
[ad_1]
At Databricks, we need to assist our prospects construct and deploy generative AI functions on their very own knowledge with out sacrificing knowledge privateness or management. For patrons who need to prepare a customized AI mannequin, we assist them achieve this simply, effectively, and at a low price. One lever we have now to handle this problem is ML {hardware} optimization; to that finish, we have now been working tirelessly to make sure our LLM stack can seamlessly assist a wide range of ML {hardware} platforms (e.g., NVIDIA [1][2], AMD [3][4]).
Immediately, we’re excited to debate one other main participant within the AI coaching and inference market: the Intel® Gaudi® household of AI Accelerators! These accelerators can be found through AWS (first-generation Gaudi), the Intel Developer Cloud (Gaudi 2), and for on-premise implementations, Supermicro and WiWynn (Gaudi and Gaudi 2 accelerators).
On this weblog, we profile the IntelR GaudiR 2 for LLM coaching utilizing our open-source LLM Foundry and for inference utilizing the open-source Optimum Habana library. We discover that general, the IntelR GaudiR 2 accelerator has the 2nd finest coaching performance-per-chip we have examined (solely bested by the NVIDIA H100), with over 260 TFLOP/s/machine achieved when coaching MPT-7B on 8 x Gaudi 2. For multi-node coaching, we had entry to 160x IntelR GaudiR 2 accelerators and located near-linear scaling throughout the cluster. For LLM inference, we profiled LLaMa2-70B and located that the 8 x Gaudi 2 system matches the 8 x H100 system in decoding latency (the most costly part of LLM inference).
As a result of the Gaudi 2 accelerator is publicly obtainable through the Intel Developer Cloud (IDC), we might additionally estimate performance-per-dollar. Primarily based on public, on-demand pricing on AWS and IDC, we discover that IntelR GaudiR 2 has the very best coaching and inference performance-per-dollar, beating out the NVIDIA A100-40GB, A100-80GB, and even H100!
All outcomes on this weblog had been measured utilizing SynapseAI 1.12 and BF16 combined precision coaching. Sooner or later, we stay up for exploring SynapseAI 1.13, which unlocks Gaudi 2’s assist for FP8 coaching, efficiently demonstrated of their MLPerf Coaching 3.1 GPT3 submission as reaching 379 TFLOP/s/machine on a cluster of 256xGaudi 2 and 368 TFLOP/s/machine on a cluster of 384xGaudi 2. These FP8 coaching outcomes are practically 1.5x sooner than our outcomes with BF16. SynapseAI 1.13 can also be anticipated to convey a elevate in LLM inference efficiency.
Learn on for particulars on the Intel Gaudi platform, LLM coaching and inference outcomes, LLM convergence outcomes, and extra. And, after all, be certain that to ask your cloud service supplier when they are going to be providing IntelR GaudiR 2 (obtainable now) and Gaudi 3, coming in 2024.
IntelR GaudiR 2 {Hardware}
The IntelR GaudiR 2 accelerator helps each deep studying coaching and inference for AI fashions like LLMs. The IntelR GaudiR 2 accelerator is constructed on a 7nm course of expertise. It has a heterogeneous compute structure that features twin matrix multiplication engines (MME) and 24 programmable tensor processor cores (TPC). When in comparison with fashionable cloud accelerators in the identical era, such because the NVIDIA A100-40GB and A100-80GB, the Gaudi 2 has extra reminiscence (96GB of HBM2E), increased reminiscence bandwidth, and better peak FLOP/s. Be aware that the AMD MI250 has increased specs per chip however is available in smaller system configurations of solely 4xMI250. In Desk 1a) we evaluate the IntelR GaudiR 2 towards the NVIDIA A100 and AMD MI250, and in Desk 1b) we evaluate the upcoming Intel Gaudi 3 towards the NVIDIA H100/H200 and AMD MI300X.
The IntelR GaudiR 2 accelerator ships in methods of 8x Gaudi 2 accelerators and has a novel scale-out networking design constructed on RDMA over Converged Ethernet (RoCEv2). Every Gaudi 2 accelerator integrates 24 x 100 Gbps Ethernet ports, with 21 ports devoted to all-to-all connectivity inside a system (3 hyperlinks to every of the seven different units) and the remaining three hyperlinks devoted to scaling out throughout methods. General, this implies every 8x Gaudi 2 system has 3 [scale-out links] * 8 [accelerators] * 100 [Gbps] = 2400 Gbps of exterior bandwidth. This design permits quick, environment friendly scale-out utilizing commonplace Ethernet {hardware}.
At Databricks, we obtained entry to a big multi-node IntelR GaudiR 2 cluster through the Intel Developer Cloud (IDC), which was used for all profiling performed on this weblog.
| IntelR GaudiR 2 | AMD MI250 | NVIDIA A100-40GB | NVIDIA A100-80GB | |||||
|---|---|---|---|---|---|---|---|---|
| Single Card | 8x Gaudi2 | Single Card | 4x MI250 | Single Card | 8x A100-40GB | Single Card | 8x A100-80GB | |
| FP16 or BF16 TFLOP/s | ~400 TFLOP/s | ~3200 TFLOP/s | 362 TFLOP/s | 1448 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s | 312 TFLOP/s | 2496 TFLOP/s |
| HBM Reminiscence (GB) | 96 GB | 768 GB | 128 GB | 512 GB | 40GB | 320 GB | 80GB | 640 GB |
| Reminiscence Bandwidth | 2450 GB/s | 19.6 TB/s | 3277 GB/s | 13.1 TB/s | 1555 GB/s | 12.4TB/s | 2039 GB/s | 16.3 TB/s |
| Peak Energy Consumption | 600W | 7500 W | 560W | 3000 W | 400W | 6500 W | 400W | 6500 W |
| Rack Models (RU) | N/A | 8U | N/A | 2U | N/A | 4U | N/A | 4U |
| Intel Gaudi3 | AMD MI300X | NVIDIA H100 | NVIDIA H200 | |||||
|---|---|---|---|---|---|---|---|---|
| Single Card | 8x Gaudi3 | Single Card | 8x MI300X | Single Card | 8x H100 | Single Card | 8x H200 | |
| FP16 or BF16 TFLOP/s | ~1600 TFLOP/s | ~12800 TFLOP/s | 1307 TFLOP/s | 10456 TFLOP/s | 989.5 TFLOP/s | 7916 TFLOP/s | 989.5 TFLOP/s | 7916 TFLOP/s |
| HBM Reminiscence (GB) | N/A | N/A | 192 GB | 1536 GB | 80GB | 640 GB | 141GB | 1128 GB |
| Reminiscence Bandwidth | ~3675 GB/s | ~29.4 TB/s | 5300 GB/s | 42.4 TB/s | 3350 GB/s | 26.8 TB/s | 4800 GB/s | 38.4 TB/s |
| Peak Energy Consumption | N/A | N/A | 750 W | N/A | 700 W | 10200 W | 700 W | 10200 W |
| Rack Models (RU) | N/A | N/A | N/A | 8U | N/A | 8U | N/A | 8U |
Desk 1a (high) and Desk 1b (backside): {Hardware} specs for NVIDIA, AMD, and Intel accelerators. Please be aware that solely a subset of specs have been launched publicly as of Dec 2023. The TFLOP/s numbers for Gaudi 2 are estimated utilizing microbenchmarks run by Databricks, and the TFLOP/s and Reminiscence Bandwidth for Gaudi 3 are projected utilizing public data from Intel.
Intel SynapseAI Software program
Intel® Gaudi SynapseAI software program suite crucially permits PyTorch packages to run seamlessly on Gaudi units with minimal modifications. SynapseAI supplies a graph compiler, a runtime, optimized kernels for tensor operations, and a collective communication library. Determine 1 reveals Intel Gaudi’s software program stack with all its key parts. Extra particulars about SynapseAI can be found within the official documentation.
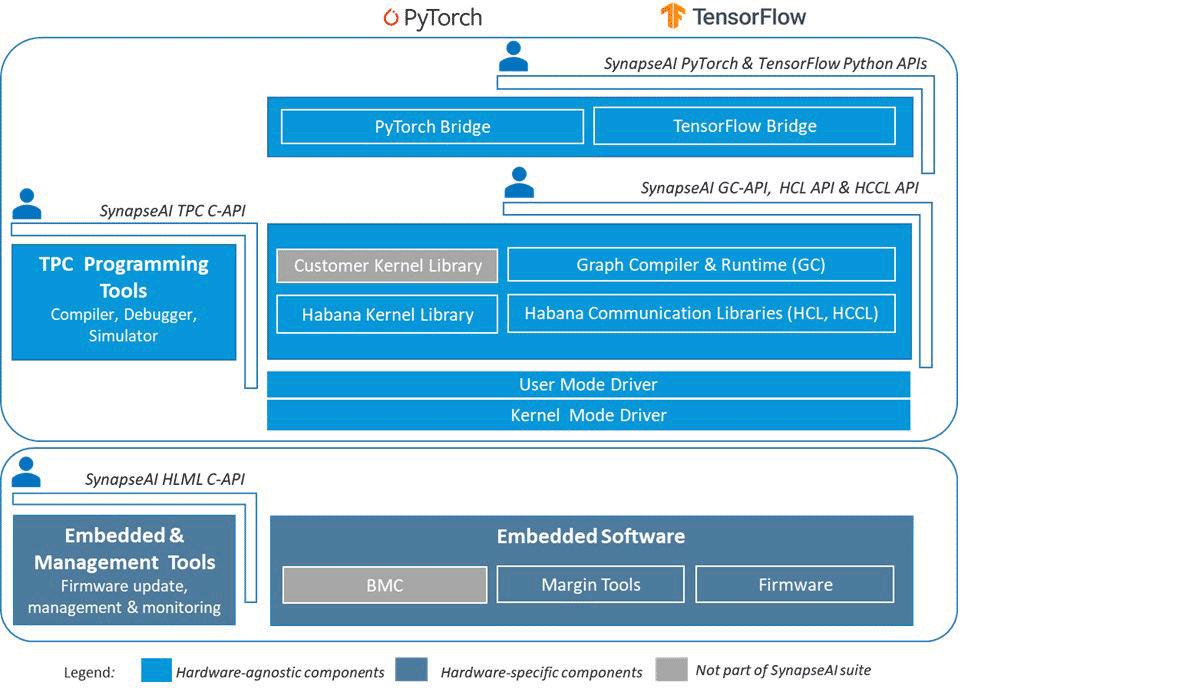
One of the fashionable libraries for ML programmers is PyTorch, and builders must be excited to know that PyTorch runs in keen mode or lazy mode on Intel accelerators like Gaudi 2. All it’s worthwhile to do is set up the Gaudi-provided construct of PyTorch (set up matrix right here) or begin from considered one of their Docker photographs. Usually, working HuggingFace/PyTorch code on Gaudi {hardware} requires minimal code modifications. These modifications sometimes embody substituting `tensor.cuda()` instructions with `tensor.to('hpu')` instructions or utilizing a PyTorch coach like Composer or HF Coach, which already has Gaudi assist inbuilt!
LLM Coaching Efficiency
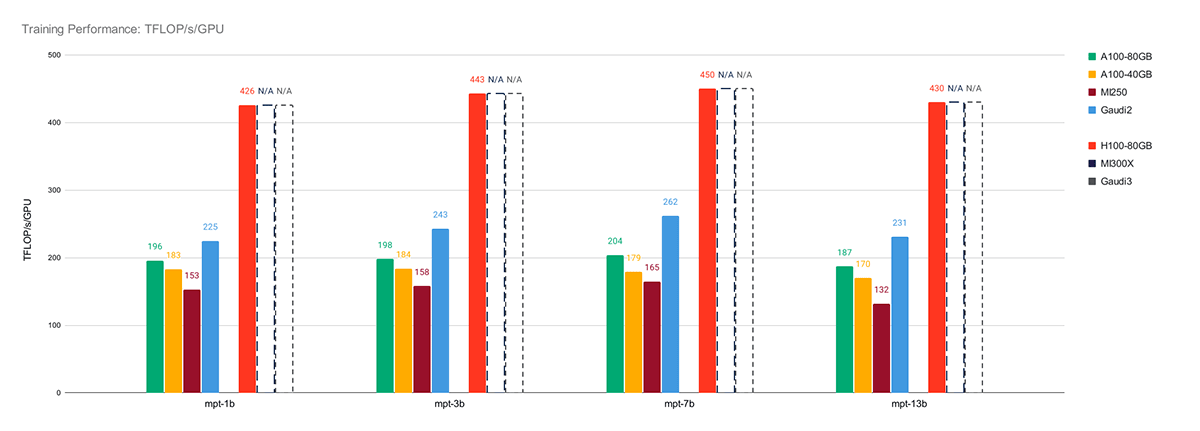
For single-node LLM coaching efficiency, we discovered that the IntelR GaudiR 2 is the 2nd-fastest AI chip available on the market in the present day, reaching over 260 TFLOP/s/machine with SynapseAI 1.12 and BF16 combined precision coaching. See Determine 2 for a comparability of the IntelR GaudiR 2 vs. NVIDIA and AMD GPUs.
On every platform, we ran the identical coaching scripts from LLM Foundry utilizing MPT fashions with a sequence size of 2048, BF16 combined precision, and the ZeRO Stage-3 distributed coaching algorithm. On NVIDIA or AMD methods, this algorithm is carried out through PyTorch FSDP with sharding_strategy: FULL_SHARD. On Intel methods, that is at present performed through DeepSpeed ZeRO with `stage: 3`, however FSDP assist is anticipated to be added within the close to future.
On every system, we additionally used essentially the most optimized implementation of scalar-dot-product-attention (SDPA) obtainable:
- NVIDIA: Triton FlashAttention-2
- AMD: ROCm ComposableKernel FlashAttention-2
- Intel: Gaudi TPC FusedSDPA
Lastly, we tuned the microbatch measurement for every mannequin on every system to realize most efficiency. All coaching efficiency measurements are reporting mannequin FLOPs somewhat than {hardware} FLOPs. See our benchmarking README for extra particulars.
When evaluating the IntelR GaudiR 2 towards the same-generation NVIDIA A100 and AMD MI250 GPUs, we discovered that Gaudi 2 is a transparent winner, with a mean speedup of 1.22x vs. the A100-80GB, 1.34x vs. the A100-40GB, and 1.59x vs. the MI250.
Compared towards the NVIDIA H100, there’s nonetheless a major hole to shut: on common, the IntelR GaudiR 2 performs at 0.55x the H100. Wanting ahead, the next-gen Intel Gaudi 3 has been publicly introduced to have 4x the BF16 efficiency of the Gaudi 2 and 1.5x the HBM bandwidth, making it a robust competitor to the H100.
Though this weblog focuses on BF16 coaching, we anticipate that FP8 coaching will quickly turn into an ordinary amongst main accelerators (NVIDIA H100/H200, AMD MI300X, IntelR GaudiR 2/Gaudi 3), and we stay up for reporting on these numbers in future blogs. For the IntelR GaudiR 2, FP8 coaching is supported, starting with SynapseAI model 1.13. For preliminary FP8 coaching outcomes for the NVIDIA H100 and IntelR GaudiR 2, try the MLPerf Coaching 3.1 GPT3 outcomes.
Now, efficiency is nice, however what about performance-per-dollar? Fortunately, pricing for each NVIDIA and Intel accelerators is publicly obtainable and can be utilized to compute a mean coaching performance-per-dollar. Be aware that the costs listed beneath are on-demand hourly charges and will not mirror costs after discounting, which could be cloud service supplier (CSP) and buyer particular:
| System | Cloud Service Supplier | On-Demand $/Hr | On-Demand $/Hr/System | Avg MPT Coaching BF16 Efficiency [TFLOP/s/Device] | Efficiency-per-dollar [ExaFLOP / $] |
|---|---|---|---|---|---|
| 8xA100-80GB | AWS | $40.79/hr | $5.12/hr/GPU | 196 | 0.1378 |
| 8xA100-40GB | AWS | $32.77/hr | $4.10/hr/GPU | 179 | 0.1572 |
| 4xMI250 | N/A | N/A | N/A | 152 | N/A |
| 8xGaudi 2 | IDC | $10.42/hr | $1.30/hr/System | 240 | 0.6646 |
| 8xH100 | AWS | $98.32/hr | $12.29/hr/GPU | 437 | 0.1280 |
Desk 2: Coaching Efficiency-per-Greenback for varied AI accelerators obtainable in Amazon Net Providers (AWS) and Intel Developer Cloud (IDC).
Primarily based on these public on-demand quoted costs from AWS and IDC, we discovered that the IntelR GaudiR 2 has the finest coaching performance-per-dollar, with a mean benefit of 4.8x vs the NVIDIA A100-80GB, 4.2x vs. the NVIDIA A100-40GB, and 5.19x vs. the NVIDIA H100. As soon as once more, these comparisons might range primarily based on customer-specific reductions on totally different cloud suppliers.
Transferring on to multi-node efficiency, the IntelR GaudiR 2 cluster has nice scaling efficiency for LLM coaching. In Determine 3, we skilled an MPT-7B mannequin with fastened world prepare batch measurement samples on [1, 2, 4, 10, 20] nodes and noticed a efficiency of 262 TFLOP/s/machine at one node (8x Gaudi 2) to 244 TFLOP/s/machine at 20 nodes (160x Gaudi 2). Be aware that for these outcomes, we used DeepSpeed with ZeRO Stage-2 somewhat than Stage-3 for optimum multi-node efficiency.
For extra particulars about our coaching configs and the way we measured efficiency, see our public LLM Foundry coaching benchmarking web page.
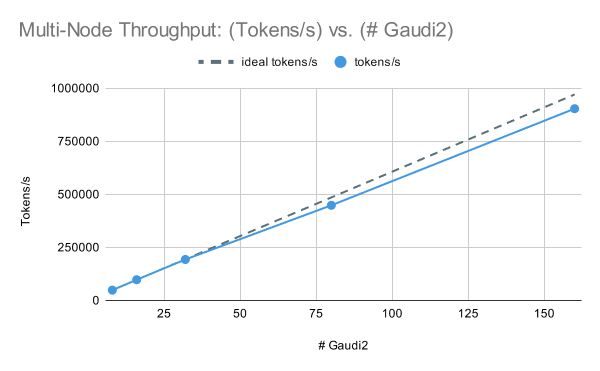
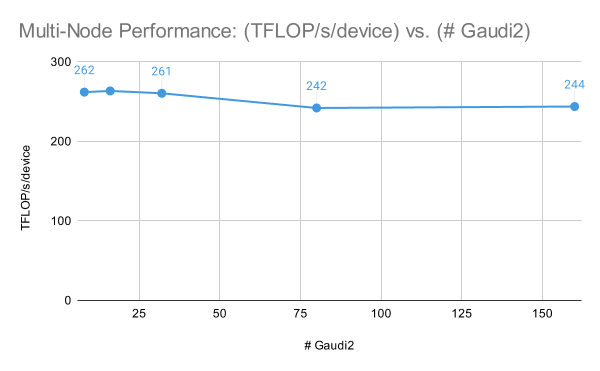
Given these outcomes, along with Intel’s MLPerf Coaching 3.1 outcomes coaching GPT3-175B on as much as 384x Gaudi 2, we’re optimistic about IntelR GaudiR 2 efficiency at increased machine counts, and we stay up for sharing outcomes on bigger IntelR GaudiR 2/Gaudi 3 clusters sooner or later.
LLM Convergence
To check coaching stability on IntelR GaudiR 2, we skilled MPT-1B, MPT-3B, and MPT-7B fashions from scratch on the C4 dataset utilizing Chinchilla-optimal token budgets to substantiate that we might efficiently prepare high-quality fashions on the Intel Gaudi platform.
We skilled every mannequin on the multi-node Gaudi 2 cluster with BF16 combined precision and DeepSpeed ZeRO Stage-2 for optimum efficiency. The 1B, 3B, and 7B fashions had been skilled on 64, 128, and 128 Gaudi 2 accelerators, respectively. General, we discovered that coaching was steady, and we noticed no points resulting from floating level numerics.
Once we evaluated the ultimate fashions on commonplace in-context-learning (ICL) benchmarks, we discovered that our MPT fashions skilled on IntelR GaudiR 2 achieved related outcomes to the open-source Cerebras-GPT fashions. These are a household of open-source fashions skilled with the identical parameter counts and token budgets, permitting us to check mannequin high quality immediately. See Desk 2 for outcomes. All fashions had been evaluated utilizing the LLM Foundry eval harness and utilizing the identical set of prompts.
These convergence outcomes give us confidence that prospects can prepare high-quality LLMs on Intel AI Accelerators.
![Figure 4: Training loss curves of MPT-[1B, 3B, 7B], each trained from scratch on multi-node Gaudi2 clusters with Chinchilla-optimal token budgets.](https://www.databricks.com/sites/default/files/inline-images/db-850-blog-image-5.png)
| Mannequin | Params | Tokens | ARC-c | ARC-e | BoolQ | Hellaswag | PIQA | Winograd | Winogrande | Common |
|---|---|---|---|---|---|---|---|---|---|---|
| Cerebras-GPT-1.3B | 1.3B | 26B | .245 | .445 | .583 | .380 | .668 | .630 | .522 | .496 |
| Intel-MPT-1B | 1.3B | 26B | .267 | .439 | .569 | .499 | .725 | .667 | .516 | .526 |
| Cerebras-GPT-2.7B | 2.7B | 53B | .263 | .492 | .592 | .482 | .712 | .733 | .558 | .547 |
| Intel-MPT-3B | 2.7B | 53B | .294 | .506 | .582 | .603 | .754 | .729 | .575 | .578 |
| Cerebras-GPT-6.7B | 6.7B | 133B | .310 | .564 | .625 | .582 | .743 | .777 | .602 | .600 |
| Intel-MPT-7B | 6.7B | 133B | .314 | .552 | .609 | .676 | .775 | .791 | .616 | .619 |
Desk 2: Coaching particulars and analysis outcomes for MPT-[1B, 3B, 7B] vs. Cerebras-GPT-[1.3B, 2.7B, 6.7B]. Every pair of fashions is skilled with related configurations and reaches related zero-shot accuracies (increased is healthier) on commonplace in-context-learning (ICL) duties.
LLM Inference
Transferring on to inference, we leveraged the Optimum Habana bundle to run inference benchmarks with LLMs from the HuggingFace Transformer library on Gaudi 2 {hardware}. Optimum Habana is an environment friendly middleman, facilitating seamless integration between the HuggingFace Transformer library and Gaudi 2 structure. This compatibility permits for direct, out-of-the-box deployment of supported HuggingFace fashions on Gaudi 2 platforms. Notably, after the mandatory packages had been put in, we noticed that the LLaMa2 mannequin household was suitable with the Gaudi 2 surroundings, enabling inference benchmarking to proceed easily with out requiring any modifications.
For our inference benchmarking on Nvidia’s A100 and H100 units, we utilized TRT-LLM (most important department as of 16/11/2023 when the experiments had been performed), a complicated inference resolution lately launched for LLMs. TRT-LLM is specifically designed to optimize the inference efficiency of LLMs on Nvidia {hardware}, leveraging the very best obtainable software program from varied NVIDIA libraries. We use the commonplace benchmark config supplied by NVidia’s TRT-LLM library to acquire these numbers. The usual benchmark config runs Llama-70B with GPT consideration and GEMM plugins utilizing the FP16 datatype. Please be aware that every one comparative numbers are performed with BF16 datatype on each the {hardware}. FP8 is accessible on each the {hardware} however not used for benchmarking right here. We hope to make the outcomes of FP8 experiments obtainable in a future weblog.
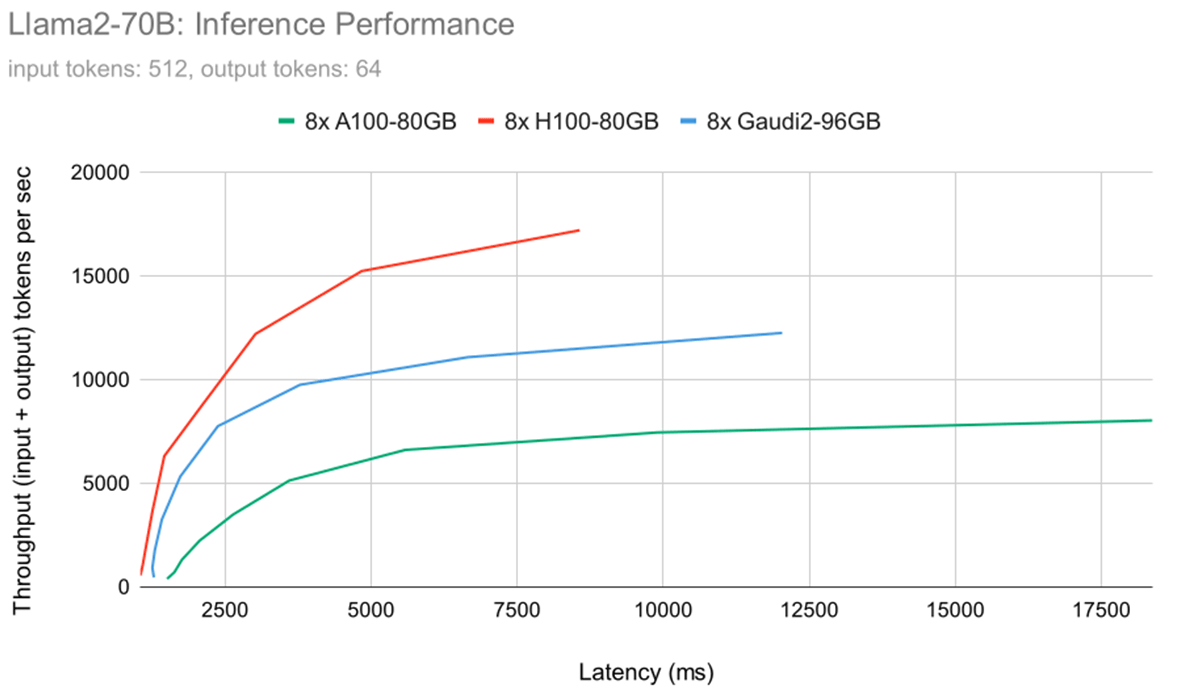
Determine 5 reveals the latency-throughput curves for the Llama2-70B mannequin for all three profiled {hardware} configurations. We used the identical mannequin and the identical enter/output lengths on all three {hardware} configurations. We used BF16 mannequin weights and math for all methods. This plot permits customers to estimate the achievable throughput on specified {hardware} configurations primarily based on a set latency goal. 8x Gaudi 2 sits between 8x A100-80GB and 8x H100 primarily based on these outcomes. Nevertheless, for smaller batch sizes (i.e., low latency regime), 8x Gaudi 2 is far nearer to 8xH100. Additional evaluation reveals that prefill time (i.e., immediate processing time) is far slower on Gaudi 2 than H100, whereas token era time on Gaudi 2 is just about equivalent, as proven within the subsequent figures. For instance, for 64 concurrent customers, the prefill time on H100 is 1.62 secs, whereas on Gaudi 2 it’s 2.45 secs. Slower prefill time could be improved by incorporating higher software program optimizations, however that is largely anticipated because of the massive hole in peak FLOPs (989.5 for H100 and ~400 for Gaudi 2). The following-gen Gaudi 3 is anticipated to shut this hole.
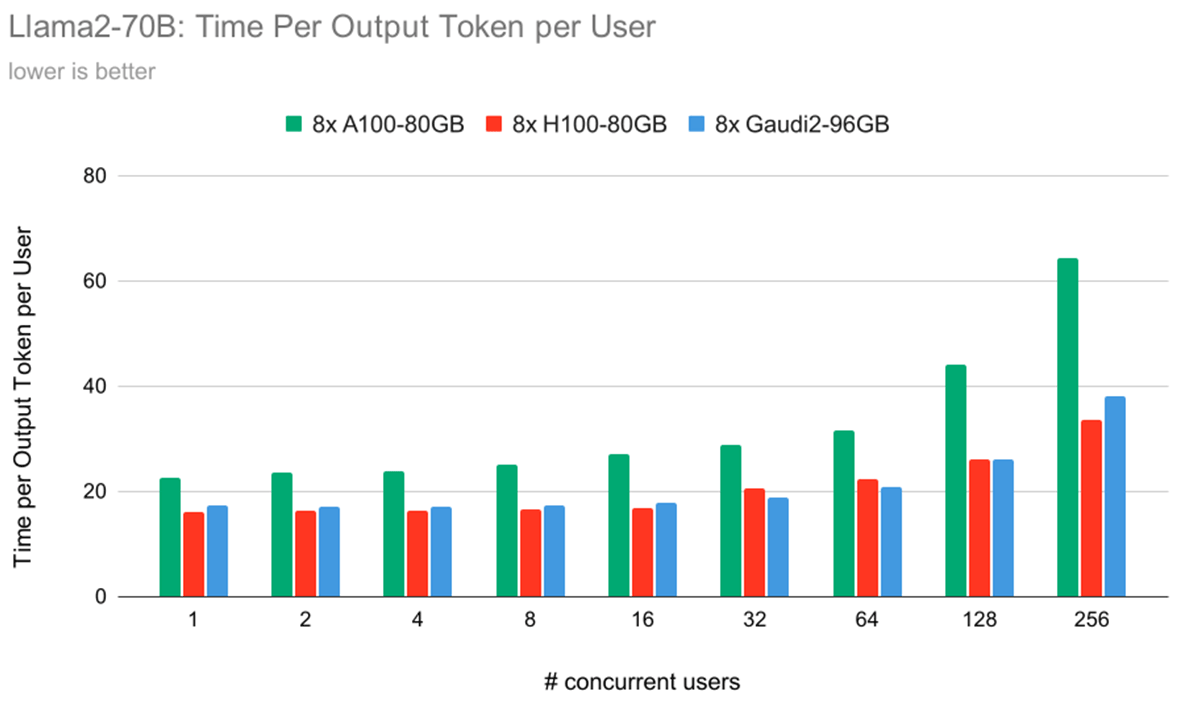
Determine 6 illustrates the time required for every {hardware} configuration to generate a single token per person. Notably, it highlights a key development: Time Per Output Token (TPOT) per person is +/-8% for IntelR GaudiR 2 vs. NVIDIA H100 below a lot of the person load eventualities. In some settings, the Gaudi 2 is quicker, and in different settings, the H100 is quicker. Normally, throughout all {hardware}, because the variety of concurrent customers will increase, the time taken to generate every token additionally will increase, resulting in lowered efficiency for each person. This correlation supplies useful insights into the scalability and effectivity of various {hardware} configurations below various person hundreds.
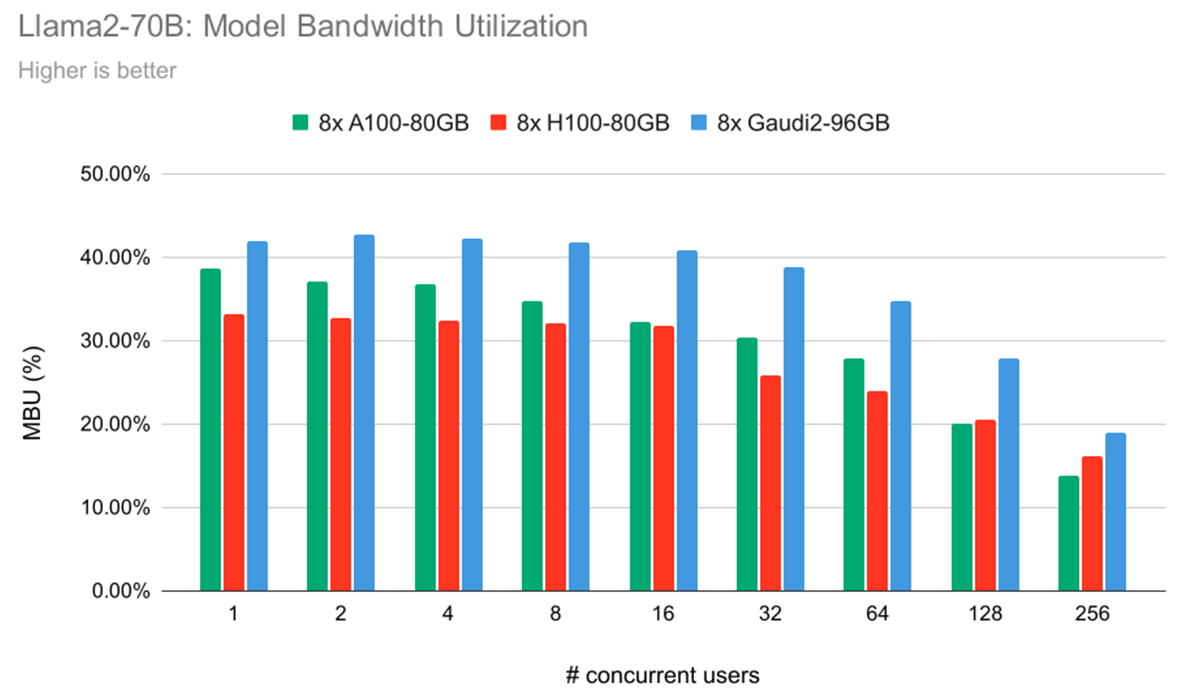
In Determine 7, we present a metric referred to as Mannequin Bandwidth Utilization (MBU). The idea of MBU is elaborated in better element in our earlier LLM Inference weblog publish. Briefly, it denotes the measure of effectivity in eventualities the place efficiency is primarily constrained by reminiscence bandwidth. The method of token era at smaller batch sizes predominantly hinges on achievable reminiscence bandwidth. Efficiency on this context is closely influenced by how successfully the software program and {hardware} can make the most of the height reminiscence bandwidth obtainable. In our experiments, we noticed that the IntelR GaudiR 2 platform demonstrates superior MBU in comparison with the H100 for token era duties. This means that IntelR GaudiR 2 is at present extra environment friendly at leveraging obtainable reminiscence bandwidth than the A100-80GB or H100.
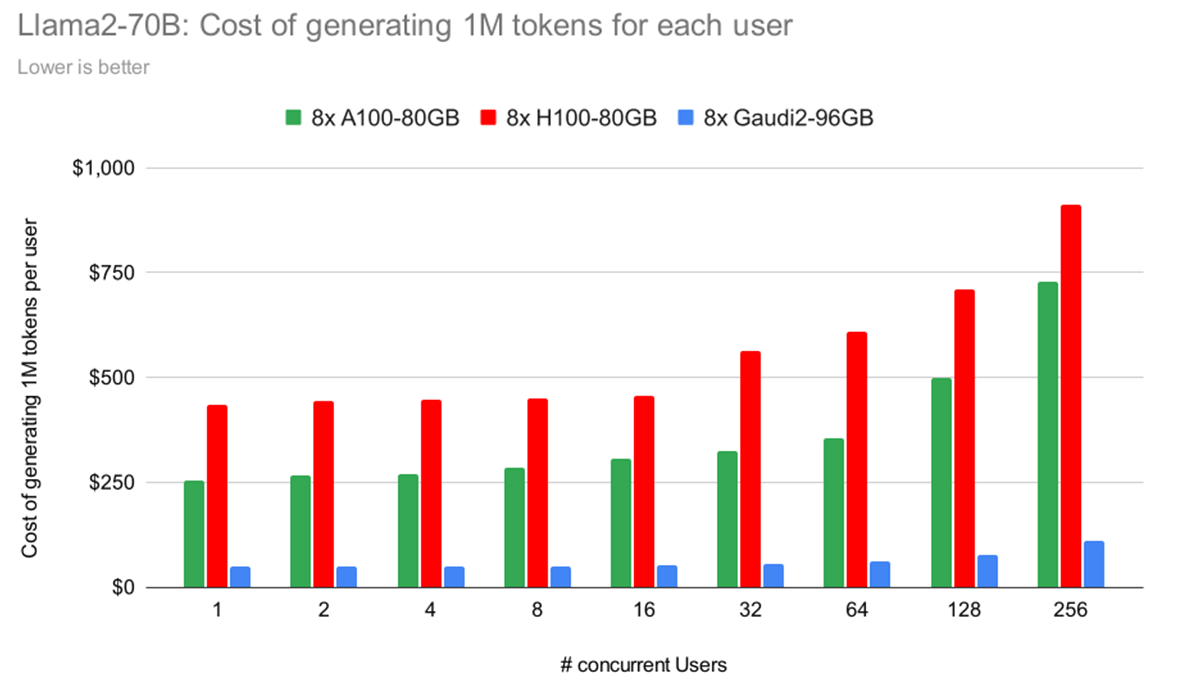
Lastly, in Determine 8, we illustrate the price of producing 1 million tokens per person throughout totally different {hardware} platforms. As an illustration, with 4 concurrent customers, the whole price depicted is for 4 million tokens (1 million per person). This calculation is predicated on the pricing particulars supplied in Desk 2.
Key insights from this knowledge embody:
- H100 is dearer than A100, primarily as a result of its hourly price is greater than double, whereas its efficiency positive aspects don’t proportionately match this enhance (as detailed in Determine 8).
- Gaudi 2 stands out resulting from its aggressive pricing, supplied by IDC, and efficiency ranges corresponding to H100, making it a compelling possibility.
You will need to be aware that not one of the benchmarked {hardware} makes use of FP8 (obtainable on H100 and Gaudi 2) or quantization.
What’s Subsequent?
On this weblog, we have demonstrated that the IntelR GaudiR 2 is a compelling possibility for LLM coaching and inference. Single-node and multi-node coaching on Gaudi 2 works nice. Efficiency-per-chip is the 2nd highest out of any accelerator we have now examined, and the performance-per-dollar is the very best when evaluating on-demand pricing on AWS and IDC. For convergence testing, we skilled Chinchilla-style 1B, 3B, and 7B parameter fashions from scratch and located that the ultimate mannequin qualities matched or exceeded reference open-source fashions.
On the inference aspect, we discovered that the Gaudi 2 punches above its weight, outperforming the NVIDIA A100 in all settings and matching the NVIDIA H100 in decoding latency (the most costly part of LLM inference). That is because of the IntelR GaudiR 2 software program and {hardware} stack, which achieves increased reminiscence bandwidth utilization than each NVIDIA chips. Placing it one other manner, with solely 2450 GB/s of HBM2E reminiscence bandwidth, the Gaudi 2 matches the H100 with 3350 GB/s of HBM3 bandwidth.
We imagine these outcomes strengthen the AI story for IntelR GaudiR 2 accelerators, and because of the interoperability of PyTorch and open-source libraries (e.g., DeepSpeed, Composer, StreamingDataset, LLM Foundry, Habana Optimum), customers can run the identical LLM workloads on NVIDIA, AMD, or Intel and even swap between the platforms.
Waiting for the Intel Gaudi 3, we anticipate the identical interoperability however with even increased efficiency. The projected public data specs (See Desk 1b) counsel that Intel Gaudi 3 ought to have extra FLOP/s and reminiscence bandwidth than all the key opponents (NVIDIA H100, AMD MI300X). Given the nice coaching and inference utilization numbers we already see in the present day on Gaudi 2, we’re very enthusiastic about Gaudi 3 and stay up for profiling it when it arrives. Keep tuned for future blogs on Intel Gaudi accelerators and coaching at a fair bigger scale.
[ad_2]