
[ad_1]
Organizations are grappling with the ever-expanding spectrum of information codecs in in the present day’s data-driven panorama. From Avro’s binary serialization to the environment friendly and compact construction of Protobuf, the panorama of information codecs has expanded far past the normal realms of CSV and JSON. As organizations try to derive insights from these various information streams, the problem lies in seamlessly integrating them right into a scalable resolution.
On this publish, we dive into Amazon Redshift Streaming Ingestion to ingest, course of, and analyze non-JSON information codecs. Amazon Redshift Streaming Ingestion lets you hook up with Amazon Kinesis Knowledge Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK) straight by materialized views, in actual time and with out the complexity related to staging the information in Amazon Easy Storage Service (Amazon S3) and loading it into the cluster. These materialized views not solely present a touchdown zone for streaming information, but in addition supply the flexibleness of incorporating SQL transforms and mixing into your extract, load, and remodel (ELT) pipeline for enhanced processing. For a deeper exploration on configuring and utilizing streaming ingestion in Amazon Redshift, discuss with Actual-time analytics with Amazon Redshift streaming ingestion.
JSON information in Amazon Redshift
Amazon Redshift allows storage, processing, and analytics on JSON information by the SUPER information sort, PartiQL language, materialized views, and information lake queries. The bottom assemble to entry streaming information in Amazon Redshift gives metadata from the supply stream (attributes like stream timestamp, sequence numbers, refresh timestamp, and extra) and the uncooked binary information from the stream itself. For streams that include the uncooked binary information encoded in JSON format, Amazon Redshift gives a wide range of instruments for parsing and managing the information. For extra details about the metadata of every stream format, discuss with Getting began with streaming ingestion from Amazon Kinesis Knowledge Streams and Getting began with streaming ingestion from Amazon Managed Streaming for Apache Kafka.
On the most elementary stage, Amazon Redshift permits parsing the uncooked information into distinct columns. The JSON_EXTRACT_PATH_TEXT and JSON_EXTRACT_ARRAY_ELEMENT_TEXT features allow the extraction of particular particulars from JSON objects and arrays, remodeling them into separate columns for evaluation. When the construction of the JSON paperwork and particular reporting necessities are outlined, these strategies enable for pre-computing a materialized view with the precise construction wanted for reporting, with improved compression and sorting for analytics.
Along with this strategy, the Amazon Redshift JSON features enable storing and analyzing the JSON information in its authentic state utilizing the adaptable SUPER information sort. The perform JSON_PARSE lets you extract the binary information within the stream and convert it into the SUPER information sort. With the SUPER information sort and PartiQL language, Amazon Redshift extends its capabilities for semi-structured information evaluation. It makes use of the SUPER information sort for JSON information storage, providing schema flexibility inside a column. For extra info on utilizing the SUPER information sort, discuss with Ingesting and querying semistructured information in Amazon Redshift. This dynamic functionality simplifies information ingestion, storage, transformation, and evaluation of semi-structured information, enriching insights from various sources throughout the Redshift surroundings.
Streaming information codecs
Organizations utilizing different serialization codecs should discover completely different deserialization strategies. Within the subsequent part, we dive into the optimum strategy for deserialization. On this part, we take a better have a look at the varied codecs and techniques organizations use to successfully handle their information. This understanding is vital in figuring out the information parsing strategy in Amazon Redshift.
Many organizations use a format apart from JSON for his or her streaming use instances. JSON is a self-describing serialization format, the place the schema of the information is saved alongside the precise information itself. This makes JSON versatile for functions, however this strategy can result in elevated information transmission between functions as a result of further information contained within the JSON keys and syntax. Organizations looking for to optimize their serialization and deserialization efficiency, and their community communication between functions, could choose to make use of a format like Avro, Protobuf, or perhaps a customized proprietary format to serialize software information into binary format in an optimized method. This gives the benefit of an environment friendly serialization the place solely the message values are packed right into a binary message. Nevertheless, this requires the buyer of the information to know what schema and protocol was used to serialize the information to deserialize the message. There are a number of ways in which organizations can remedy this downside, as illustrated within the following determine.

Embedded schema
In an embedded schema strategy, the information format itself incorporates the schema info alongside the precise information. Because of this when a message is serialized, it contains each the schema definition and the information values. This enables anybody receiving the message to straight interpret and perceive its construction without having to discuss with an exterior supply for schema info. Codecs like JSON, MessagePack, and YAML are examples of embedded schema codecs. While you obtain a message on this format, you’ll be able to instantly parse it and entry the information with no further steps.
Assumed schema
In an assumed schema strategy, the message serialization incorporates solely the information values, and there’s no schema info included. To interpret the information accurately, the receiving software must have prior data of the schema that was used to serialize the message. That is usually achieved by associating the schema with some identifier or context, like a stream title. When the receiving software reads a message, it makes use of this context to retrieve the corresponding schema after which decodes the binary information accordingly. This strategy requires an extra step of schema retrieval and decoding primarily based on context. This typically requires establishing a mapping in-code or in an exterior database so that buyers can dynamically retrieve the schemas primarily based on stream metadata (such because the AWS Glue Schema Registry).
One disadvantage of this strategy is in monitoring schema variations. Though shoppers can establish the related schema from the stream title, they’ll’t establish the actual model of the schema that was used. Producers want to make sure that they’re making backward-compatible modifications to schemas to make sure shoppers aren’t disrupted when utilizing a unique schema model.
Embedded schema ID
On this case, the producer continues to serialize the information in binary format (like Avro or Protobuf), just like the assumed schema strategy. Nevertheless, an extra step is concerned: the producer provides a schema ID in the beginning of the message header. When a client processes the message, it begins by extracting the schema ID from the header. With this schema ID, the buyer then fetches the corresponding schema from a registry. Utilizing the retrieved schema, the buyer can successfully parse the remainder of the message. For instance, the AWS Glue Schema Registry gives Java SDK SerDe libraries, which might natively serialize and deserialize messages in a stream utilizing embedded schema IDs. Consult with How the schema registry works for extra details about utilizing the registry.
The utilization of an exterior schema registry is widespread in streaming functions as a result of it gives an a variety of benefits to shoppers and builders. This registry incorporates all of the message schemas for the functions and associates them with a singular identifier to facilitate schema retrieval. As well as, the registry could present different functionalities like schema model change dealing with and documentation to facilitate software growth.
The embedded schema ID within the message payload can include model info, guaranteeing publishers and shoppers are at all times utilizing the identical schema model to handle information. When schema model info isn’t accessible, schema registries can assist implement producers making backward-compatible modifications to keep away from inflicting points in shoppers. This helps decouple producers and shoppers, gives schema validation at each the writer and client stage, and permits for extra flexibility in stream utilization to permit for a wide range of software necessities. Messages could be revealed with one schema per stream, or with a number of schemas inside a single stream, permitting shoppers to dynamically interpret messages as they arrive.
For a deeper dive into the advantages of a schema registry, discuss with Validate streaming information over Amazon MSK utilizing schemas in cross-account AWS Glue Schema Registry.
Schema in file
For batch processing use instances, functions could embed the schema used to serialize the information into the information file itself to facilitate information consumption. That is an extension of the embedded schema strategy however is more cost effective as a result of the information file is mostly bigger, so the schema accounts for a proportionally smaller quantity of the general information. On this case, the shoppers can course of the information straight with out further logic. Amazon Redshift helps loading Avro information that has been serialized on this method utilizing the COPY command.
Convert non-JSON information to JSON
Organizations aiming to make use of non-JSON serialization codecs have to develop an exterior methodology for parsing their messages outdoors of Amazon Redshift. We suggest utilizing an AWS Lambda-based exterior user-defined perform (UDF) for this course of. Utilizing an exterior Lambda UDF permits organizations to outline arbitrary deserialization logic to help any message format, together with embedded schema, assumed schema, and embedded schema ID approaches. Though Amazon Redshift helps defining Python UDFs natively, which can be a viable different for some use instances, we exhibit the Lambda UDF strategy on this publish to cowl extra advanced eventualities. For examples of Amazon Redshift UDFs, discuss with AWS Samples on GitHub.
The fundamental structure for this resolution is as follows.
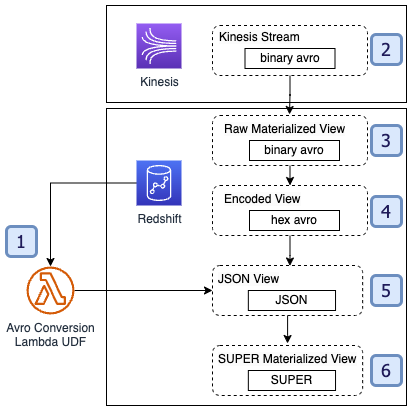
See the next code:
Let’s discover every step in additional element.
Create the Lambda UDF
The general purpose is to develop a technique that may settle for the uncooked information as enter and produce JSON-encoded information as an output. This aligns with the Amazon Redshift capability to natively course of JSON into the SUPER information sort. The specifics of the perform rely upon the serialization and streaming strategy. For instance, utilizing the assumed schema strategy with Avro format, your Lambda perform could full the next steps:
- Take within the stream title and hexadecimal-encoded information as inputs.
- Use the stream title to carry out a lookup to establish the schema for the given stream title.
- Decode the hexadecimal information into binary format.
- Use the schema to deserialize the binary information into readable format.
- Re-serialize the information into JSON format.
The f_glue_schema_registry_avro_to_json AWS samples instance illustrates the method of decoding Avro utilizing the assumed schema strategy utilizing the AWS Glue Schema Registry in a Lambda UDF to retrieve and use Avro schemas by stream title. For different approaches (reminiscent of embedded schema ID), it’s best to writer your Lambda perform to deal with deserialization as outlined by your serialization course of and schema registry implementation. In case your software depends upon an exterior schema registry or desk lookup to course of the message schema, we suggest that you just implement caching for schema lookups to assist cut back the load on the exterior techniques and cut back the common Lambda perform invocation period.
When creating the Lambda perform, be sure to accommodate the Amazon Redshift enter occasion format and guarantee compliance with the anticipated Amazon Redshift occasion output format. For particulars, discuss with Making a scalar Lambda UDF.
After you create and take a look at the Lambda perform, you’ll be able to outline it as a UDF in Amazon Redshift. For efficient integration inside Amazon Redshift, designate this Lambda perform UDF as IMMUTABLE. This classification helps incremental materialized view updates. This treats the Lambda perform as idempotent and minimizes the Lambda perform prices for the answer, as a result of a message doesn’t should be processed if it has been processed earlier than.
Configure the baseline Kinesis information stream
No matter your messaging format or strategy (embedded schema, assumed schema, and embedded schema ID), you start with establishing the exterior schema for streaming ingestion out of your messaging supply into Amazon Redshift. For extra info, discuss with Streaming ingestion.
Create the uncooked materialized view
Subsequent, you outline your uncooked materialized view. This view incorporates the uncooked message information from the streaming supply in Amazon Redshift VARBYTE format.
Convert the VARBYTE information to VARCHAR format
Exterior Lambda perform UDFs don’t help VARBYTE as an enter information sort. Subsequently, you will need to convert the uncooked VARBYTE information from the stream into VARCHAR format to go to the Lambda perform. One of the simplest ways to do that in Amazon Redshift is utilizing the TO_HEX built-in methodology. This converts the binary information into hexadecimal-encoded character information, which could be despatched to the Lambda UDF.
Invoke the Lambda perform to retrieve JSON information
After the UDF has been outlined, we are able to invoke the UDF to transform our hexadecimal-encoded information into JSON-encoded VARCHAR information.
Use the JSON_PARSE methodology to transform the JSON information to SUPER information sort
Lastly, we are able to use the Amazon Redshift native JSON parsing strategies like JSON_PARSE, JSON_EXTRACT_PATH_TEXT, and extra to parse the JSON information right into a format that we are able to use for analytics.
Issues
Think about the next when utilizing this technique:
- Value – Amazon Redshift invokes the Lambda perform in batches to enhance scalability and cut back the general variety of Lambda invocations. The price of this resolution depends upon the variety of messages in your stream, the frequency of the refresh, and the invocation time required to course of the messages in a batch from Amazon Redshift. Utilizing the IMMUTABLE UDF sort in Amazon Redshift may assist decrease prices by using the incremental refresh technique for the materialized view.
- Permissions and community entry – The AWS Identification and Entry Administration (IAM) function used for the Amazon Redshift UDF should have permissions to invoke the Lambda perform, and you will need to deploy the Lambda perform such that it has entry to invoke its exterior dependencies (for instance, chances are you’ll have to deploy it in a VPC to entry personal assets like a schema registry).
- Monitoring – Use Lambda perform logging and metrics to establish errors in deserialization, connection to the schema registry, and information processing. For particulars on monitoring the UDF Lambda perform, discuss with Embedding metrics inside logs and Monitoring and troubleshooting Lambda features.
Conclusion
On this publish, we dove into completely different information codecs and ingestion strategies for a streaming use case. By exploring methods for dealing with non-JSON information codecs, we examined the usage of Amazon Redshift streaming to seamlessly ingest, course of, and analyze these codecs in near-real time utilizing materialized views.
Moreover, we navigated by schema-per-stream, embedded schema, assumed schema, and embedded schema ID approaches, highlighting their deserves and issues. To bridge the hole between non-JSON codecs and Amazon Redshift, we explored the creation of Lambda UDFs for information parsing and conversion. This strategy presents a complete means to combine various information streams into Amazon Redshift for subsequent evaluation.
As you navigate the ever-evolving panorama of information codecs and analytics, we hope this exploration gives useful steering to derive significant insights out of your information streams. We welcome any ideas or questions within the feedback part.
In regards to the Authors
 M Mehrtens has been working in distributed techniques engineering all through their profession, working as a Software program Engineer, Architect, and Knowledge Engineer. Prior to now, M has supported and constructed techniques to course of terrabytes of streaming information at low latency, run enterprise Machine Studying pipelines, and created techniques to share information throughout groups seamlessly with various information toolsets and software program stacks. At AWS, they’re a Sr. Options Architect supporting US Federal Monetary clients.
M Mehrtens has been working in distributed techniques engineering all through their profession, working as a Software program Engineer, Architect, and Knowledge Engineer. Prior to now, M has supported and constructed techniques to course of terrabytes of streaming information at low latency, run enterprise Machine Studying pipelines, and created techniques to share information throughout groups seamlessly with various information toolsets and software program stacks. At AWS, they’re a Sr. Options Architect supporting US Federal Monetary clients.
 Sindhu Achuthan is a Sr. Options Architect with Federal Financials at AWS. She works with clients to supply architectural steering on analytics options utilizing AWS Glue, Amazon EMR, Amazon Kinesis, and different providers. Outdoors of labor, she loves DIYs, to go on lengthy trails, and yoga.
Sindhu Achuthan is a Sr. Options Architect with Federal Financials at AWS. She works with clients to supply architectural steering on analytics options utilizing AWS Glue, Amazon EMR, Amazon Kinesis, and different providers. Outdoors of labor, she loves DIYs, to go on lengthy trails, and yoga.
[ad_2]