
[ad_1]
Introduction
This text will have a look at a pc imaginative and prescient strategy of Picture Semantic Segmentation. Though this sounds advanced, we’re going to interrupt it down step-by-step, and we’ll introduce an thrilling idea of picture semantic segmentation, which is an implementation utilizing dense prediction transformers or DPTs for brief from the Hugging Face collections. Utilizing DPTs introduces a brand new section of laptop imaginative and prescient with uncommon capabilities.
Studying Targets
- Comparability of DPTs vs. Standard understanding of distant connections.
- Implementing semantic segmentation through depth prediction with DPT in Python.
- Discover DPT designs, understanding their distinctive traits.
This text was revealed as part of the Information Science Blogathon.
What’s Picture Semantic Segmentation?
Think about having a picture and desirous to label each pixel in it in line with what it represents. That’s the thought behind picture semantic segmentation. It may very well be utilized in laptop imaginative and prescient, distinguishing a automotive from a tree or separating elements of a picture; that is all about neatly labeling pixels. Nevertheless, the true problem lies in making sense of the context and relationships between objects. Allow us to evaluate this with the, enable me to say, the previous strategy to dealing with pictures.
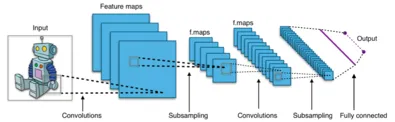
Convolutional Neural Networks (CNNs)
The primary breakthrough was to make use of Convolutional Neural Networks to sort out duties involving pictures. Nevertheless, CNNs have limits, particularly in capturing long-range connections in pictures. Think about for those who’re attempting to grasp how completely different components in a picture work together with one another throughout lengthy distances — that’s the place conventional CNNs battle. That is the place we have fun DPT. These fashions, rooted within the highly effective transformer structure, exhibit capabilities in capturing associations. We are going to see DPTs subsequent.
What are Dense Prediction Transformers (DPTs)?
To grasp this idea, think about combining the ability of Transformers which we used to know in NLP duties with picture evaluation. That’s the idea behind Dense Prediction Transformers. They’re like tremendous detectives of the picture world. They’ve the flexibility to not solely label pixels in pictures however predict the depth of every pixel — which form of gives info on how far-off every object is from the picture. We are going to see this under.
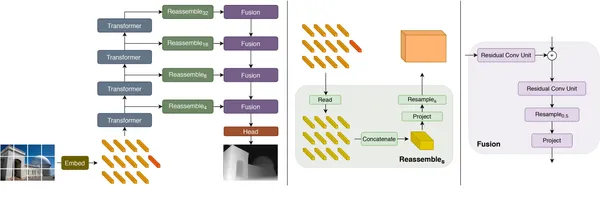
DPT Structure’s Toolbox
DPTs come in several varieties, every with its “encoder” and “decoder” layers. Let’s have a look at two standard ones right here:
- DPT-Swin-Transformer: Consider a mega transformer with 10 encoder layers and 5 decoder layers. It’s nice at understanding relationships between components at ranges within the picture.
- DPT-ResNet: This one’s like a intelligent detective with 18 encoder layers and 5 decoder layers. It excels at recognizing connections between faraway objects whereas holding the picture’s spatial construction intact.
Key Options
Right here’s a better have a look at how DPTs work utilizing some key options:
- Hierarchical Function Extraction: Identical to conventional Convolutional Neural Networks (CNNs), DPTs extracts options from the enter picture. Nevertheless, they observe a hierarchical strategy the place the picture is split into completely different ranges of element. It’s this hierarchy that helps to seize each native and world context, permitting the mannequin to grasp relationships between objects at completely different scales.
- Self-Consideration Mechanism: That is the spine of DPTs impressed by the unique Transformer structure enabling the mannequin to seize long-range dependencies throughout the picture and study advanced relationships between pixels. Every pixel considers the data from all different pixels, giving the mannequin a holistic understanding of the picture.
Python Demonstration of Picture Semantic Segmentation utilizing DPTs
We are going to see an implementation of DPTs under. First, let’s arrange our surroundings by putting in libraries not preinstalled on Colab. You’ll find the code for this right here or at https://github.com/inuwamobarak/semantic-segmentation
First, we set up and arrange our surroundings.
!pip set up -q git+https://github.com/huggingface/transformers.gitSubsequent, we put together the mannequin we intend to coach on.
## Outline mannequin
# Import the DPTForSemanticSegmentation from the Transformers library
from transformers import DPTForSemanticSegmentation
# Create the DPTForSemanticSegmentation mannequin and cargo the pre-trained weights
# The "Intel/dpt-large-ade" mannequin is a large-scale mannequin skilled on the ADE20K dataset
mannequin = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade")Now we load and put together a picture we want to use for the segmentation.
# Import the Picture class from the PIL (Python Imaging Library) module
from PIL import Picture
import requests
# URL of the picture to be downloaded
url="https://img.freepik.com/free-photo/happy-lady-hugging-her-white-friendly-dog-while-walking-park_171337-19281.jpg?w=740&t=st=1689214254~exp=1689214854~hmac=a8de6eb251268aec16ed61da3f0ffb02a6137935a571a4a0eabfc959536b03dd"
# The `stream=True` parameter ensures that the response shouldn't be instantly downloaded, however is stored in reminiscence
response = requests.get(url, stream=True)
# Create the Picture class
picture = Picture.open(response.uncooked)
# Show picture
picture
from torchvision.transforms import Compose, Resize, ToTensor, Normalize
# Set the specified top and width for the enter picture
net_h = net_w = 480
# Outline a collection of picture transformations
rework = Compose([
# Resize the image
Resize((net_h, net_w)),
# Convert the image to a PyTorch tensor
ToTensor(),
# Normalize the image
Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
])The following step from right here might be to use some transformation to the picture.
# Rework enter picture
pixel_values = rework(picture)
pixel_values = pixel_values.unsqueeze(0)Subsequent is we ahead move.
import torch
# Disable gradient computation
with torch.no_grad():
# Carry out a ahead move by way of the mannequin
outputs = mannequin(pixel_values)
# Receive the logits (uncooked predictions) from the output
logits = outputs.logitsNow, we print out the picture as bunch of array. We are going to convert this subsequent to the picture with the semantic prediction.
import torch
# Interpolate the logits to the unique picture measurement
prediction = torch.nn.practical.interpolate(
logits,
measurement=picture.measurement[::-1], # Reverse the scale of the unique picture (width, top)
mode="bicubic",
align_corners=False
)
# Convert logits to class predictions
prediction = torch.argmax(prediction, dim=1) + 1
# Squeeze the prediction tensor to take away dimensions
prediction = prediction.squeeze()
# Transfer the prediction tensor to the CPU and convert it to a numpy array
prediction = prediction.cpu().numpy()We supply out the semantic prediction now.
from PIL import Picture
# Convert the prediction array to a picture
predicted_seg = Picture.fromarray(prediction.squeeze().astype('uint8'))
# Apply the colour map to the anticipated segmentation picture
predicted_seg.putpalette(adepallete)
# Mix the unique picture and the anticipated segmentation picture
out = Picture.mix(picture, predicted_seg.convert("RGB"), alpha=0.5)
There we have now our picture with the semantics being predicted. You may experiment with your personal pictures. Now allow us to see some analysis that has been utilized to DPTs.
Efficiency Evaluations on DPTs
DPTs have been examined in quite a lot of analysis work and papers and have been used on completely different picture playgrounds like Cityscapes, PASCAL VOC, and ADE20K datasets and so they carry out properly than conventional CNN fashions. Hyperlinks to this dataset and analysis paper might be within the hyperlink part under.
On Cityscapes, DPT-Swin-Transformer scored a 79.1% on a imply intersection over union (mIoU) metric. On PASCAL VOC, DPT-ResNet achieved a mIoU of 82.8% a brand new benchmark. These scores are a testomony to DPTs’ capacity to grasp pictures in depth.
The Way forward for DPTs and What Lies Forward
DPTs are a brand new period in picture understanding. Analysis in DPTs is altering how we see and work together with pictures and convey new prospects. In a nutshell, Picture Semantic Segmentation with DPTs is a breakthrough that’s altering the way in which we decode pictures, and will certainly do extra sooner or later. From pixel labels to understanding depth, DPTs are what’s attainable on the earth of laptop imaginative and prescient. Allow us to take a deeper look.
Correct Depth Estimation
One of the vital important contributions of DPTs is predicting depth info from pictures. This development has purposes resembling 3D scene reconstruction, augmented actuality, and object manipulation. It will present a vital understanding of the spatial association of objects inside a scene.
Simultaneous Semantic Segmentation and Depth Prediction
DPTs can present each semantic segmentation and depth prediction in a unified framework. This enables a holistic understanding of pictures, enabling purposes for each semantic info and depth data. For example, in autonomous driving, this mixture is important for secure navigation.
Lowering Information Assortment Efforts
DPTs have the potential to alleviate the necessity for intensive handbook labelling of depth information. Coaching pictures with accompanying depth maps can study to foretell depth with out requiring pixel-wise depth annotations. This considerably reduces the fee and energy related to information assortment.
Scene Understanding
They permit machines to grasp their setting in three dimensions which is essential for robots to navigate and work together successfully. In industries resembling manufacturing and logistics, DPTs can facilitate automation by enabling robots to govern objects with a deeper understanding of spatial relationships.
Dense Prediction Transformers are reshaping the sector of laptop imaginative and prescient by offering correct depth info alongside a semantic understanding of pictures. Nevertheless, addressing challenges associated to fine-grained depth estimation, generalisation, uncertainty estimation, bias mitigation, and real-time optimization might be important to totally realise the transformative impression of DPTs sooner or later.
Conclusion
Picture Semantic Segmentation utilizing Dense Prediction Transformers is a journey that blends pixel labelling with spatial perception. The wedding of DPTs with picture semantic segmentation opens an thrilling avenue in laptop imaginative and prescient analysis. This text has sought to unravel the underlying intricacies of DPTs, from their structure to their efficiency prowess and promising potential to reshape the way forward for semantic segmentation in laptop imaginative and prescient.
Key Takeaways
- DPTs transcend pixels to grasp the spatial context and predict depths.
- DPTs outperform conventional picture recognition capturing distance and 3D insights.
- DPTs redefine perceiving pictures, enabling a deeper understanding of objects and relationships.
Steadily Requested Questions
A1: Whereas DPTs are primarily designed for picture evaluation, their underlying rules can encourage variations for different types of information. The thought of capturing context and relationships by way of transformers has potential purposes in domains.
A2: DPTs maintain the potential in augmented actuality through extra correct object ordering and interplay in digital environments.
A3: Conventional picture recognition strategies, like CNNs, concentrate on labelling objects in pictures with out absolutely greedy their context or spatial format however DPTs fashions take this additional by each figuring out objects and predicting their depths.
A4: The purposes are intensive. They will improve autonomous driving by serving to automobiles perceive and navigate advanced environments. They will progress medical imaging by way of correct and detailed evaluation. Past that, DPTs have the potential to enhance object recognition in robotics, enhance scene understanding in pictures, and even assist in augmented actuality experiences.
A5: Sure, there are various kinds of DPT architectures. Two distinguished examples embrace the DPT-Swin-Transformer and the DPT-ResNet the place the DPT-Swin-Transformer has a hierarchical consideration mechanism that permits it to grasp relationships between picture components at completely different ranges. And the DPT-ResNet incorporates residual consideration mechanisms to seize long-range dependencies whereas preserving the spatial construction of the picture.
Hyperlinks:
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Writer’s discretion.
Associated
[ad_2]