
[ad_1]
For data-driven enterprises, knowledge analysts play a vital function in extracting insights from knowledge and presenting it in a significant means. Nonetheless, many analysts may not have the familiarity with knowledge orchestration required to automate their workloads for manufacturing. Whereas a handful of ad-hoc queries can shortly flip round the appropriate knowledge for a last-minute report, knowledge groups should make sure that numerous processing, transformation, and validation duties are executed reliably and in the appropriate sequence. With out the right orchestration in place, knowledge groups lose the power to observe pipelines, troubleshoot failures, and handle dependencies. Consequently, units of ad-hoc queries that originally introduced quick-hitting worth to the enterprise find yourself turning into long-term complications for the analysts who constructed them.
Pipeline automation and orchestration turns into significantly essential as the dimensions of information grows and the complexity of pipelines will increase. Historically, these tasks have fallen on knowledge engineers, however as knowledge analysts start to develop extra property within the lakehouse, orchestration and automation turns into a key piece to the puzzle.
For knowledge analysts, the method of querying and visualizing knowledge needs to be seamless, and that is the place the facility of contemporary instruments like Databricks Workflows comes into play. On this weblog publish, we’ll discover how knowledge analysts can leverage Databricks Workflows to automate their knowledge processes, enabling them to concentrate on what they do finest – deriving worth from knowledge.
The Knowledge Analyst’s World
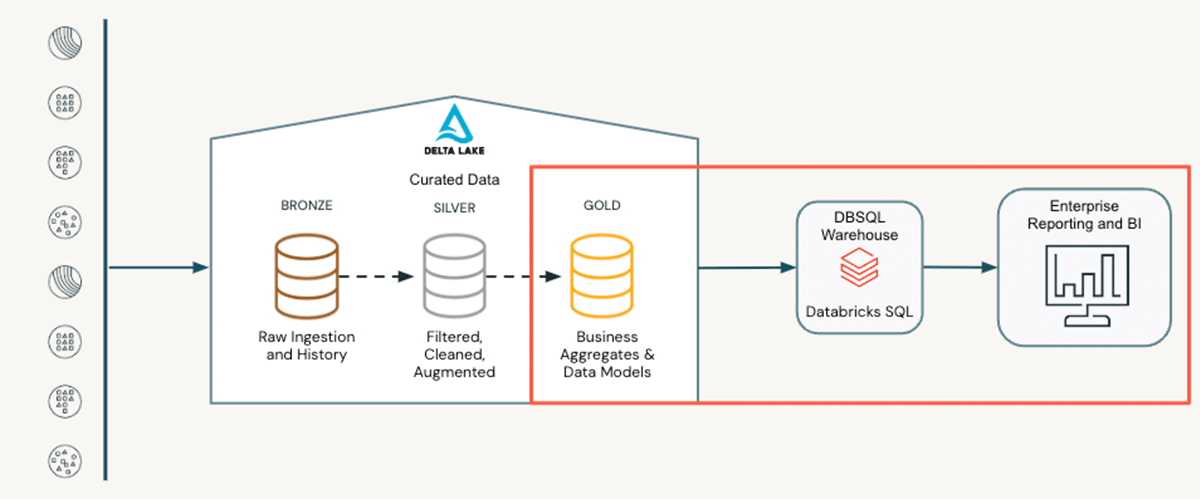
Knowledge analysts play a significant function within the last phases of the information life cycle. Positioned on the “final mile”, they depend on refined knowledge from upstream pipelines. This might be a desk ready by an information engineer or the output predictions of machine studying fashions constructed by knowledge scientists. This refined knowledge, also known as the silver layer in a medallion structure, serves as the inspiration for his or her work. Knowledge analysts are chargeable for aggregating, enriching, and shaping this knowledge to reply particular questions for his or her enterprise, akin to:
- “What number of orders have been positioned for every SKU final week?”
- “What was month-to-month income for every retailer final fiscal 12 months?”
- “Who’re our ten most lively customers?”
These aggregations and enrichments construct out the gold layer of the medallion structure. This gold layer permits simple consumption and reporting for downstream customers, usually in a visualization layer. This could take the type of dashboards inside Databricks or be seamlessly generated utilizing exterior instruments like Tableau or Energy BI through Associate Join. Whatever the tech stack, knowledge analysts rework uncooked knowledge into helpful insights, enabling knowledgeable decision-making by means of structured evaluation and visualization strategies.
The Knowledge Analyst’s Toolkit on Databricks
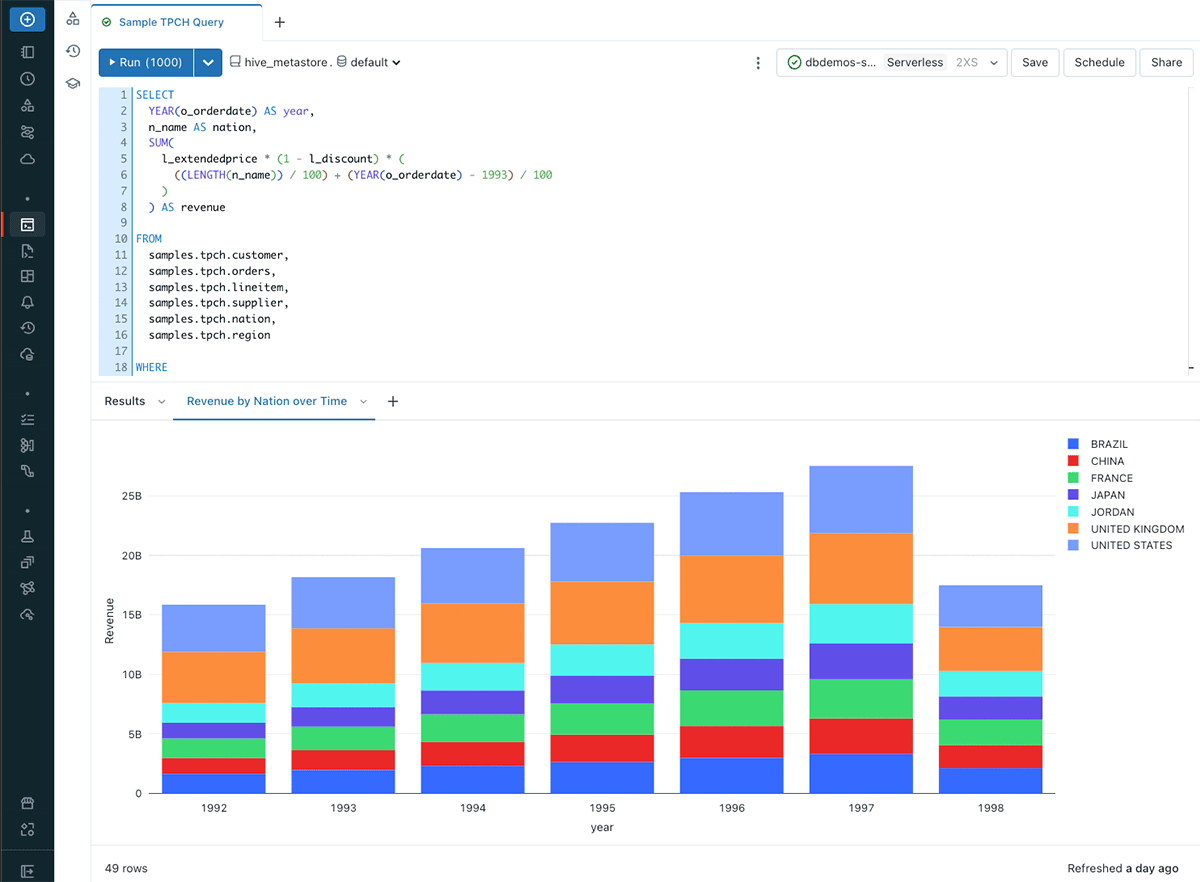
In Databricks, knowledge analysts have a sturdy toolkit at their fingertips to remodel knowledge successfully on the lakehouse. Centered across the Databricks SQL Editor, analysts have a well-known surroundings for composing ANSI SQL queries, accessing knowledge, and exploring desk schemas. These queries function constructing blocks for numerous SQL property, together with visualizations that supply in-line knowledge insights. Dashboards consolidate a number of visualizations, making a user-friendly interface for complete reporting and knowledge exploration for finish customers. Moreover, Alerts hold analysts knowledgeable about crucial dataset adjustments in real-time. Serverless SQL Warehouses are underpinning all these options, which may scale to deal with various knowledge volumes and question calls for. By default, this compute makes use of Photon, the high-performance Databricks-native vectorized question engine, and is optimized for high-concurrency SQL workloads. Lastly, Unity Catalog permits customers to simply govern structured and unstructured knowledge, machine studying fashions, notebooks, dashboards and information within the lakehouse. This cohesive toolkit empowers knowledge analysts to remodel uncooked knowledge into enriched insights seamlessly inside the Databricks surroundings.
Orchestrating the Knowledge Analyst’s Toolkit with Workflows
For these new to Databricks, Workflows orchestrates knowledge processing, machine studying, and analytics pipelines within the Databricks Lakehouse Platform. Workflows is a totally managed orchestration service built-in with the Databricks platform, with excessive reliability and superior observability capabilities. This enables all customers, no matter persona or background, to simply orchestrate their workloads in manufacturing environments.
Authoring Your SQL Duties
Constructing your first Workflow as an information analyst is very simple. Workflows now seamlessly integrates the core instruments utilized by knowledge analysts—Queries, Alerts, and Dashboards—inside its framework, enhancing its capabilities by means of the SQL activity kind. This enables knowledge analysts to construct and work with the instruments they’re already accustomed to after which simply convey them right into a Workflow as a Activity through the UI.
As knowledge analysts start to chain extra SQL duties collectively, they may start to simply outline dependencies between and acquire the power to schedule and automate SQL-based duties inside Databricks Workflows. Within the beneath instance workflow, we see this in motion:
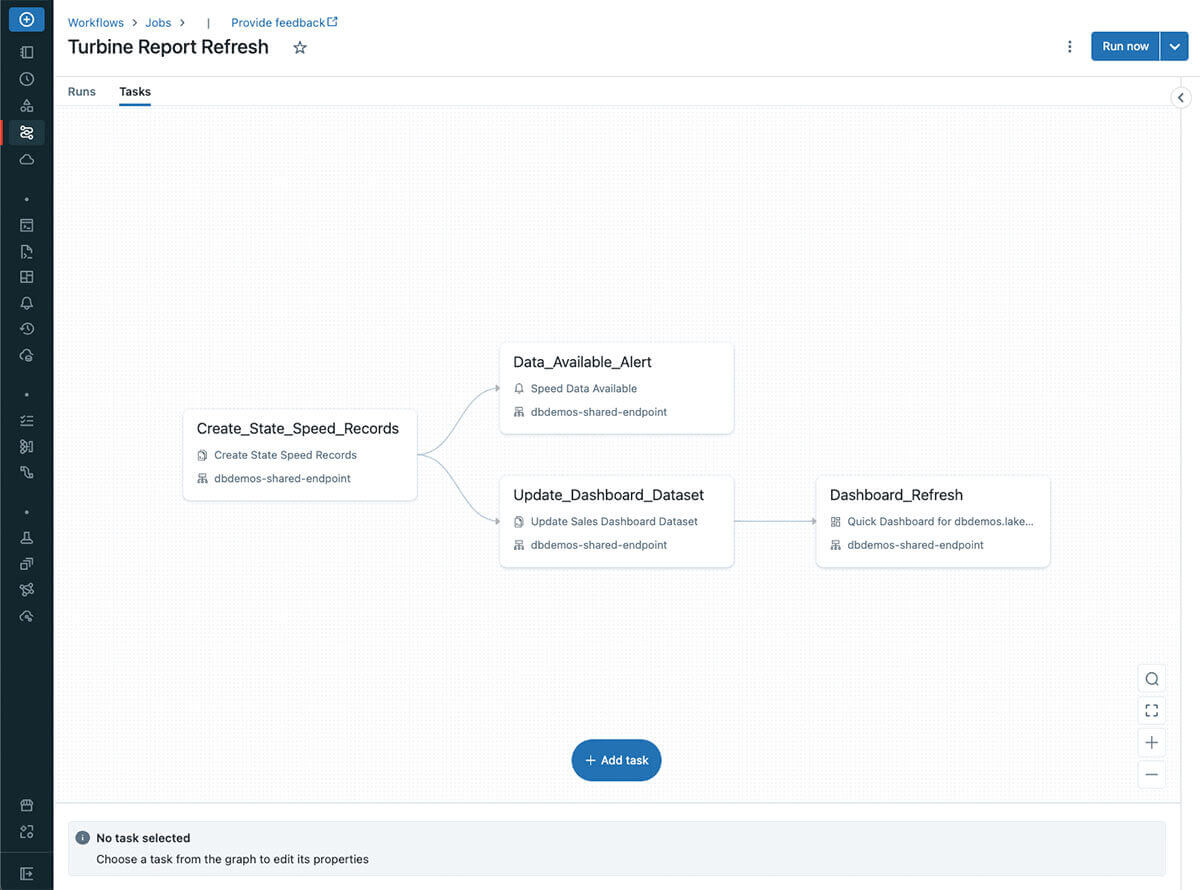
Think about that we have now acquired upstream knowledge from our knowledge engineering staff that permits us to start our dashboard refresh course of. We will outline SQL-centric duties like those beneath to automate our pipeline:
- Create_State_Speed_Records: First, we outline our refreshed knowledge in our gold layer with the Question activity. This inserts knowledge right into a gold desk after which optimizes it for higher efficiency.
- Data_Avaialable_Alert: As soon as this knowledge is inserted, think about we need to notify different knowledge analysts who eat this desk that new information have been added. We will do that by creating an Alert which can set off when we have now new information added. This can ship an alert to our stakeholder group. You may think about utilizing an alert similarly for knowledge high quality checks to warn customers of stale knowledge, null information, or different comparable conditions. For extra data on creating your first Alert, try this hyperlink.
- Update_Dashboard_Dataset: It’s price mentioning that duties might be outlined in parallel if wanted. In our instance, whereas our alert is triggering we will additionally start refreshing our tailor-made dataset view that feeds our dashboard in a parallel Question.
- Dashboard_Refresh: Lastly, we create a Dashboard activity kind. As soon as our dataset is able to go, it will replace all beforehand outlined visualizations with the latest knowledge and notify all subscribers upon profitable completion. Customers may even move particular parameters to the dashboard whereas defining the duty, which might help generate a default view of the dashboard relying on the tip person’s wants.
It’s price noting that this instance Workflow makes use of queries straight written within the Databricks SQL Editor. An identical sample might be achieved with SQL code coming from a repository utilizing the File activity kind. With this activity kind, customers can execute .sql information saved in a Git repository as a part of an automatic Workflow. Every time the pipeline is executed, the most recent model from a particular department can be retrieved and executed. To be taught extra in regards to the File activity kind, try this announcement weblog.
Though this instance is primary, you’ll be able to start to see the probabilities of how an information analyst can outline dependencies throughout SQL activity sorts to construct a complete analytics pipeline.
Monitoring Your Manufacturing Pipelines
Whereas authoring is complete inside Workflows, it’s only one a part of the image. Equally essential is the power to simply monitor and debug your pipelines as soon as they’re constructed and in manufacturing.
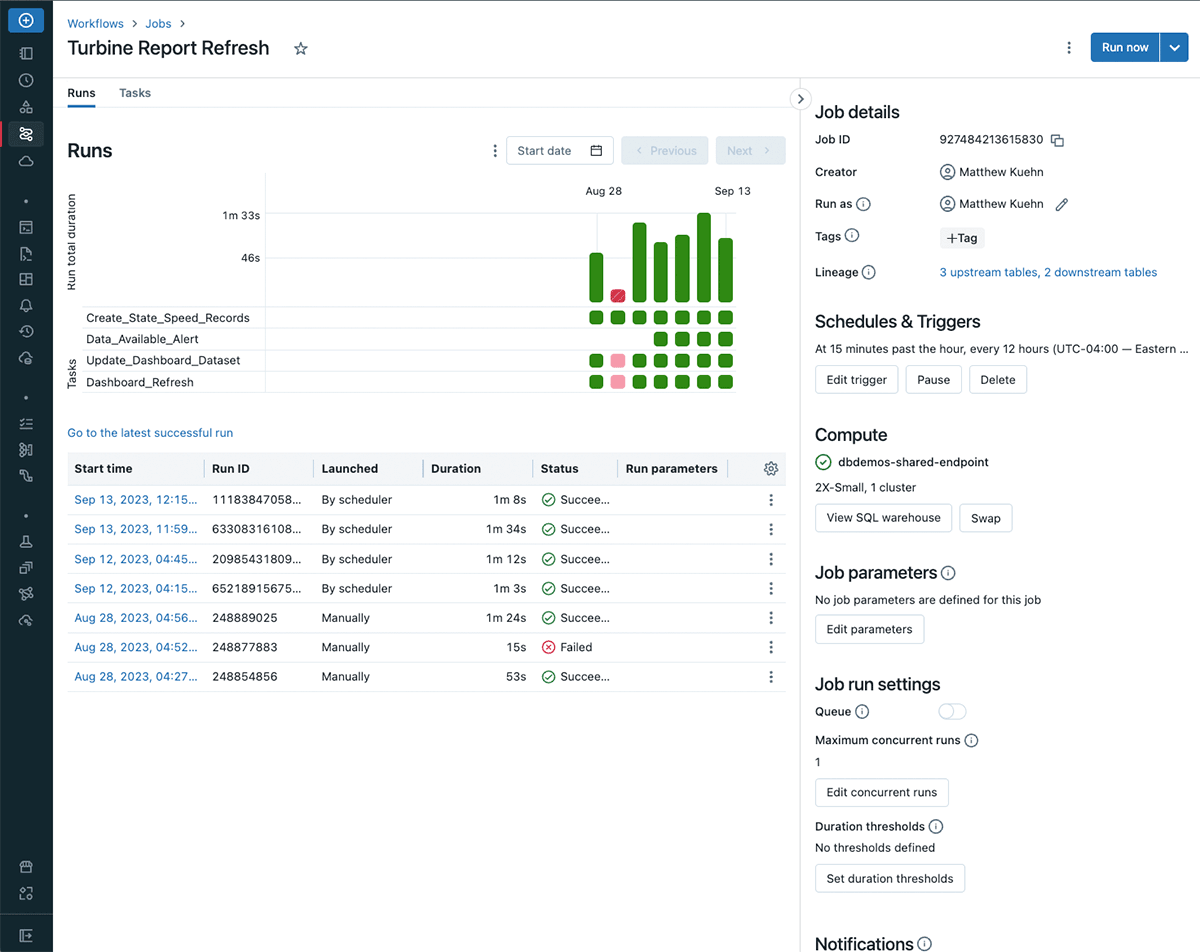
Workflows permits customers to observe particular person job runs, providing insights into activity outcomes and general execution occasions. This visibility helps analysts perceive question efficiency, establish bottlenecks, and handle points effectively. By promptly recognizing duties that require consideration, analysts can guarantee seamless knowledge processing and faster challenge decision.
In terms of executing a pipeline on the proper time, Workflows permits customers to schedule jobs for execution at particular intervals or set off them when sure information arrive. Within the above picture, we have been first manually triggering this pipeline to check and debug our duties. As soon as we received this to a gentle state, we started triggering this each 12 hours to accommodate for knowledge refresh wants throughout time zones. This flexibility accommodates various knowledge eventualities, guaranteeing well timed pipeline execution. Whether or not it is routine processing or responding to new knowledge batches, analysts can tailor job execution to match operational necessities.
Late arriving knowledge can convey a flurry of questions to a knowledge analyst from finish customers. Workflows permits analysts and customers alike to remain knowledgeable on knowledge freshness by organising notifications for job outcomes akin to profitable execution, failure, or perhaps a long-running job. These notifications guarantee well timed consciousness of adjustments in knowledge processing. By proactively evaluating a pipeline’s standing, analysts can take proactive measures based mostly on real-time data.
As with all pipelines, failures will inevitably occur. Workflows helps handle this by permitting analysts to configure job duties for computerized retries. By automating retries, analysts can concentrate on producing insights somewhat than troubleshooting intermittent technical points.
Conclusion
Within the evolving panorama of information evaluation instruments, Databricks Workflows bridges the hole between knowledge analysts and the complexities of information orchestration. By automating duties, guaranteeing knowledge high quality, and offering a user-friendly interface, Workflows empower analysts to concentrate on what they excel at – extracting significant insights from knowledge. Because the idea of the lakehouse continues to unfold, Workflows stand as a pivotal element, promising a unified and environment friendly knowledge ecosystem for all personas.
Get Began
[ad_2]