
[ad_1]
Have you ever ever needed to run SQL queries on Amazon DynamoDB tables with out impacting your manufacturing workloads? Would not or not it’s nice to take action while not having to arrange an ETL job after which having to manually monitor that job?
On this weblog, I’ll talk about how Rockset integrates with DynamoDB and repeatedly updates a set robotically as new objects are added to a DynamoDB desk. I’ll stroll by way of steps on learn how to arrange a stay integration between Rockset and a DynamoDB desk and run millisecond-latency SQL on it.
DynamoDB Integration
Amazon DynamoDB is a key-value and doc database the place the hot button is specified on the time of desk creation. DynamoDB helps scan operations over a number of gadgets and in addition captures desk exercise utilizing DynamoDB Streams. Utilizing these options, Rockset repeatedly ingests knowledge from DynamoDB in two steps:
- The primary time a person creates a DynamoDB-sourced assortment, Rockset does a whole scan of the DynamoDB desk.
- After the scan finishes, Rockset repeatedly processes DynamoDB Streams to account for brand spanking new or modified information.
To make sure Rockset doesn’t lose any new knowledge which is recorded within the DynamoDB desk when the scan is occurring, Rockset allows strongly constant scans within the Rockset-DynamoDB connector, and in addition creates DynamoDB Streams (if not already current) and information the sequence numbers of current shards. The continual processing step (step 2 above) processes DynamoDB Streams ranging from the sequence quantity recorded earlier than the scan.
Major key values from the DynamoDB desk are used to assemble the _id subject in Rockset to uniquely determine a doc in a Rockset assortment. This ensures that updates to an current merchandise within the DynamoDB desk are utilized to the corresponding doc in Rockset.
Connecting DynamoDB to Rockset
For this instance, I’ve created a DynamoDB desk programmatically utilizing a Hacker Information knowledge set. The information set consists of knowledge about every publish and touch upon the web site. Every subject within the dataset is described right here. I’ve included a pattern of this knowledge set in our recipes repository.
The desk was created utilizing the id subject because the partition key for DynamoDB. Additionally, I needed to therapeutic massage the info set as DynamoDB does not settle for empty string values. With Rockset, as you will note within the subsequent few steps, you need not carry out such ETL operations or present schema definitions to create a set and make it instantly queryable through SQL.
Making a Rockset Assortment
I’ll use the Rockset Python Consumer to create a set backed by a DynamoDB desk. To do that in your surroundings, you have to to create an Integration (an object that represents your AWS credentials) and arrange related permissions on the DynamoDB desk, which permits Rockset to carry out sure learn operations on that desk.
from rockset import Consumer
rs=Consumer(api_key=...)
aws_integration=rs.Integration.retrieve("aws-rockset")
sources=[
rs.Source.dynamo(
table_name="rockset-demo",
integration=aws_integration)]
rockset_dynamodb_demo=rs.Assortment.create("rockset-dynamodb-demo", sources=sources)
Alternatively, DynamoDB-sourced collections will also be created from the Rockset console, as proven beneath.
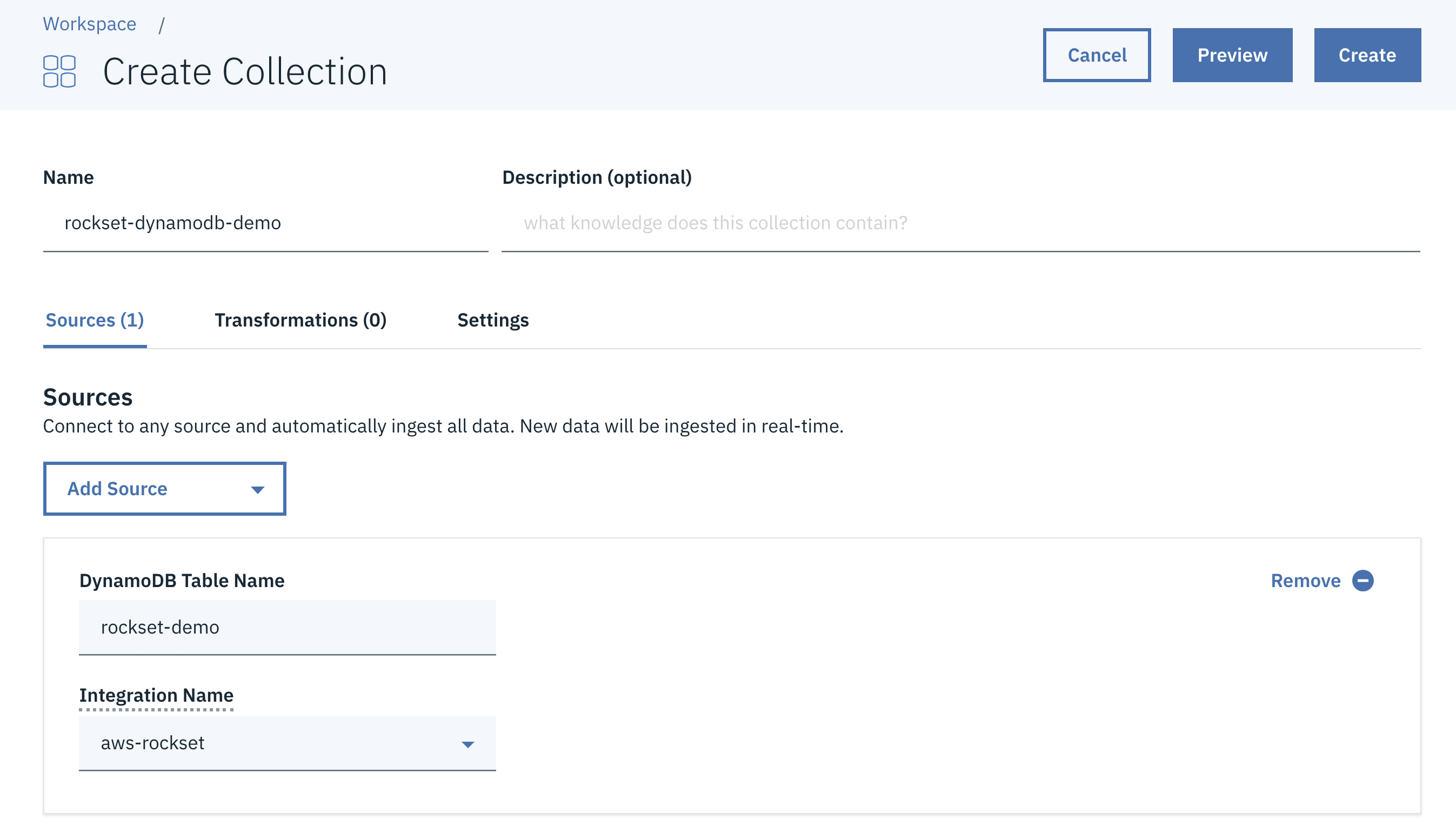
Operating SQL on DynamoDB Information
Every doc in Rockset corresponds to at least one row within the DynamoDB desk. Rockset robotically infers the schema, as proven beneath.
rockset> describe "rockset-dynamodb-demo";
+---------------------------------+---------------+----------+-----------+
| subject | occurrences | complete | kind |
|---------------------------------+---------------+----------+-----------|
| ['_event_time'] | 18926775 | 18926775 | timestamp |
| ['_id'] | 18926775 | 18926775 | string |
| ['_meta'] | 18926775 | 18926775 | object |
| ['_meta', 'dynamodb'] | 18926775 | 18926775 | object |
| ['_meta', 'dynamodb', 'table'] | 18926775 | 18926775 | string |
| ['by'] | 18926775 | 18926775 | string |
| ['dead'] | 890827 | 18926775 | bool |
| ['deleted'] | 562904 | 18926775 | bool |
| ['descendants'] | 2660205 | 18926775 | string |
| ['id'] | 18926775 | 18926775 | string |
| ['parent'] | 15716204 | 18926775 | string |
| ['score'] | 3045941 | 18926775 | string |
| ['text'] | 18926775 | 18926775 | string |
| ['time'] | 18899951 | 18926775 | string |
| ['title'] | 18926775 | 18926775 | string |
| ['type'] | 18926775 | 18926775 | string |
| ['url'] | 18926775 | 18926775 | string |
+---------------------------------+---------------+----------+-----------+
Now we’re able to run quick SQL on knowledge from our DynamoDB desk. Let’s write a couple of queries to get some insights from this knowledge set.
Since we’re clearly within the matter of knowledge, let’s have a look at how continuously individuals have mentioned or shared about “knowledge” on Hacker Information over time. On this question, I’m tokenizing the title, extracting the yr from the the time subject, and returning the variety of occurrences of “knowledge” within the tokens, grouped by yr.
with title_tokens as (
choose rows.tokens as token, subq.yr as yr
from (
choose tokenize(title) as title_tokens,
EXTRACT(YEAR from DATETIME(TIMESTAMP_SECONDS(time::int))) as yr
from "rockset-dynamodb-demo"
) subq, unnest(title_tokens as tokens) as rows
)
choose yr, rely(token) as tales
from title_tokens
the place decrease(token) = 'knowledge'
group by yr order by yr
+-----------+------+
| tales | yr |
|-----------+------|
| 176 | 2007 |
| 744 | 2008 |
| 1371 | 2009 |
| 2192 | 2010 |
| 3624 | 2011 |
| 4621 | 2012 |
| 6164 | 2013 |
| 6020 | 2014 |
| 7224 | 2015 |
| 7878 | 2016 |
| 8159 | 2017 |
| 8438 | 2018 |
+-----------+------+
Utilizing Apache Superset integration with Rockset, I plotted a graph with the outcomes. (It’s attainable to make use of knowledge visualization instruments like Tableau, Redash, and Grafana as effectively.)
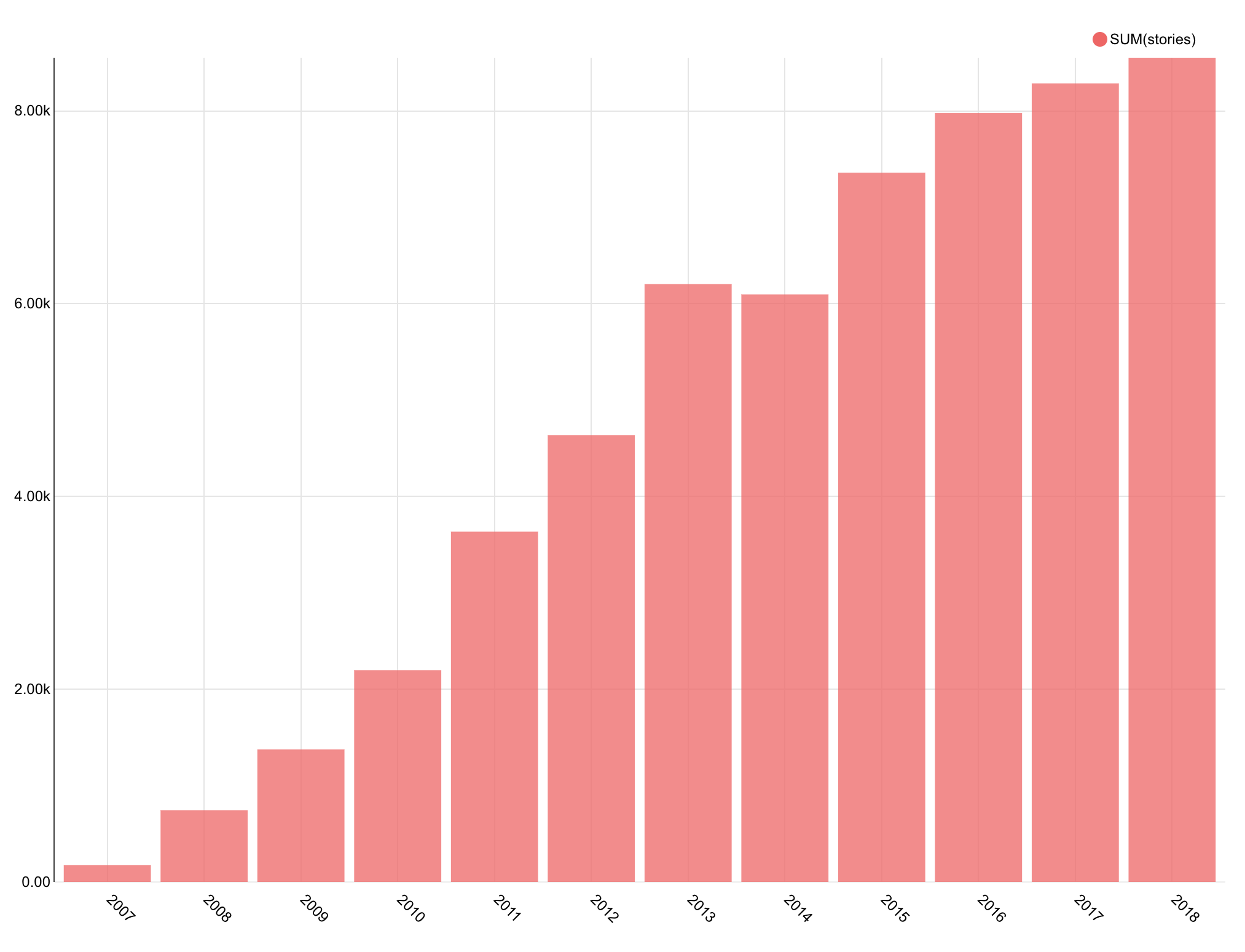
The variety of tales regarding knowledge has clearly been rising over time.
Subsequent, let’s mine the Hacker Information knowledge set for observations on one of the talked-about applied sciences of the previous two years, blockchain. Let’s first verify how person engagement round blockchain and cryptocurrencies has been trending.
with title_tokens as (
choose rows.tokens as token, subq.yr as yr
from (
choose tokenize(title) as title_tokens,
EXTRACT(YEAR from DATETIME(TIMESTAMP_SECONDS(time::int))) as yr
from "rockset-dynamodb-demo"
) subq, unnest(title_tokens as tokens) as rows
)
choose yr, rely(token) as rely
from title_tokens
the place decrease(token) = 'crypto' or decrease(token) = 'blockchain'
group by yr order by yr
+---------------+--------+
| rely | yr |
|---------------+--------|
| 6 | 2008 |
| 26 | 2009 |
| 35 | 2010 |
| 43 | 2011 |
| 75 | 2012 |
| 278 | 2013 |
| 431 | 2014 |
| 750 | 2015 |
| 1383 | 2016 |
| 2928 | 2017 |
| 5550 | 2018 |
+-----------+------------+
As you’ll be able to see, curiosity in blockchain went up immensely in 2017 and 2018. The outcomes are additionally aligned with this examine, which estimated that the variety of crypto customers doubled in 2018.
Additionally, together with blockchain, tons of of cryptocurrencies emerged. Let’s discover the preferred cash in our knowledge set.
with crypto_text_tokens as (
choose rows.tokens as token
from (
choose tokenize(textual content) as text_tokens
from (
choose textual content as textual content
from "rockset-dynamodb-demo"
the place textual content like '%crypto%' or textual content like '%blockchain%'
) subq
) subq, unnest(text_tokens as tokens) as rows
)
choose token, rely(token) as rely
from crypto_text_tokens
the place token like '_percentcoin'
group by token
order by rely desc
restrict 10;
+---------+------------+
| rely | token |
|---------+------------|
| 29197 | bitcoin |
| 512 | litecoin |
| 454 | dogecoin |
| 433 | cryptocoin |
| 362 | namecoin |
| 239 | altcoin |
| 219 | filecoin |
| 122 | zerocoin |
| 81 | stablecoin |
| 69 | peercoin |
+---------+------------+
Bitcoin, as one would have guessed, appears to be the preferred cryptocurrency in our Hacker Information knowledge.
Abstract
On this total course of, I merely created a Rockset assortment with a DynamoDB supply, with none knowledge transformation and schema modeling, and instantly ran SQL queries over it. Utilizing Rockset, you can also be a part of knowledge throughout totally different DynamoDB tables or different sources to energy your stay purposes.
Different DynamoDB sources:
[ad_2]