RocksDB Information within the Sizzling Storage Layer
Every Rockset assortment, or a desk within the relational world, is split into slices with every slice containing a set of SST information. The slice consists of all blocks that belong to these SST information. The recent storage layer makes information placement choices at slice granularity.
Rendezvous hashing is used to map slices to their corresponding storage nodes, a major and secondary proprietor storage node. The hash can be utilized by the compute nodes to determine the storage nodes to retrieve information from. The Rendezvous hashing algorithm works as follows:
- Every assortment slice and storage node is given an ID. These IDs are static and by no means change
- For each storage node, hash the concatenation of the slice ID and the storage node ID
- The ensuing hashes are sorted
- The highest two storage nodes from the ordered Rendezvous Hashing checklist are the slice’s major and secondary homeowners

Rendezvous hashing was chosen for information distribution as a result of it accommodates a number of attention-grabbing properties:
- It yields minimal actions when the variety of storage nodes adjustments. If we add or take away a node from the recent storage layer, the variety of assortment slices that can change proprietor whereas rebalancing shall be proportional to 1/N the place N is the variety of nodes within the scorching storage layer. This leads to quick scaling of the recent storage layer.
- It helps the recent storage layer get well quicker on node failure as duty for restoration is unfold throughout all remaining nodes in parallel.
- When including a brand new storage node, inflicting the proprietor for a slice to vary, it’s easy to compute which node was the earlier proprietor. The ordered Rendezvous hashing checklist will solely shift by one aspect. That method, compute nodes can fetch blocks from the earlier proprietor whereas the brand new storage node warms up.
- Every element of the system can individually decide the place a file belongs with none direct communication. Solely minimal metadata is required: the slice ID and the IDs of the out there storage nodes. That is particularly helpful when creating new information, for which a centralized placement algorithm would improve latency and cut back availability.
Whereas storage nodes work on the assortment slice and SST file granularity, at all times downloading all the SST information for the slices they’re accountable for, compute nodes solely retrieve the blocks that they want for every question. Subsequently, storage nodes solely want restricted data on the bodily format of the database, sufficient to know which SST information belong to a slice, and depend on compute nodes to specify block boundaries on their RPC requests.
Designing for Reliability, Efficiency, and Storage Effectivity
An implicit purpose of all vital distributed methods, reminiscent of the recent storage tier, is to be out there and performant always. Actual-time analytics constructed on Rockset have demanding reliability and latency objectives, which interprets instantly into demanding necessities on the recent storage layer. As a result of we at all times have the flexibility to learn from S3, we take into consideration reliability for the recent storage layer as our skill to service reads with disk-like latency.
Sustaining efficiency with compute-storage separation
Minimizing the overhead of requesting blocks by means of the community
To make sure that Rockset’s separation of compute-storage is performant, the structure is designed to attenuate the impression of community calls and the period of time it takes to fetch information from disk. That’s as a result of block requests that undergo the community may be slower than native disk reads. Compute nodes for a lot of real-time methods hold the dataset in hooked up storage to keep away from this damaging efficiency impression. Rockset employs caching, read-ahead, and parallelization methods to restrict the impression of community calls.
Rockset expands the quantity of cache area out there on compute nodes by including an extra caching layer, an SSD-backed persistent secondary cache (PSC), to help massive working datasets. Compute nodes include each an in-memory block cache and a PSC. The PSC has a set quantity of space for storing on compute nodes to retailer RocksDB blocks which were just lately evicted from the in-memory block cache. Not like the in-memory block cache, information within the PSC is endured between course of restarts enabling predictable efficiency and limiting the necessity to request cached information from the recent storage layer.
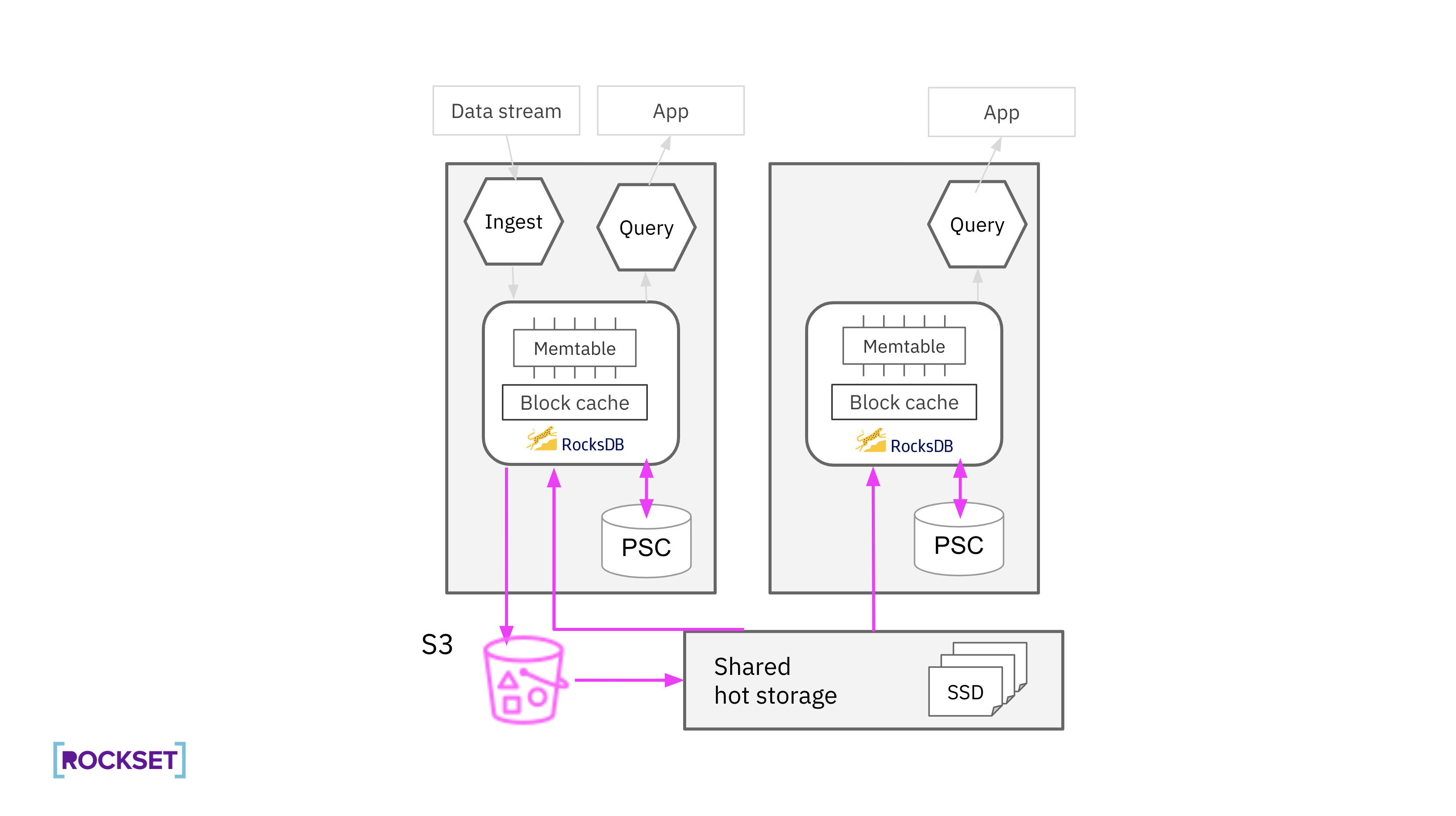
Question execution has additionally been designed to restrict the efficiency penalty of requests going over the community utilizing prefetching and parallelism. Blocks that can quickly be required for computation are fetched in-parallel whereas compute nodes course of the information they have already got, hiding the latency of a community spherical journey. A number of blocks are additionally fetched as a part of a single request, decreasing the variety of RPCs and rising the information switch charge. Compute nodes can fetch blocks from the native PSC, probably saturating the SSD bandwidth, and from the recent storage layer, saturating the community bandwidth, in parallel.
Avoiding S3 reads at question time
Retrieving blocks out there within the scorching storage layer is 100x quicker than learn misses to S3, a distinction of <1ms to 100ms. Subsequently, holding S3 downloads out of the question path is vital for a real-time system like Rockset.
If a compute node requests a block belonging to a file not discovered within the scorching storage layer, a storage node should obtain the SST file from S3 earlier than the requested block may be despatched again to the compute node. To fulfill the latency necessities of our clients, we should be sure that all blocks wanted at question time can be found within the scorching storage layer earlier than compute nodes request them. The recent storage layer achieves this by way of three mechanisms:
- Compute nodes ship a synchronous prefetch request to the recent storage layer each time a brand new SST file is created. This occurs as a part of memtable flushes and compactions. RocksDB commits the memtable flush or compaction operation after the recent storage layer downloads the file guaranteeing the file is out there earlier than a compute node can request blocks from it.
- When a storage node discovers a brand new slice, resulting from a compute node sending a prefetch or learn block request for a file belonging to that slice, it proactively scans S3 to obtain the remainder of the information for that slice. All information for a slice share the identical prefix in S3, making this easier.
- Storage nodes periodically scan S3 to maintain the slices they personal in sync. Any regionally lacking information are downloaded, and regionally out there information which are out of date are deleted.
Replicas for Reliability
For reliability, Rockset shops as much as two copies of information on totally different storage nodes within the scorching storage layer. Rendezvous hashing is used to find out the first and secondary proprietor storage nodes for the information slice. The first proprietor eagerly downloads the information for every slice utilizing prefetch RPCs issued by compute nodes and by scanning S3. The secondary proprietor solely downloads the file after it has been learn by a compute node. To take care of reliability in a scale up occasion, the earlier proprietor maintains a duplicate till the brand new homeowners have downloaded the information. Compute nodes use the earlier proprietor as a failover vacation spot for block requests throughout that point.
When designing the recent storage layer, we realized that we might save on storage prices whereas nonetheless attaining resiliency by solely storing a partial second copy. We use a LRU information construction to make sure that the information wanted for querying is available even when one of many copies is misplaced. We allocate a set quantity of disk area within the scorching storage layer as a LRU cache for secondary copy information. From manufacturing testing we discovered that storing secondary copies for ~30-40% of the information, along with the in-memory block cache and PSC on compute nodes, is adequate to keep away from going to S3 to retrieve information, even within the case of a storage node crash.
Using the spare buffer capability to enhance reliability
Rockset additional reduces disk capability necessities utilizing dynamically resizing LRUs for the secondary copies. In different information methods, buffer capability is reserved for ingesting and downloading new information into the storage layer. We made the recent storage layer extra environment friendly within the utilization of native disk by filling the buffer capability with dynamically resizing LRUs. The dynamic nature of the LRUs signifies that we will shrink the area used for secondary copies when there’s an elevated demand for ingesting and downloading information. With this storage design, Rockset totally makes use of the disk capability on the storage nodes through the use of the spare buffer capability to retailer information.
We additionally opted to retailer major copies in LRUs for the circumstances the place ingestion scales quicker than storage. It’s theoretically attainable that the cumulative ingestion charge of all digital cases surpasses the speed at which the recent storage layer can scale capability, the place Rockset would run out of disk area and ingestion would halt with out using LRUs. By storing major copies within the LRU, Rockset can evict major copy information that has not been just lately accessed to create space for brand new information and proceed ingesting and serving queries.
By decreasing how a lot information we retailer and in addition using extra out there disk area we have been in a position to cut back the price of operating the recent storage layer considerably.
Protected code deploys on a single copy world
The LRU ordering for all information is endured to disk in order that it survives deployments and course of restarts. That stated, we additionally wanted to make sure the protected deployment or scaling the cluster and not using a second full copy of the dataset.
A typical rolling code deployment entails bringing down a course of operating the outdated model after which beginning a course of with a brand new model. With this there’s a interval of down time after the outdated course of has drained and earlier than the brand new course of has readied up forcing us to decide on between two non very best choices:
- Settle for that information saved within the storage node shall be unavailable throughout that point. Question efficiency can undergo on this case, as different storage nodes might want to obtain SST information on demand if requested by compute nodes earlier than the storage node comes again on-line.
- Whereas draining the method, switch the information that the storage node is accountable for to different storage nodes. This is able to preserve the efficiency of the recent storage layer throughout deploys, however leads to a number of information motion, making deploys take a for much longer time. It’d additionally improve our S3 price, because of the variety of GetObject operations.
These tradeoffs present us how deployment strategies created for stateless methods don’t work for stateful methods like the recent storage layer. So, we carried out a deployment course of that avoids information motion whereas additionally sustaining availability of all information referred to as Zero Downtime Deploys. Right here’s the way it works:
- A second course of operating a brand new code model is began on every storage node, whereas the method for the outdated code model remains to be operating. As this new course of operating on the identical {hardware} it additionally has entry to all SST information already saved on that node
- The brand new processes then take over from the processes operating the earlier model of the binary, and begin serving block requests from compute nodes.
- As soon as the brand new processes totally take over all tasks, the outdated processes may be drained.
Every course of operating on the identical storage node falls into the identical place within the Rendezvous Hashing ordered checklist. This permits us to double the variety of processes with none information motion. A world config parameter (”Energetic model”) lets the system know which course of is the efficient proprietor for that storage node. Compute nodes use this data to determine which course of to ship requests to.
Past deploying with no unavailability this course of has great operational advantages. Launching providers with new variations and the time at which the newer variations begin dealing with requests are distinctly toggleable steps. This implies we will launch new processes, slowly scale up visitors to them, and instantly roll again to the outdated variations with out launching new processes, nodes, or any information motion if we see an issue. Rapid rollback means much less likelihood for any points.
Sizzling Storage Layer Resizing Operations for Storage Effectivity
Including storage nodes to extend capability
The recent storage layer ensures that there’s sufficient capability to retailer a duplicate for every file. Because the system approaches capability, extra nodes are added to the cluster mechanically. Current nodes drop information slices that now belong to the brand new storage node as quickly as the brand new node fetches them, making room for different information.
The search protocol ensures that compute nodes are nonetheless capable of finding information blocks, even when the proprietor for an information slice has modified. If we add N storage nodes concurrently, the earlier proprietor for a slice shall be at most on the (N+1)th place within the Rendezvous hashing algorithm. Subsequently compute nodes can at all times discover a block by contacting the 2nd, third, …, (N+1)th server on the checklist (in parallel) if the block is out there within the scorching storage layer.
Eradicating storage nodes to lower capability
If the recent storage layer detects that it’s over provisioned, it’ll cut back the variety of nodes to lower price. Merely cutting down a node would end in learn misses to S3 whereas the remaining storage nodes obtain the information beforehand owned by the eliminated node. As a way to keep away from that, the node to be eliminated enters a “pre-draining” state:
- The storage node designated for deletion sends slices of knowledge to the next-in-line storage node. The following-in-line storage node is decided by Rendezvous hashing.
- As soon as all slices have been copied to the next-in-line storage node, the storage node designated for deletion is faraway from the Rendezvous hashing checklist. This ensures that the information is at all times out there for querying even within the means of cutting down storage nodes.
This design permits Rockset to offer 99.9999% cache hit charge of its scorching storage layer with out requiring extra replicas of the information. Moreover, it makes it quicker for Rockset to scale up or down the system.
The communication protocol between compute and storage nodes
To keep away from accessing S3 at question time, compute nodes need to request blocks from the storage nodes which are almost definitely to have information on their native disk. Compute nodes obtain this by means of an optimistic search protocol:
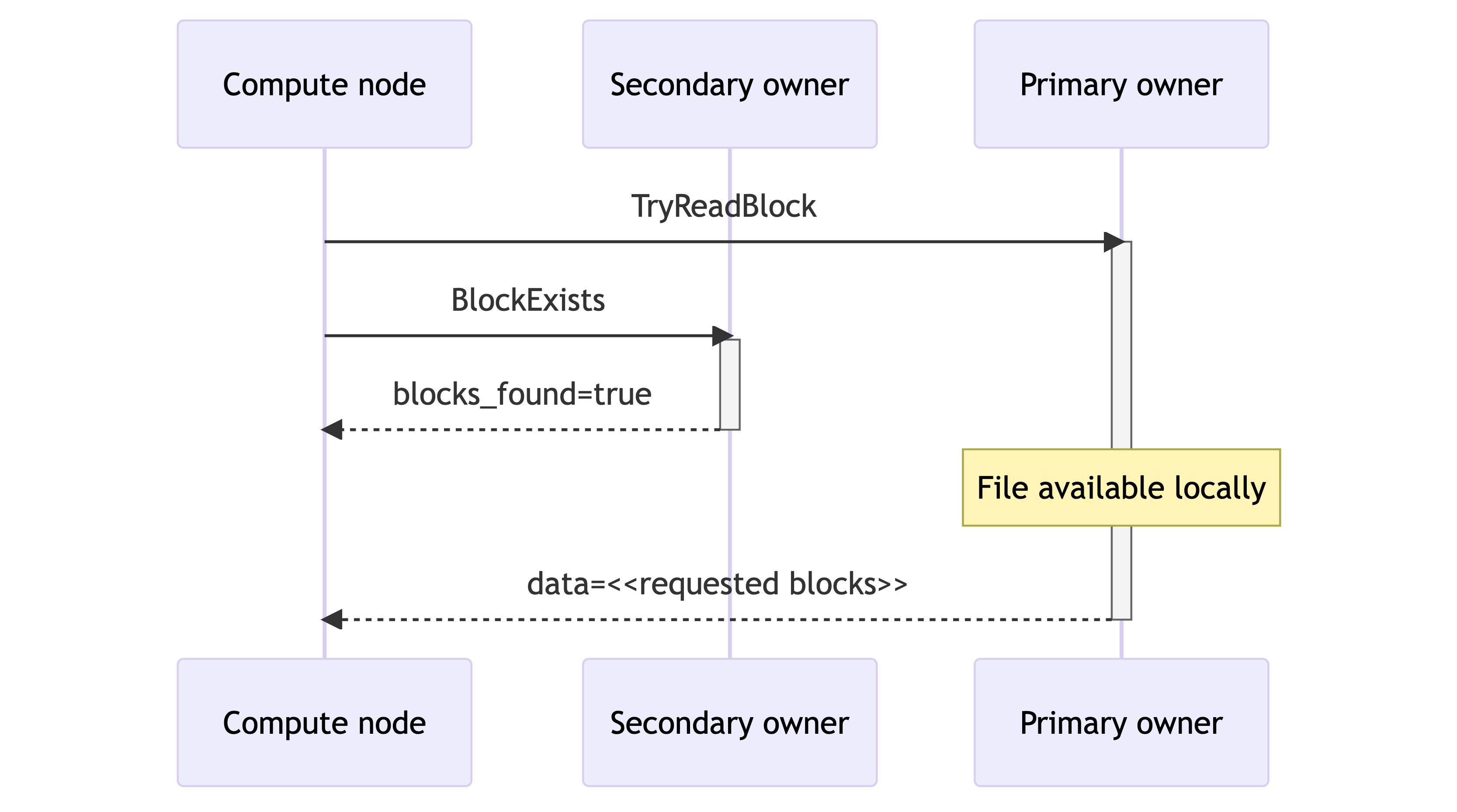
- The compute node sends a disk-only block request to the first proprietor by way of a TryReadBlock RPC. The RPC returns an empty end result if the block isn’t out there on the storage node’s native disk. In parallel, the compute node sends an existence test to the secondary proprietor by way of BlockExists that returns a boolean flag indicating whether or not the block is out there on the secondary proprietor.
- If the first proprietor returns the requested block as a part of the TryReadBlock response, the learn has been fulfilled. Equally, if the first proprietor didn’t have the information however the secondary proprietor did, as indicated by the BlockExists response, the compute node points a ReadBlock RPC to the secondary proprietor, thus fulfilling the learn.
- If neither proprietor can present the information instantly, the compute node sends a BlockExists RPC to the information slice’s designated failover vacation spot. That is the next-in-line storage node in response to Rendezvous Hashing. If the failover signifies that the block is out there regionally, the compute node reads from there.
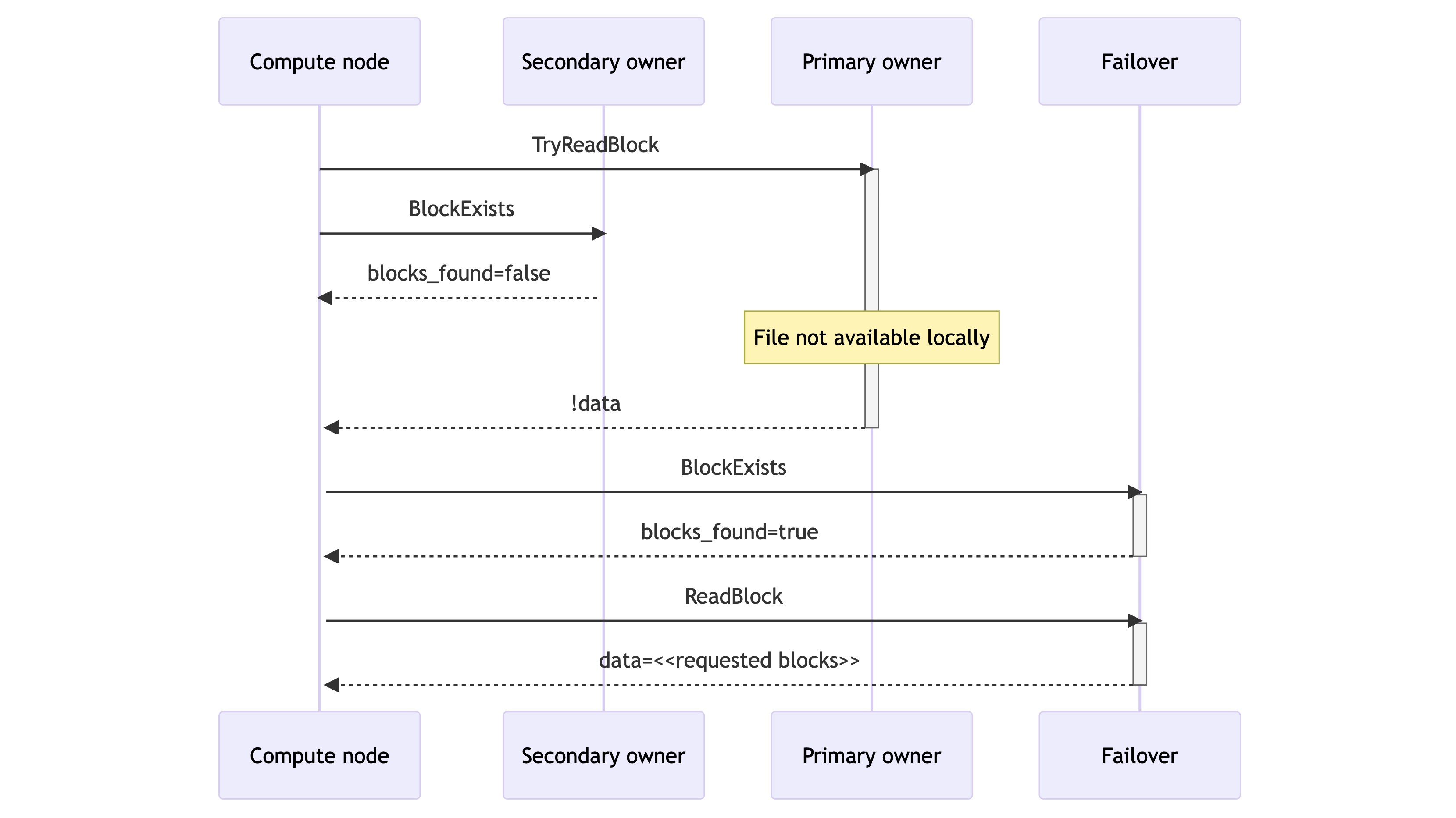
- If certainly one of these three storage nodes had the file regionally, then the learn may be happy shortly (<1ms). Within the extraordinarily uncommon case of an entire cache miss, the ReadBlock RPC satisfies the request with a synchronous obtain from S3 that takes 50-100ms. This preserves question availability however will increase question latency.
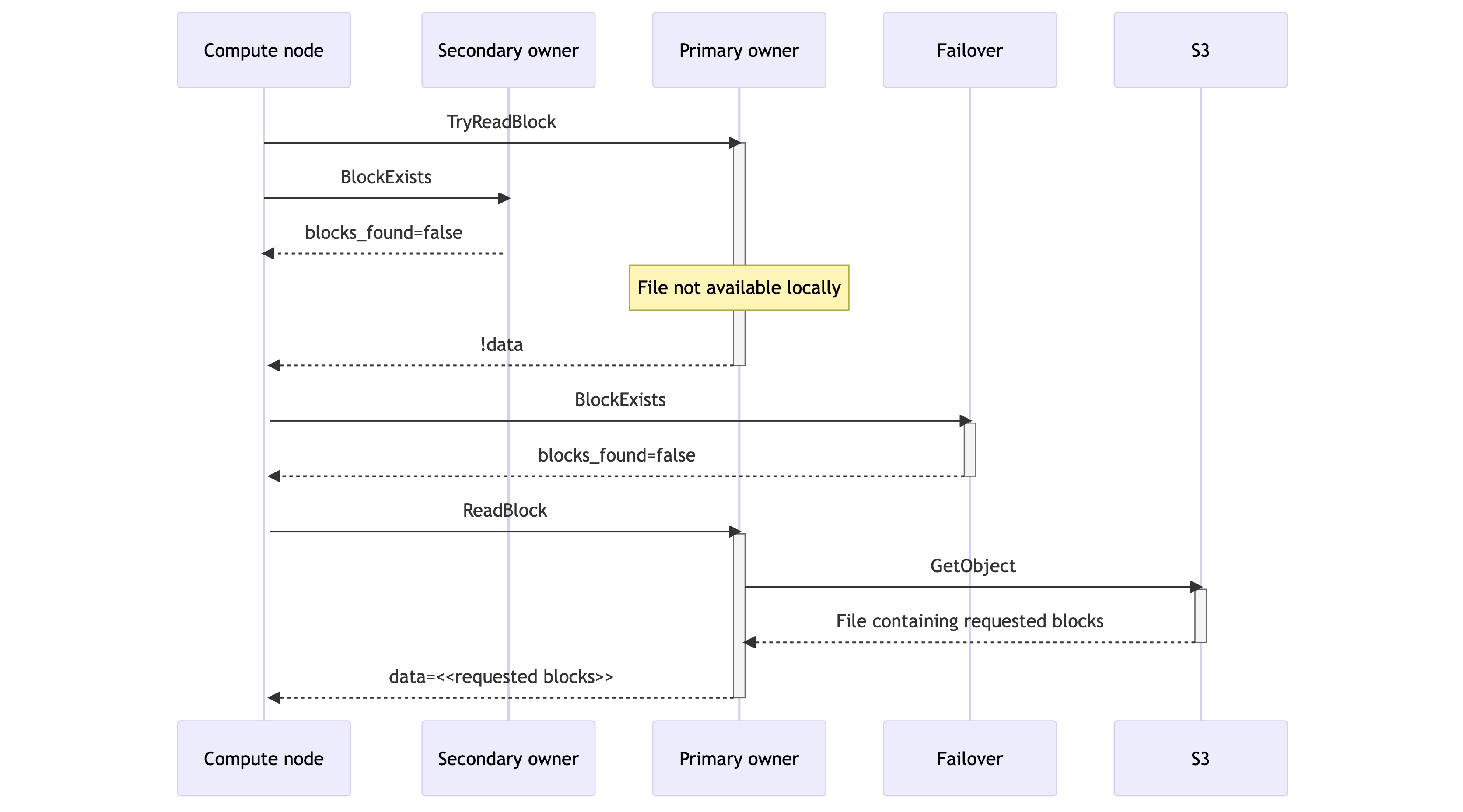
Targets of this protocol:
- Keep away from the necessity for synchronous S3 downloads, if the requested blocks are current anyplace within the scorching storage tier. The variety of failover storage nodes contacted by the compute node in (3) above may be bigger than one, to extend the probability of discovering the information block if it’s out there.
- Reduce load on storage nodes. Disk I/O bandwidth is a valuable useful resource on storage nodes. The storage node that fulfills the request is the one one that should learn information from the native disk. BlockExists is a really light-weight operation that doesn’t require disk entry.
- Reduce community visitors. To keep away from utilizing pointless community I/O bandwidth, solely one of many storage nodes returns the information. Sending two TryReadBlock requests to major and secondary homeowners in (1) would save one spherical journey in some conditions (i.e. if the first proprietor doesn’t have the information however the secondary proprietor does). Nevertheless, that’d double the quantity of knowledge despatched by means of the community for each block learn. The first proprietor returns the requested blocks within the overwhelming majority of circumstances, so sending duplicate information wouldn’t be a suitable trade-off.
- Make sure that the first and secondary homeowners are in sync with S3. The TryReadBlock and BlockExists RPCs will set off an asynchronous obtain from S3 if the underlying file wasn’t out there regionally. That method the underlying file shall be out there for future requests.
The search course of remembers the search outcomes so for future requests the compute nodes solely ship a single TryReadBlock RPC to the beforehand accessed known-good storage node with the information. This avoids the BlockExists RPC calls to the secondary proprietor.
Benefits of the Sizzling Storage Layer
Rockset disaggregates compute-storage and achieves related efficiency to tightly coupled methods with its scorching storage layer. The recent storage layer is a cache of S3 that’s constructed from the bottom as much as be performant by minimizing the overhead of requesting blocks by means of the community and calls to S3. To maintain the recent storage layer price-performant, it’s designed to restrict the variety of information copies, reap the benefits of all out there space for storing and scale up and down reliably. We launched zero downtime deploys to make sure that there isn’t a efficiency degradation when deploying new binaries.
On account of separating compute-storage, Rockset clients can run a number of purposes on shared, real-time information. New digital cases may be immediately spun up or down to satisfy altering ingestion and question calls for as a result of there isn’t a want to maneuver any information. Storage and compute may also be sized and scaled independently to save lots of on useful resource prices, making this cheaper than tightly coupled architectures like Elasticsearch.
The design of compute-storage separation was an important step in compute-compute separation the place we isolate streaming ingest compute and question compute for real-time, streaming workloads. As of the writing of this weblog, Rockset is the one real-time database that separates each compute-storage and compute-compute.
You possibly can study extra about how we use RocksDB at Rockset by studying the next blogs:
Authors:
Yashwanth Nannapaneni, Software program Engineer Rockset, and Esteban Talavera, Software program Engineer Rockset
[ad_2]