
[ad_1]
Introduction
In as we speak’s data-driven world, whether or not you’re a scholar seeking to extract insights from analysis papers or a knowledge analyst looking for solutions from datasets, we’re inundated with info saved in numerous file codecs. From analysis papers in PDF to stories in DOCX and plain textual content paperwork (TXT), to structured information in CSV recordsdata, there’s an ever-growing must entry and extract info from these various sources effectively. That’s the place the Multi-File Chatbot is available in – it’s a flexible software designed that will help you entry info saved in PDFs, DOCX recordsdata, TXT paperwork, and CSV datasets and course of a number of recordsdata concurrently.
Put together for an thrilling journey as we plunge into the intricacies of the code and functionalities that convey the Multi-File Chatbot to life. Get able to unlock the total potential of your information with the ability of Generative AI at your fingertips!
Studying Goals
Earlier than we dive into the small print, let’s define the important thing studying targets of this text:
- Implement textual content extraction from numerous file codecs (PDF, DOCX, TXT) and combine language fashions for pure language understanding, response era, and environment friendly query answering.
- Create a vector retailer from extracted textual content chunks for environment friendly info dealing with.
- Allow multi-file help, together with CSV uploads, for working with various doc varieties in a single session.
- Develop a user-friendly Streamlit interface for simple interplay with the chatbot.
This text was revealed as part of the Knowledge Science Blogathon.
What’s the Want for Multi-File Chatbot?
In as we speak’s digital age, the amount of knowledge saved in numerous file codecs has grown exponentially. The power to effectively entry and extract priceless insights from these various sources has develop into more and more important. This want has given rise to a Multi-File Chatbot, a specialised software designed to deal with these info retrieval challenges. File Chatbots, powered by superior Generative AI, are the way forward for info retrieval.
1.1 What’s a File Chatbot?
A File Chatbot is an modern software program utility powered by Synthetic Intelligence (AI) and Pure Language Processing (NLP) applied sciences. It’s tailor-made to research and extract info from a variety of file codecs, together with however not restricted to PDFs, DOCX paperwork, plain textual content recordsdata (TXT), and structured information in CSV recordsdata. In contrast to conventional chatbots that primarily work together with customers by textual content conversations, a File Chatbot focuses on understanding and responding to questions based mostly on the content material saved inside these recordsdata.
1.2 Use Circumstances
The utility of a Multi-File Chatbot extends throughout numerous domains and industries. Listed below are some key use instances that spotlight its significance:
1.2.1 Educational Analysis and Schooling
– Analysis Paper Evaluation: College students and researchers can use a File Chatbot to extract important info and insights from intensive analysis papers saved in PDF format. It might present summaries, reply particular questions, and support in literature evaluate processes.
–Textbook Help: Instructional establishments can deploy File Chatbots to help college students by answering questions associated to textbook content material, thereby enhancing the educational expertise.
1.2.2 Knowledge Evaluation and Enterprise Intelligence
- Knowledge Exploration: Knowledge analysts and enterprise professionals can make the most of a File Chatbot to work together with datasets saved in CSV recordsdata. It might reply queries about traits, correlations, and patterns inside the information, making it a priceless software for data-driven decision-making.
- Report Extraction: Chatbots can extract info from enterprise stories in DOCX format, serving to professionals shortly entry key metrics and insights.
1.2.3 Authorized and Compliance
- Authorized Doc Overview: Within the authorized subject, File Chatbots can help legal professionals by summarizing and extracting important particulars from prolonged authorized paperwork, corresponding to contracts and case briefs.
- Regulatory Compliance: Companies can use Chatbots to navigate complicated regulatory paperwork, guaranteeing they continue to be compliant with evolving legal guidelines and rules.
1.2.4 Content material Administration
- Archiving and Retrieval: Organizations can make use of File Chatbots to archive and retrieve paperwork effectively, making it simpler to entry historic data and knowledge.
1.2.5 Healthcare and Medical Analysis
- Medical Report Evaluation: Within the healthcare sector, Chatbots can help medical professionals in extracting priceless info from affected person data, aiding in prognosis and therapy selections.
- Analysis Knowledge Processing: Researchers can leverage Chatbots to research medical analysis papers and extract related findings for his or her research.
1.2.6 Buyer Help and FAQs
- Automated Help: Companies can combine File Chatbots into their buyer help methods to deal with queries and supply info from paperwork corresponding to FAQs, manuals, and guides.
The Workflow of a Information Chatbot
The workflow of a Multi-File Chatbot entails a number of key steps, from consumer interplay to file processing and answering questions. Right here’s a complete overview of the workflow
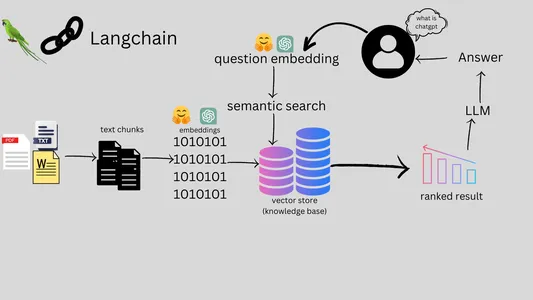
- Person interacts with Multi-File Chatbot through net or chat platform.
- Person submits question for chatbot’s info search.
- Person can add particular recordsdata (PDFs, DOCX, TXT, CSV).
- Chatbot processes textual content from uploaded recordsdata, contains cleansing and segmentation.
- Chatbot effectively indexes and shops processed textual content.
- Chatbot makes use of NLP for question understanding.
- Chatbot retrieves related information and generates solutions.
- Chatbot responds in pure language.
- Person will get response and may proceed interplay.
- Dialog continues with extra queries.
- Dialog ends at consumer’s discretion.
Setting Up Your Growth Atmosphere
Python Atmosphere Setup:
digital environments is an effective apply to isolate project-specific dependencies and keep away from conflicts with system-wide packages. Right here’s arrange a Python atmosphere:
Create a Digital Atmosphere:
- Open your terminal or command immediate.
- Navigate to your undertaking listing.
- Create a digital atmosphere (change env_name together with your most popular atmosphere title):
python -m venv env_name
Activate the Digital Atmosphere:
.env_nameScriptsactivate
supply env_name/bin/activateSet up Venture Dependencies:
- Whereas the digital atmosphere is energetic, navigate to your undertaking listing and set up the required libraries utilizing pip. This ensures that the libraries are put in inside your digital atmosphere, remoted from the worldwide Python atmosphere.
Required Dependencies
- langchain: Customized library for numerous NLP duties.
- PyPDF2: A library for working with PDF recordsdata, used for textual content extraction from PDF paperwork.
- python-docx: A library for working with DOCX recordsdata, used to extract textual content from DOCX paperwork.
- python-dotenv: A library for managing atmosphere variables, essential for holding delicate info safe.
- streamlit: A Python library for creating net functions with minimal code. It’s used to construct the consumer interface to your chatbot.
- openai: The OpenAI Python library, which may be used for particular NLP duties relying in your code.
- faiss-cpu: Faiss is a library for environment friendly similarity search and clustering of dense vectors, used for vector indexing in your code.
- altair: A declarative statistical visualization library in Python, probably used for information visualization in your undertaking.
- tiktoken: A Python library for counting the variety of tokens in a textual content string, which might be helpful for managing textual content information.
- huggingface-hub: A library for accessing fashions and assets from Hugging Face’s mannequin hub, used for accessing pre-trained fashions.
- InstructorEmbedding: Doubtlessly a customized embedding library or module used for particular NLP duties.
- sentence-transformers: A library for sentence embeddings, which might be helpful for numerous NLP duties involving sentence-level representations.
Observe: Select both Hugging Face or OpenAI to your language-related duties.
Coding the Multi-file Chatbot
4.1 Importing Dependencies
import streamlit as st
from docx import Doc
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.reminiscence import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from htmlTemplates import css, bot_template, user_template
from langchain.llms import HuggingFaceHub
import os
from dotenv import load_dotenv
import tempfile
from transformers import pipeline
import pandas as pd
import ioProcessing the under recordsdata:
PDF Information
# Extract textual content from a PDF file
def get_pdf_text(pdf_file):
textual content = ""
pdf_reader = PdfReader(pdf_file)
for web page in pdf_reader.pages:
textual content += web page.extract_text()
return textual contentDocx Information
# Extract textual content from a DOCX file
def get_word_text(docx_file):
doc = Doc(docx_file)
textual content = "n".be part of([paragraph.text for paragraph in document.paragraphs])
return textual contentTxt Information
# Extract textual content from a TXT file
def read_text_file(txt_file):
textual content = txt_file.getvalue().decode('utf-8')
return textual contentCSV Information
Along with PDFs and DOCX recordsdata, our chatbot can work with CSV recordsdata. We use the Hugging Face Transformers library to reply questions based mostly on tabular information. Right here’s how we deal with CSV recordsdata and consumer questions:
def handle_csv_file(csv_file, user_question):
# Learn the CSV file
csv_text = csv_file.learn().decode("utf-8")
# Create a DataFrame from the CSV textual content
df = pd.read_csv(io.StringIO(csv_text))
df = df.astype(str)
# Initialize a Hugging Face table-question-answering pipeline
qa_pipeline = pipeline("table-question-answering", mannequin="google/tapas-large-finetuned-wtq")
# Use the pipeline to reply the query
response = qa_pipeline(desk=df, question=user_question)
# Show the reply
st.write(response['answer'])4.3 Constructing a Information Base
The extracted textual content from totally different recordsdata is mixed and break up into manageable chunks. These chunks are then used to create an clever information base for the chatbot. We use state-of-the-art Pure Language Processing (NLP) methods to grasp the content material higher.
# Mix textual content from totally different recordsdata
def combine_text(text_list):
return "n".be part of(text_list)
# Break up textual content into chunks
def get_text_chunks(textual content):
text_splitter = CharacterTextSplitter(
separator="n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(textual content)
return chunksCreating vector retailer
Our undertaking seamlessly integrates Hugging Face fashions and LangChain for optimum efficiency.
def get_vectorstore(text_chunks):
#embeddings = OpenAIEmbeddings()
embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-xl")
vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)
return vectorstore4.4 Constructing a Conversational AI Mannequin
To allow our chatbot to supply significant responses, we’d like a conversational AI mannequin. On this undertaking, we use a mannequin from Hugging Face’s mannequin hub. Right here’s how we arrange the conversational AI mannequin:
def get_conversation_chain(vectorstore):
# llm = ChatOpenAI()
llm = HuggingFaceHub(
repo_id="google/flan-t5-xxl",
model_kwargs={"temperature": 0.5,
"max_length": 512})
reminiscence = ConversationBufferMemory(
memory_key='chat_history',
return_messages=True)
conversation_chain = Conversational
RetrievalChain.from_llm(
llm=llm,
retriever=vectorstore.as_retriever(),
reminiscence=reminiscence
)
return conversation_chain4.5 Answering Person Queries
Customers can ask questions associated to the paperwork they’ve uploaded. The chatbot makes use of its information base and NLP fashions to supply related solutions in real-time. Right here’s how we deal with consumer i
def handle_userinput(user_question):
if st.session_state.dialog isn't None:
response = st.session_state.dialog({'query': user_question})
st.session_state.chat_history = response['chat_history']
for i, message in enumerate(st.session_state.chat_history):
if i % 2 == 0:
st.write(user_template.change(
"{{MSG}}", message.content material), unsafe_allow_html=True)
else:
st.write(bot_template.change(
"{{MSG}}", message.content material), unsafe_allow_html=True)
else:
# Deal with the case when dialog isn't initialized
st.write("Please add and course of your paperwork first.")4.6 Deploying the Chatbot with Streamlit
We’ve deployed the chatbot utilizing Streamlit, a unbelievable Python library for creating net functions with minimal effort. Customers can add their paperwork and ask questions. The chatbot will generate responses based mostly on the content material of the paperwork. Right here’s how we arrange the Streamlit app:
def essential():
load_dotenv()
st.set_page_config(
page_title="File Chatbot",
page_icon=":books:",
structure="extensive"
)
st.write(css, unsafe_allow_html=True)
if "dialog" not in st.session_state:
st.session_state.dialog = None
if "chat_history" not in st.session_state:
st.session_state.chat_history = None
st.header("Chat together with your a number of recordsdata:")
user_question = st.text_input("Ask a query about your paperwork:")
# Initialize variables to carry uploaded recordsdata
csv_file = None
other_files = []
with st.sidebar:
st.subheader("Your paperwork")
recordsdata = st.file_uploader(
"Add your recordsdata right here and click on on 'Course of'", accept_multiple_files=True)
for file in recordsdata:
if file.title.decrease().endswith('.csv'):
csv_file = file # Retailer the CSV file
else:
other_files.append(file) # Retailer different file varieties
# Initialize empty lists for every file sort
pdf_texts = []
word_texts = []
txt_texts = []
if st.button("Course of"):
with st.spinner("Processing"):
for file in other_files:
if file.title.decrease().endswith('.pdf'):
pdf_texts.append(get_pdf_text(file))
elif file.title.decrease().endswith('.docx'):
word_texts.append(get_word_text(file))
elif file.title.decrease().endswith('.txt'):
txt_texts.append(read_text_file(file))
# Mix textual content from totally different file varieties
combined_text = combine_text(pdf_texts + word_texts + txt_texts)
# Break up the mixed textual content into chunks
text_chunks = get_text_chunks(combined_text)
# Create vector retailer and dialog chain if non-CSV paperwork are uploaded
if len(other_files) > 0:
vectorstore = get_vectorstore(text_chunks)
st.session_state.dialog = get_conversation_chain(vectorstore)
else:
vectorstore = None # No want for vectorstore with CSV file
# Deal with consumer enter for CSV file individually
if csv_file isn't None and user_question:
handle_csv_file(csv_file, user_question)
# Deal with consumer enter for text-based recordsdata
if user_question:
handle_userinput(user_question)
if __name__ == '__main__':
essential()
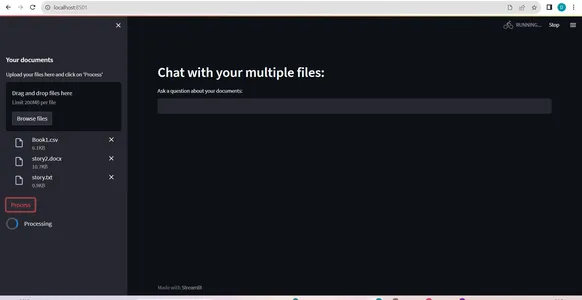
- Importing a number of recordsdata concurrently, together with CSV recordsdata, permitting for various doc varieties in a single session(refer: paperwork processing pic).
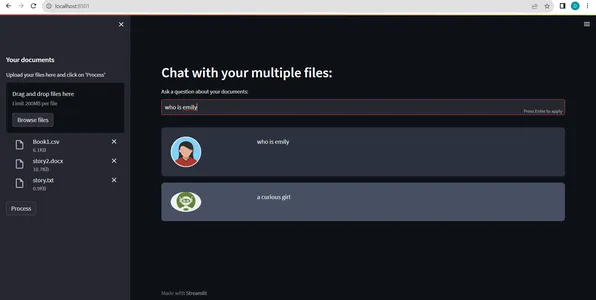
- The chatbot generates a response to the consumer’s question. This response is often in pure language and goals to supply a transparent and informative reply.(refer:pic2)
Scaling and Future Enhancements
As we embark on our Multi-File Chatbot undertaking, it’s essential to think about scalability and potential avenues for future enhancementsThe future holds thrilling potentialities with developments in Generative AI and NLP applied sciences. Listed below are key points to remember as you intend for the expansion and evolution of your chatbot:
1. Scalability
- Parallel Processing: To deal with a bigger variety of customers or extra intensive recordsdata, you’ll be able to discover parallel processing methods. This enables your chatbot to effectively course of a number of queries or paperwork concurrently.
- Load Balancing: Implement load balancing mechanisms to distribute consumer requests evenly throughout a number of servers or situations, guaranteeing constant efficiency throughout peak utilization.
2. Enhanced File Dealing with
- Help for Extra File Codecs: Think about increasing your chatbot’s capabilities by including help for extra file codecs generally utilized in your area. For instance, help for PowerPoint shows or Excel spreadsheets.
- Optical Character Recognition (OCR): Incorporate OCR know-how to extract textual content from scanned paperwork and pictures, broadening your chatbot’s scope.
3. Machine Studying Integration
- Energetic Studying: Implement energetic studying methods to repeatedly enhance your chatbot’s efficiency. Collect consumer suggestions and use it to fine-tune fashions and improve response accuracy.
- Customized Mannequin Coaching: Practice customized NLP fashions particular to your area for improved understanding and context-aware responses.
4. Superior Pure Language Processing
- Multi-Language Help: Lengthen your chatbot’s language capabilities to serve customers in a number of languages, broadening your consumer base.
- Sentiment Evaluation: Incorporate sentiment evaluation to gauge consumer feelings and tailor responses accordingly for a extra customized expertise.
5. Integration with Exterior Programs
- API Integration: Join your chatbot to exterior APIs, databases, or content material administration methods to fetch real-time information and supply dynamic responses.
- Net Scraping: Implement net scraping methods to collect info from web sites, additional enriching your chatbot’s information base.
6. Safety and Privateness
- Knowledge Encryption: Be sure that consumer information and delicate info are encrypted, and make use of safe authentication mechanisms to guard consumer privateness.
- Compliance: Keep up to date with information privateness rules and requirements to make sure compliance and trustworthiness.
7. Person Expertise Enhancements
- Contextual Understanding: Improve your chatbot’s capability to recollect and perceive the context of ongoing conversations, enabling extra pure and coherent interactions.
- Person Interface: Regularly refine the consumer interface (UI) to make it extra user-friendly and intuitive.
8. Efficiency Optimization
- Caching: Implement caching mechanisms to retailer continuously accessed information, decreasing response instances and server load.
- Useful resource Administration: Monitor and handle system assets to make sure environment friendly utilization and optimum efficiency.
9. Suggestions Mechanisms
- Person Suggestions: Encourage customers to supply suggestions on chatbot interactions, permitting you to establish areas for enchancment.
- Automated Suggestions Evaluation: Implement automated suggestions evaluation to achieve insights into consumer satisfaction and areas needing consideration.
10. Documentation and Coaching
- Person Guides: Present complete documentation and consumer guides to assist customers benefit from your chatbot.
- Coaching Modules: Develop coaching modules or tutorials for customers to grasp work together successfully with the chatbot.
Conclusion
On this weblog put up, we’ve explored the event of a Multi-File Chatbot utilizing Streamlit and Pure language processing(NLP) methods. This undertaking showcases extract textual content from numerous kinds of paperwork, course of consumer questions, and supply related solutions utilizing a conversational AI mannequin. With this chatbot, customers can effortlessly work together with their paperwork and achieve priceless insights. You possibly can additional improve this undertaking by integrating extra doc varieties and enhancing the conversational AI mannequin. Constructing such functions empowers customers to make higher use of their information and simplifies info retrieval from various sources. Begin constructing your personal Multi-File Chatbot and unlock the potential of your paperwork as we speak!
Key Takeaways
- Multi-File Chatbot Overview: The Multi-File Chatbot is a cutting-edge resolution powered by Generative AI and NLP applied sciences. It permits environment friendly entry and extraction of knowledge from various file codecs, together with PDFs, DOCX, TXT, and CSV.
- Numerous Use Circumstances: This chatbot has a variety of functions throughout domains, together with tutorial analysis, information evaluation, authorized and compliance, content material administration, healthcare, and buyer help.
- Workflow Overview: The chatbot’s workflow entails consumer interplay, file processing, textual content preprocessing, info retrieval, consumer question evaluation, reply era, response era, and ongoing interplay.
- Growth Atmosphere Setup: Organising a Python atmosphere with digital environments is crucial for isolating project-specific dependencies and guaranteeing easy growth.
- Coding the Chatbot: The event course of contains importing dependencies, extracting textual content from totally different file codecs, constructing a information base, organising a conversational AI mannequin, answering consumer queries, and deploying the chatbot utilizing Streamlit.
- Scalability and Future Enhancements: Concerns for scaling the chatbot and potential future enhancements embrace parallel processing, help for extra file codecs, machine studying integration, superior NLP, integration with exterior methods, safety and privateness, consumer expertise enhancements, efficiency optimization, and suggestions mechanisms.
Often Requested Questions
A. The accuracy of the chatbot’s responses could fluctuate based mostly on elements corresponding to the standard of the coaching information and the complexity of the consumer’s queries. Steady enchancment and fine-tuning of the chatbot’s fashions can improve accuracy over time.
A. The weblog mentions the usage of pre-trained fashions from Hugging Face’s mannequin hub and OpenAI for sure NLP duties. Relying in your undertaking’s necessities, you’ll be able to discover current pre-trained fashions or prepare customized fashions.
A. Many Multi-File Chatbots are designed to keep up context throughout conversations. They’ll keep in mind and perceive the context of ongoing interactions, permitting for extra pure and coherent responses to follow-up questions or queries associated to earlier discussions.
A. Whereas Multi-File Chatbots are versatile, their capability to deal with particular file codecs could depend upon the supply of libraries and instruments for textual content extraction and processing. On this weblog, we’re engaged on PDF, TXT, DOCS and CSV recordsdata. We are able to additionally add different file codecs and contemplate increasing help based mostly on consumer wants.
The media proven on this article isn’t owned by Analytics Vidhya and is used on the Creator’s discretion.
Associated
[ad_2]