
[ad_1]
Visible query answering (VQA) is a machine studying process that requires a mannequin to reply a query about a picture or a set of pictures. Typical VQA approaches want a considerable amount of labeled coaching knowledge consisting of 1000’s of human-annotated question-answer pairs related to pictures. Lately, advances in large-scale pre-training have led to the event of VQA strategies that carry out properly with fewer than fifty coaching examples (few-shot) and with none human-annotated VQA coaching knowledge (zero-shot). Nevertheless, there may be nonetheless a big efficiency hole between these strategies and state-of-the-art absolutely supervised VQA strategies, similar to MaMMUT and VinVL. Particularly, few-shot strategies wrestle with spatial reasoning, counting, and multi-hop reasoning. Moreover, few-shot strategies have usually been restricted to answering questions on single pictures.
To enhance accuracy on VQA examples that contain advanced reasoning, in “Modular Visible Query Answering through Code Era,” to seem at ACL 2023, we introduce CodeVQA, a framework that solutions visible questions utilizing program synthesis. Particularly, when given a query about a picture or set of pictures, CodeVQA generates a Python program (code) with easy visible features that permit it to course of pictures, and executes this program to find out the reply. We show that within the few-shot setting, CodeVQA outperforms prior work by roughly 3% on the COVR dataset and a couple of% on the GQA dataset.
CodeVQA
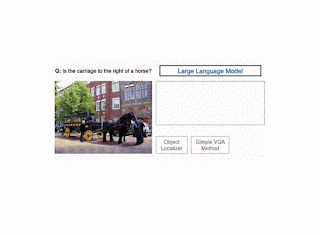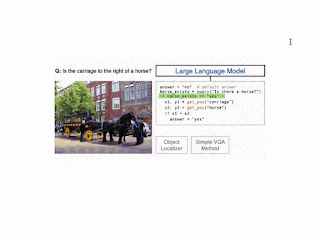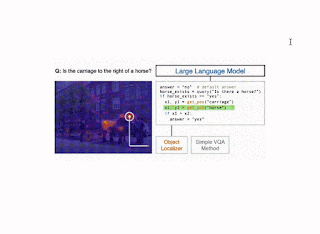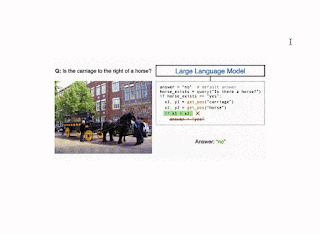
The CodeVQA method makes use of a code-writing massive language mannequin (LLM), similar to PALM, to generate Python applications (code). We information the LLM to accurately use visible features by crafting a immediate consisting of an outline of those features and fewer than fifteen “in-context” examples of visible questions paired with the related Python code for them. To pick out these examples, we compute embeddings for the enter query and of all the questions for which we have now annotated applications (a randomly chosen set of fifty). Then, we choose questions which have the very best similarity to the enter and use them as in-context examples. Given the immediate and query that we wish to reply, the LLM generates a Python program representing that query.
We instantiate the CodeVQA framework utilizing three visible features: (1) question, (2) get_pos, and (3) find_matching_image.
Question, which solutions a query a couple of single picture, is carried out utilizing the few-shot Plug-and-Play VQA (PnP-VQA) technique. PnP-VQA generates captions utilizing BLIP — an image-captioning transformer pre-trained on tens of millions of image-caption pairs — and feeds these right into a LLM that outputs the solutions to the query.Get_pos, which is an object localizer that takes an outline of an object as enter and returns its place within the picture, is carried out utilizing GradCAM. Particularly, the outline and the picture are handed by means of the BLIP joint text-image encoder, which predicts an image-text matching rating. GradCAM takes the gradient of this rating with respect to the picture options to search out the area most related to the textual content.Find_matching_image, which is utilized in multi-image questions to search out the picture that finest matches a given enter phrase, is carried out through the use of BLIP textual content and picture encoders to compute a textual content embedding for the phrase and a picture embedding for every picture. Then the dot merchandise of the textual content embedding with every picture embedding characterize the relevance of every picture to the phrase, and we choose the picture that maximizes this relevance.
The three features could be carried out utilizing fashions that require little or no annotation (e.g., textual content and image-text pairs collected from the online and a small variety of VQA examples). Moreover, the CodeVQA framework could be simply generalized past these features to others {that a} consumer may implement (e.g., object detection, picture segmentation, or information base retrieval).
 |
Illustration of the CodeVQA technique. First, a big language mannequin generates a Python program (code), which invokes visible features that characterize the query. On this instance, a easy VQA technique (question) is used to reply one a part of the query, and an object localizer (get_pos) is used to search out the positions of the objects talked about. Then this system produces a solution to the unique query by combining the outputs of those features. |
Outcomes
The CodeVQA framework accurately generates and executes Python applications not just for single-image questions, but in addition for multi-image questions. For instance, if given two pictures, every displaying two pandas, a query one may ask is, “Is it true that there are 4 pandas?” On this case, the LLM converts the counting query in regards to the pair of pictures right into a program during which an object rely is obtained for every picture (utilizing the question perform). Then the counts for each pictures are added to compute a complete rely, which is then in comparison with the quantity within the authentic query to yield a sure or no reply.
 |
We consider CodeVQA on three visible reasoning datasets: GQA (single-image), COVR (multi-image), and NLVR2 (multi-image). For GQA, we offer 12 in-context examples to every technique, and for COVR and NLVR2, we offer six in-context examples to every technique. The desk under reveals that CodeVQA improves constantly over the baseline few-shot VQA technique on all three datasets.
| Methodology | GQA | COVR | NLVR2 | ||||||||
| Few-shot PnP-VQA | 46.56 | 49.06 | 63.37 | ||||||||
| CodeVQA | 49.03 | 54.11 | 64.04 |
| Outcomes on the GQA, COVR, and NLVR2 datasets, displaying that CodeVQA constantly improves over few-shot PnP-VQA. The metric is exact-match accuracy, i.e., the proportion of examples during which the expected reply precisely matches the ground-truth reply. |
We discover that in GQA, CodeVQA’s accuracy is roughly 30% greater than the baseline on spatial reasoning questions, 4% greater on “and” questions, and three% greater on “or” questions. The third class consists of multi-hop questions similar to “Are there salt shakers or skateboards within the image?”, for which the generated program is proven under.
img = open_image("Image13.jpg")
salt_shakers_exist = question(img, "Are there any salt shakers?")
skateboards_exist = question(img, "Are there any skateboards?")
if salt_shakers_exist == "sure" or skateboards_exist == "sure":
reply = "sure"
else:
reply = "no"
In COVR, we discover that CodeVQA’s acquire over the baseline is greater when the variety of enter pictures is bigger, as proven within the desk under. This pattern signifies that breaking the issue down into single-image questions is useful.
| Variety of pictures | |||||||||||
| Methodology | 1 | 2 | 3 | 4 | 5 | ||||||
| Few-shot PnP-VQA | 91.7 | 51.5 | 48.3 | 47.0 | 46.9 | ||||||
| CodeVQA | 75.0 | 53.3 | 48.7 | 53.2 | 53.4 | ||||||
Conclusion
We current CodeVQA, a framework for few-shot visible query answering that depends on code era to carry out multi-step visible reasoning. Thrilling instructions for future work embrace increasing the set of modules used and creating an identical framework for visible duties past VQA. We notice that care ought to be taken when contemplating whether or not to deploy a system similar to CodeVQA, since vision-language fashions like those utilized in our visible features have been proven to exhibit social biases. On the similar time, in comparison with monolithic fashions, CodeVQA gives extra interpretability (by means of the Python program) and controllability (by modifying the prompts or visible features), that are helpful in manufacturing methods.
Acknowledgements
This analysis was a collaboration between UC Berkeley’s Synthetic Intelligence Analysis lab (BAIR) and Google Analysis, and was performed by Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani, Cordelia Schmid, Andy Zeng, Trevor Darrell, and Dan Klein.
[ad_2]