
[ad_1]
Amazon Kinesis Information Analytics makes it simple to remodel and analyze streaming information in actual time.
On this submit, we talk about why AWS recommends transferring from Kinesis Information Analytics for SQL Purposes to Amazon Kinesis Information Analytics for Apache Flink to reap the benefits of Apache Flink’s superior streaming capabilities. We additionally present easy methods to use Kinesis Information Analytics Studio to check and tune your evaluation earlier than deploying your migrated purposes. For those who don’t have any Kinesis Information Analytics for SQL purposes, this submit nonetheless gives a background on most of the use instances you’ll see in your information analytics profession and the way Amazon Information Analytics companies can assist you obtain your goals.
Kinesis Information Analytics for Apache Flink is a completely managed Apache Flink service. You solely must add your utility JAR or executable, and AWS will handle the infrastructure and Flink job orchestration. To make issues less complicated, Kinesis Information Analytics Studio is a pocket book surroundings that makes use of Apache Flink and means that you can question information streams and develop SQL queries or proof of idea workloads earlier than scaling your utility to manufacturing in minutes.
We advocate that you simply use Kinesis Information Analytics for Apache Flink or Kinesis Information Analytics Studio over Kinesis Information Analytics for SQL. It is because Kinesis Information Analytics for Apache Flink and Kinesis Information Analytics Studio supply superior information stream processing options, together with exactly-once processing semantics, occasion time home windows, extensibility utilizing user-defined features (UDFs) and customized integrations, crucial language assist, sturdy utility state, horizontal scaling, assist for a number of information sources, and extra. These are essential for making certain accuracy, completeness, consistency, and reliability of information stream processing and will not be out there with Kinesis Information Analytics for SQL.
Resolution overview
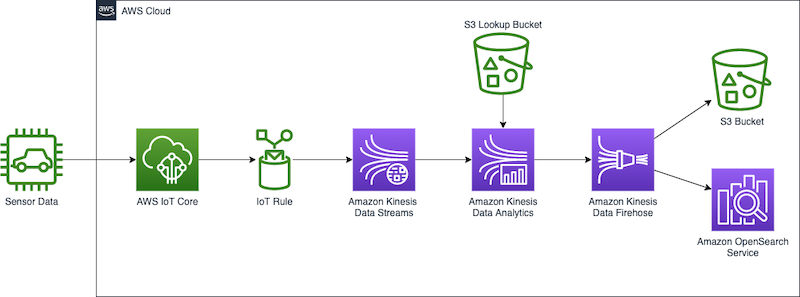
For our use case, we use a number of AWS companies to stream, ingest, rework, and analyze pattern automotive sensor information in actual time utilizing Kinesis Information Analytics Studio. Kinesis Information Analytics Studio permits us to create a pocket book, which is a web-based growth surroundings. With notebooks, you get a easy interactive growth expertise mixed with the superior capabilities offered by Apache Flink. Kinesis Information Analytics Studio makes use of Apache Zeppelin because the pocket book, and makes use of Apache Flink because the stream processing engine. Kinesis Information Analytics Studio notebooks seamlessly mix these applied sciences to make superior analytics on information streams accessible to builders of all talent units. Notebooks are provisioned rapidly and supply a method so that you can immediately view and analyze your streaming information. Apache Zeppelin gives your Studio notebooks with an entire suite of analytics instruments, together with the next:
- Information visualization
- Exporting information to recordsdata
- Controlling the output format for simpler evaluation
- Skill to show the pocket book right into a scalable, manufacturing utility
In contrast to Kinesis Information Analytics for SQL Purposes, Kinesis Information Analytics for Apache Flink provides the following SQL assist:
- Becoming a member of stream information between a number of Kinesis information streams, or between a Kinesis information stream and an Amazon Managed Streaming for Apache Kafka (Amazon MSK) subject
- Actual-time visualization of reworked information in an information stream
- Utilizing Python scripts or Scala packages throughout the identical utility
- Altering offsets of the streaming layer
One other good thing about Kinesis Information Analytics for Apache Flink is the improved scalability of the answer as soon as deployed, as a result of you may scale the underlying assets to satisfy demand. In Kinesis Information Analytics for SQL Purposes, scaling is carried out by including extra pumps to influence the appliance into including extra assets.
In our answer, we create a pocket book to entry automotive sensor information, enrich the information, and ship the enriched output from the Kinesis Information Analytics Studio pocket book to an Amazon Kinesis Information Firehose supply stream for supply to an Amazon Easy Storage Service (Amazon S3) information lake. This pipeline might additional be used to ship information to Amazon OpenSearch Service or different targets for extra processing and visualization.
Kinesis Information Analytics for SQL Purposes vs. Kinesis Information Analytics for Apache Flink
In our instance, we carry out the next actions on the streaming information:
- Hook up with an Amazon Kinesis Information Streams information stream.
- View the stream information.
- Remodel and enrich the information.
- Manipulate the information with Python.
- Restream the information to a Firehose supply stream.
To match Kinesis Information Analytics for SQL Purposes with Kinesis Information Analytics for Apache Flink, let’s first talk about how Kinesis Information Analytics for SQL Purposes works.
On the root of a Kinesis Information Analytics for SQL utility is the idea of an in-application stream. You may consider the in-application stream as a desk that holds the streaming information so you may carry out actions on it. The in-application stream is mapped to a streaming supply similar to a Kinesis information stream. To get information into the in-application stream, first arrange a supply within the administration console to your Kinesis Information Analytics for SQL utility. Then, create a pump that reads information from the supply stream and locations it into the desk. The pump question runs repeatedly and feeds the supply information into the in-application stream. You may create a number of pumps from a number of sources to feed the in-application stream. Queries are then run on the in-application stream, and outcomes could be interpreted or despatched to different locations for additional processing or storage.
The next SQL demonstrates organising an in-application stream and pump:
CREATE OR REPLACE STREAM "TEMPSTREAM" (
"column1" BIGINT NOT NULL,
"column2" INTEGER,
"column3" VARCHAR(64));
CREATE OR REPLACE PUMP "SAMPLEPUMP" AS
INSERT INTO "TEMPSTREAM" ("column1",
"column2",
"column3")
SELECT STREAM inputcolumn1,
inputcolumn2,
inputcolumn3
FROM "INPUTSTREAM";Information could be learn from the in-application stream utilizing a SQL SELECT question:
SELECT *
FROM "TEMPSTREAM"When creating the identical setup in Kinesis Information Analytics Studio, you employ the underlying Apache Flink surroundings to connect with the streaming supply, and create the information stream in a single assertion utilizing a connector. The next instance reveals connecting to the identical supply we used earlier than, however utilizing Apache Flink:
CREATE TABLE `MY_TABLE` (
"column1" BIGINT NOT NULL,
"column2" INTEGER,
"column3" VARCHAR(64)
) WITH (
'connector' = 'kinesis',
'stream' = sample-kinesis-stream',
'aws.area' = 'aws-kinesis-region',
'scan.stream.initpos' = 'LATEST',
'format' = 'json'
);MY_TABLE is now an information stream that may frequently obtain the information from our pattern Kinesis information stream. It may be queried utilizing a SQL SELECT assertion:
SELECT column1,
column2,
column3
FROM MY_TABLE;Though Kinesis Information Analytics for SQL Purposes use a subset of the SQL:2008 commonplace with extensions to allow operations on streaming information, Apache Flink’s SQL assist is predicated on Apache Calcite, which implements the SQL commonplace.
It’s additionally necessary to say that Kinesis Information Analytics Studio helps PyFlink and Scala alongside SQL throughout the identical pocket book. This lets you carry out advanced, programmatic strategies in your streaming information that aren’t doable with SQL.
Stipulations
Throughout this train, we arrange varied AWS assets and carry out analytics queries. To observe alongside, you want an AWS account with administrator entry. For those who don’t have already got an AWS account with administrator entry, create one now. The companies outlined on this submit could incur expenses to your AWS account. Be certain to observe the cleanup directions on the finish of this submit.
Configure streaming information
Within the streaming area, we’re usually tasked with exploring, reworking, and enriching information coming from Web of Issues (IoT) sensors. To generate the real-time sensor information, we make use of the AWS IoT System Simulator. This simulator runs inside your AWS account and gives an internet interface that lets customers launch fleets of just about related gadgets from a user-defined template after which simulate them to publish information at common intervals to AWS IoT Core. This implies we are able to construct a digital fleet of gadgets to generate pattern information for this train.
We deploy the IoT System Simulator utilizing the next Amazon CloudFront template. It handles creating all the required assets in your account.
- On the Specify stack particulars web page, assign a reputation to your answer stack.
- Underneath Parameters, overview the parameters for this answer template and modify them as obligatory.
- For Consumer e-mail, enter a legitimate e-mail to obtain a hyperlink and password to log in to the IoT System Simulator UI.
- Select Subsequent.
- On the Configure stack choices web page, select Subsequent.
- On the Overview web page, overview and make sure the settings. Choose the examine packing containers acknowledging that the template creates AWS Id and Entry Administration (IAM) assets.
- Select Create stack.
The stack takes about 10 minutes to put in.
- While you obtain your invitation e-mail, select the CloudFront hyperlink and log in to the IoT System Simulator utilizing the credentials offered within the e-mail.
The answer incorporates a prebuilt automotive demo that we are able to use to start delivering sensor information rapidly to AWS.
- On the System Sort web page, select Create System Sort.
- Select Automotive Demo.
- The payload is auto populated. Enter a reputation to your system, and enter
automotive-topicas the subject.
- Select Save.
Now we create a simulation.
- On the Simulations web page, select Create Simulation.
- For Simulation sort, select Automotive Demo.
- For Choose a tool sort, select the demo system you created.
- For Information transmission interval and Information transmission period, enter your required values.
You may enter any values you want, however use at the least 10 gadgets transmitting each 10 seconds. You’ll wish to set your information transmission period to a couple minutes, otherwise you’ll must restart your simulation a number of instances through the lab.
- Select Save.

Now we are able to run the simulation.
- On the Simulations web page, choose the specified simulation, and select Begin simulations.
Alternatively, select View subsequent to the simulation you wish to run, then select Begin to run the simulation.
- To view the simulation, select View subsequent to the simulation you wish to view.
If the simulation is working, you may view a map with the areas of the gadgets, and as much as 100 of the newest messages despatched to the IoT subject.
We will now examine to make sure our simulator is sending the sensor information to AWS IoT Core.
- Navigate to the AWS IoT Core console.
Ensure you’re in the identical Area you deployed your IoT System Simulator.
- Within the navigation pane, select MQTT Take a look at Shopper.
- Enter the subject filter
automotive-topicand select Subscribe.
So long as you will have your simulation working, the messages being despatched to the IoT subject might be displayed.

Lastly, we are able to set a rule to route the IoT messages to a Kinesis information stream. This stream will present our supply information for the Kinesis Information Analytics Studio pocket book.
- On the AWS IoT Core console, select Message Routing and Guidelines.
- Enter a reputation for the rule, similar to
automotive_route_kinesis, then select Subsequent.
- Present the next SQL assertion. This SQL will choose all message columns from the
automotive-topicthe IoT System Simulator is publishing:
- Select Subsequent.
- Underneath Rule Actions, choose Kinesis Stream because the supply.
- Select Create New Kinesis Stream.
This opens a brand new window.
- For Information stream title, enter
automotive-data.
We use a provisioned stream for this train.

- Select Create Information Stream.
You might now shut this window and return to the AWS IoT Core console.
- Select the refresh button subsequent to Stream title, and select the
automotive-datastream.
- Select Create new position and title the position
automotive-role. - Select Subsequent.
- Overview the rule properties, and select Create.
The rule begins routing information instantly.
Arrange Kinesis Information Analytics Studio
Now that we have now our information streaming via AWS IoT Core and right into a Kinesis information stream, we are able to create our Kinesis Information Analytics Studio pocket book.
- On the Amazon Kinesis console, select Analytics purposes within the navigation pane.
- On the Studio tab, select Create Studio pocket book.

- Depart Fast create with pattern code chosen.
- Title the pocket book
automotive-data-notebook.
- Select Create to create a brand new AWS Glue database in a brand new window.
- Select Add database.

- Title the database
automotive-notebook-glue. - Select Create.

- Return to the Create Studio pocket book part.
- Select refresh and select your new AWS Glue database.
- Select Create Studio pocket book.

- To begin the Studio pocket book, select Run and make sure.

- As soon as the pocket book is working, select the pocket book and select Open in Apache Zeppelin.
- Select Import word.
- Select Add from URL.

- Enter the next URL:
https://aws-blogs-artifacts-public.s3.amazonaws.com/artifacts/BDB-2461/auto-notebook.ipynb. - Select Import Notice.

- Open the brand new word.
Carry out stream evaluation
In a Kinesis Information Analytics for SQL utility, we add our streaming course by way of the administration console, after which outline an in-application stream and pump to stream information from our Kinesis information stream. The in-application stream features as a desk to carry the information and make it out there for us to question. The pump takes the information from our supply and streams it to our in-application stream. Queries could then be run in opposition to the in-application stream utilizing SQL, simply as we’d question any SQL desk. See the next code:
CREATE OR REPLACE STREAM "AUTOSTREAM" (
`trip_id` CHAR(36),
`VIN` CHAR(17),
`brake` FLOAT,
`steeringWheelAngle` FLOAT,
`torqueAtTransmission` FLOAT,
`engineSpeed` FLOAT,
`vehicleSpeed` FLOAT,
`acceleration` FLOAT,
`parkingBrakeStatus` BOOLEAN,
`brakePedalStatus` BOOLEAN,
`transmissionGearPosition` VARCHAR(10),
`gearLeverPosition` VARCHAR(10),
`odometer` FLOAT,
`ignitionStatus` VARCHAR(4),
`fuelLevel` FLOAT,
`fuelConsumedSinceRestart` FLOAT,
`oilTemp` FLOAT,
`location` VARCHAR(100),
`timestamp` TIMESTAMP(3));
CREATE OR REPLACE PUMP "MYPUMP" AS
INSERT INTO "AUTOSTREAM" ("trip_id",
"VIN",
"brake",
"steeringWheelAngle",
"torqueAtTransmission",
"engineSpeed",
"vehicleSpeed",
"acceleration",
"parkingBrakeStatus",
"brakePedalStatus",
"transmissionGearPosition",
"gearLeverPosition",
"odometer",
"ignitionStatus",
"fuelLevel",
"fuelConsumedSinceRestart",
"oilTemp",
"location",
"timestamp")
SELECT VIN,
brake,
steeringWheelAngle,
torqueAtTransmission,
engineSpeed,
vehicleSpeed,
acceleration,
parkingBrakeStatus,
brakePedalStatus,
transmissionGearPosition,
gearLeverPosition,
odometer,
ignitionStatus,
fuelLevel,
fuelConsumedSinceRestart,
oilTemp,
location,
timestamp
FROM "INPUT_STREAM"
Emigrate an in-application stream and pump from our Kinesis Information Analytics for SQL utility to Kinesis Information Analytics Studio, we convert this right into a single CREATE assertion by eradicating the pump definition and defining a kinesis connector. The primary paragraph within the Zeppelin pocket book units up a connector that’s offered as a desk. We will outline columns for all gadgets within the incoming message, or a subset.

Run the assertion, and a hit result’s output in your pocket book. We will now question this desk utilizing SQL, or we are able to carry out programmatic operations with this information utilizing PyFlink or Scala.
Earlier than performing real-time analytics on the streaming information, let’s take a look at how the information is at present formatted. To do that, we run a easy Flink SQL question on the desk we simply created. The SQL utilized in our streaming utility is similar to what’s utilized in a SQL utility.

Notice that for those who don’t see data after a number of seconds, guarantee that your IoT System Simulator remains to be working.
For those who’re additionally working the Kinesis Information Analytics for SQL code, you may even see a barely completely different end result set. That is one other key differentiator in Kinesis Information Analytics for Apache Flink, as a result of the latter has the idea of precisely as soon as supply. If this utility is deployed to manufacturing and is restarted or if scaling actions happen, Kinesis Information Analytics for Apache Flink ensures you solely obtain every message as soon as, whereas in a Kinesis Information Analytics for SQL utility, you want to additional course of the incoming stream to make sure you ignore repeat messages that would have an effect on your outcomes.
You may cease the present paragraph by selecting the pause icon. You may even see an error displayed in your pocket book while you cease the question, however it may be ignored. It’s simply letting you recognize that the method was canceled.

Flink SQL implements the SQL commonplace, and gives a straightforward method to carry out calculations on the stream information identical to you’ll when querying a database desk. A typical process whereas enriching information is to create a brand new discipline to retailer a calculation or conversion (similar to from Fahrenheit to Celsius), or create new information to offer less complicated queries or improved visualizations downstream. Run the following paragraph to see how we are able to add a Boolean worth named accelerating, which we are able to simply use in our sink to know if an vehicle was at present accelerating on the time the sensor was learn. The method right here doesn’t differ between Kinesis Information Analytics for SQL and Kinesis Information Analytics for Apache Flink.

You may cease the paragraph from working when you will have inspected the brand new column, evaluating our new Boolean worth to the FLOAT acceleration column.
Information being despatched from a sensor is normally compact to enhance latency and efficiency. With the ability to enrich the information stream with exterior information and enrich the stream, similar to further automobile data or present climate information, could be very helpful. On this instance, let’s assume we wish to usher in information at present saved in a CSV in Amazon S3, and add a column named colour that displays the present engine pace band.
Apache Flink SQL gives a number of supply connectors for AWS companies and different sources. Creating a brand new desk like we did in our first paragraph however as a substitute utilizing the filesystem connector permits Flink to instantly connect with Amazon S3 and browse our supply information. Beforehand in Kinesis Information Analytics for SQL Purposes, you couldn’t add new references inline. As a substitute, you outlined S3 reference information and added it to your utility configuration, which you possibly can then use as a reference in a SQL JOIN.
NOTE: In case you are not utilizing the us-east-1 area, you may obtain the csv and place the thing your individual S3 bucket. Reference the csv file as s3a://<bucket-name>/<key-name>

Constructing on the final question, the following paragraph performs a SQL JOIN on our present information and the brand new lookup supply desk we created.

Now that we have now an enriched information stream, we restream this information. In a real-world state of affairs, we have now many decisions on what to do with our information, similar to sending the information to an S3 information lake, one other Kinesis information stream for additional evaluation, or storing the information in OpenSearch Service for visualization. For simplicity, we ship the information to Kinesis Information Firehose, which streams the information into an S3 bucket appearing as our information lake.
Kinesis Information Firehose can stream information to Amazon S3, OpenSearch Service, Amazon Redshift information warehouses, and Splunk in just some clicks.
Create the Kinesis Information Firehose supply stream
To create our supply stream, full the next steps:
- On the Kinesis Information Firehose console, select Create supply stream.
- Select Direct PUT for the stream supply and Amazon S3 because the goal.

- Title your supply stream automotive-firehose.

- Underneath Vacation spot settings, create a brand new bucket or use an current bucket.
- Be aware of the S3 bucket URL.

- Select Create supply stream.
The stream takes a number of seconds to create.
- Return to the Kinesis Information Analytics console and select Streaming purposes.
- On the Studio tab, and select your Studio pocket book.

- Select the hyperlink below IAM position.

- Within the IAM window, select Add permissions and Connect insurance policies.

- Seek for and choose AmazonKinesisFullAccess and CloudWatchFullAccess, then select Connect coverage.
- You might return to your Zeppelin pocket book.
Stream information into Kinesis Information Firehose
As of Apache Flink v1.15, creating the connector to the Firehose supply stream works just like making a connector to any Kinesis information stream. Notice that there are two variations: the connector is firehose, and the stream attribute turns into delivery-stream.

After the connector is created, we are able to write to the connector like several SQL desk.

To validate that we’re getting information via the supply stream, open the Amazon S3 console and make sure you see recordsdata being created. Open the file to examine the brand new information.
In Kinesis Information Analytics for SQL Purposes, we might have created a brand new vacation spot within the SQL utility dashboard. Emigrate an current vacation spot, you add a SQL assertion to your pocket book that defines the brand new vacation spot proper within the code. You may proceed to write down to the brand new vacation spot as you’ll have with an INSERT whereas referencing the brand new desk title.
Time information
One other widespread operation you may carry out in Kinesis Information Analytics Studio notebooks is aggregation over a window of time. This kind of information can be utilized to ship to a different Kinesis information stream to establish anomalies, ship alerts, or be saved for additional processing. The subsequent paragraph incorporates a SQL question that makes use of a tumbling window and aggregates complete gasoline consumed for the automotive fleet for 30-second durations. Like our final instance, we might join to a different information stream and insert this information for additional evaluation.

Scala and PyFlink
There are occasions when a operate you’d carry out in your information stream is best written in a programming language as a substitute of SQL, for each simplicity and upkeep. Some examples embody advanced calculations that SQL features don’t assist natively, sure string manipulations, the splitting of information into a number of streams, and interacting with different AWS companies (similar to textual content translation or sentiment evaluation). Kinesis Information Analytics for Apache Flink has the power to make use of a number of Flink interpreters throughout the Zeppelin pocket book, which isn’t out there in Kinesis Information Analytics for SQL Purposes.
If in case you have been paying shut consideration to our information, you’ll see that the situation discipline is a JSON string. In Kinesis Information Analytics for SQL, we might use string features and outline a SQL operate and break aside the JSON string. It is a fragile strategy relying on the steadiness of the message information, however this could possibly be improved with a number of SQL features. The syntax for making a operate in Kinesis Information Analytics for SQL follows this sample:
CREATE FUNCTION ''<function_name>'' ( ''<parameter_list>'' )
RETURNS ''<information sort>''
LANGUAGE SQL
[ SPECIFIC ''<specific_function_name>'' | [NOT] DETERMINISTIC ]
CONTAINS SQL
[ READS SQL DATA ]
[ MODIFIES SQL DATA ]
[ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
RETURN ''<SQL-defined operate physique>''
In Kinesis Information Analytics for Apache Flink, AWS lately upgraded the Apache Flink surroundings to v1.15, which extends Apache Flink SQL’s desk SQL to add JSON features which might be just like JSON Path syntax. This permits us to question the JSON string instantly in our SQL. See the next code:
%flink.ssql(sort=replace)
SELECT JSON_STRING(location, ‘$.latitude) AS latitude,
JSON_STRING(location, ‘$.longitude) AS longitude
FROM my_tableAlternatively, and required previous to Apache Flink v1.15, we are able to use Scala or PyFlink in our pocket book to transform the sector and restream the information. Each languages present sturdy JSON string dealing with.
The next PyFlink code defines two user-defined features, which extract the latitude and longitude from the situation discipline of our message. These UDFs can then be invoked from utilizing Flink SQL. We reference the surroundings variable st_env. PyFlink creates six variables for you in your Zeppelin pocket book. Zeppelin additionally exposes a context for you because the variable z.


Errors may occur when messages include surprising information. Kinesis Information Analytics for SQL Purposes gives an in-application error stream. These errors can then be processed individually and restreamed or dropped. With PyFlink in Kinesis Information Analytics Streaming purposes, you may write advanced error-handling methods and instantly get better and proceed processing the information. When the JSON string is handed into the UDF, it might be malformed, incomplete, or empty. By catching the error within the UDF, Python will at all times return a price even when an error would have occurred.
The next pattern code reveals one other PyFlink snippet that performs a division calculation on two fields. If a division-by-zero error is encountered, it gives a default worth so the stream can proceed processing the message.
%flink.pyflink
@udf(input_types=[DataTypes.BIGINT()], result_type=DataTypes.BIGINT())
def DivideByZero(worth):
strive:
worth / 0
besides:
return -1
st_env.register_function("DivideByZero", DivideByZero)
Subsequent steps
Constructing a pipeline as we’ve executed on this submit provides us the bottom for testing further companies in AWS. I encourage you to proceed your streaming analytics studying earlier than tearing down the streams you created. Think about the next:
Clear up
To scrub up the companies created on this train, full the next steps:
- Navigate to the CloudFormation Console and delete the IoT System Simulator stack.
- On the AWS IoT Core console, select Message Routing and Guidelines, and delete the rule
automotive_route_kinesis. - Delete the Kinesis information stream
automotive-datawithin the Kinesis Information Stream console. - Take away the IAM position
automotive-rolewithin the IAM Console. - Within the AWS Glue console, delete the
automotive-notebook-gluedatabase. - Delete the Kinesis Information Analytics Studio pocket book
automotive-data-notebook. - Delete the Firehose supply stream
automotive-firehose.
Conclusion
Thanks for following together with this tutorial on Kinesis Information Analytics Studio. For those who’re at present utilizing a legacy Kinesis Information Analytics Studio SQL utility, I like to recommend you attain out to your AWS technical account supervisor or Options Architect and talk about migrating to Kinesis Information Analytics Studio. You may proceed your studying path in our Amazon Kinesis Information Streams Developer Information, and entry our code samples on GitHub.
Concerning the Writer
 Nicholas Tunney is a Companion Options Architect for Worldwide Public Sector at AWS. He works with world SI companions to develop architectures on AWS for purchasers within the authorities, nonprofit healthcare, utility, and training sectors.
Nicholas Tunney is a Companion Options Architect for Worldwide Public Sector at AWS. He works with world SI companions to develop architectures on AWS for purchasers within the authorities, nonprofit healthcare, utility, and training sectors.
[ad_2]