")
[ad_1]
Amazon Redshift is a quick, absolutely managed petabyte-scale cloud information warehouse that makes it easy and cost-effective to investigate all of your information utilizing customary SQL and your present enterprise intelligence (BI) instruments. Tens of 1000’s of consumers at this time use Amazon Redshift to investigate exabytes of knowledge and run analytical queries, making it essentially the most broadly used cloud information warehouse. Amazon Redshift is on the market in each serverless and provisioned configurations.
Amazon Redshift lets you immediately entry information saved in Amazon Easy Storage Service (Amazon S3) utilizing SQL queries and be part of information throughout your information warehouse and information lake. With Amazon Redshift, you’ll be able to question the info in your S3 information lake utilizing a central AWS Glue metastore out of your Redshift information warehouse.
Amazon Redshift helps querying all kinds of knowledge codecs, comparable to CSV, JSON, Parquet, and ORC, and desk codecs like Apache Hudi and Delta. Amazon Redshift additionally helps querying nested information with complicated information sorts comparable to struct, array, and map.
With this functionality, Amazon Redshift extends your petabyte-scale information warehouse to an exabyte-scale information lake on Amazon S3 in an economical method.
Apache Iceberg is the newest desk format that’s supported now in preview by Amazon Redshift. On this submit, we present you question Iceberg tables utilizing Amazon Redshift, and discover Iceberg assist and choices.
Answer overview
Apache Iceberg is an open desk format for very giant petabyte-scale analytic datasets. Iceberg manages giant collections of recordsdata as tables, and it helps trendy analytical information lake operations comparable to record-level insert, replace, delete, and time journey queries. The Iceberg specification permits seamless desk evolution comparable to schema and partition evolution, and its design is optimized for utilization on Amazon S3.
Iceberg shops the metadata pointer for all of the metadata recordsdata. When a SELECT question is studying an Iceberg desk, the question engine first goes to the Iceberg catalog, then retrieves the entry of the placement of the newest metadata file, as proven within the following diagram.
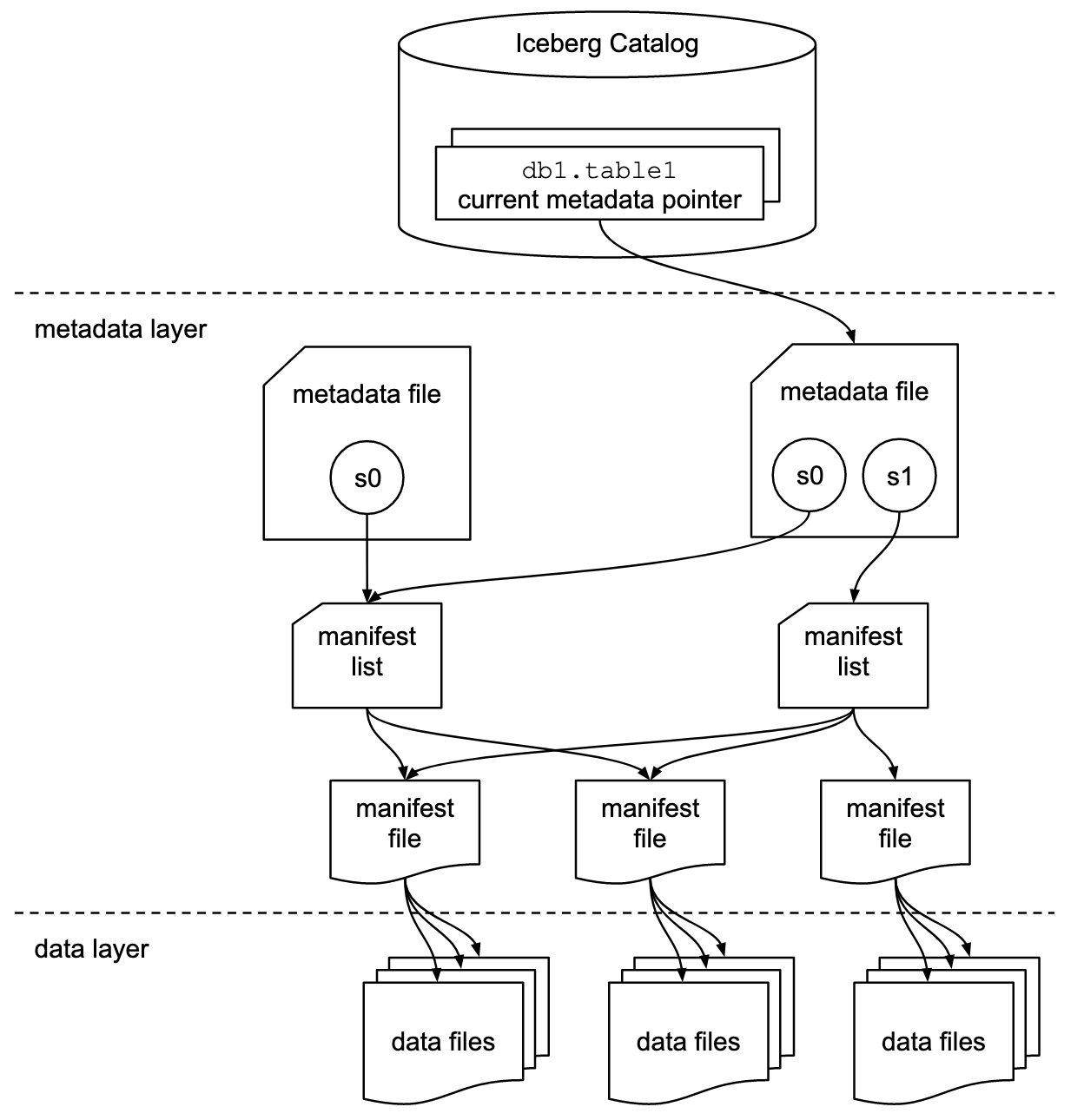
Amazon Redshift now supplies assist for Apache Iceberg tables, which permits information lake prospects to run read-only analytics queries in a transactionally constant manner. This lets you simply handle and keep your tables on transactional information lakes.
Amazon Redshift helps Apache Iceberg’s native schema and partition evolution capabilities utilizing the AWS Glue Information Catalog, eliminating the necessity to alter desk definitions so as to add new partitions or to maneuver and course of giant quantities of knowledge to vary the schema of an present information lake desk. Amazon Redshift makes use of the column statistics saved within the Apache Iceberg desk metadata to optimize its question plans and scale back the file scans required to run queries.
On this submit, we use the Yellow taxi public dataset from NYC Taxi & Limousine Fee as our supply information. The dataset accommodates information recordsdata in Apache Parquet format on Amazon S3. We use Amazon Athena to transform this Parquet dataset after which use Amazon Redshift Spectrum to question and be part of with a Redshift native desk, carry out row-level deletes and updates and partition evolution, all coordinated by way of the AWS Glue Information Catalog in an S3 information lake.
Conditions
You must have the next stipulations:
Convert Parquet information to an Iceberg desk
For this submit, you want the Yellow taxi public dataset from the NYC Taxi & Limousine Fee accessible in Iceberg format. You’ll be able to obtain the recordsdata after which use Athena to transform the Parquet dataset into an Iceberg desk, or check with Construct an Apache Iceberg information lake utilizing Amazon Athena, Amazon EMR, and AWS Glue weblog submit to create the Iceberg desk.
On this submit, we use Athena to transform the info. Full the next steps:
- Obtain the recordsdata utilizing the earlier hyperlink or use the AWS Command Line Interface (AWS CLI) to repeat the recordsdata from the general public S3 bucket for yr 2020 and 2021 to your S3 bucket utilizing the next command:
For extra info, check with Organising the Amazon Redshift CLI.
- Create a database
Icebergdband create a desk utilizing Athena pointing to the Parquet format recordsdata utilizing the next assertion: - Validate the info within the Parquet desk utilizing the next SQL:

- Create an Iceberg desk in Athena with the next code. You’ll be able to see the desk sort properties as an Iceberg desk with Parquet format and snappy compression within the following
create deskassertion. It is advisable replace the S3 location earlier than operating the SQL. Additionally word that the Iceberg desk is partitioned with the12 monthskey. - After you create the desk, load the info into the Iceberg desk utilizing the beforehand loaded Parquet desk
nyc_taxi_yellow_parquetwith the next SQL: - When the SQL assertion is full, validate the info within the Iceberg desk
nyc_taxi_yellow_iceberg. This step is required earlier than transferring to the subsequent step. - You’ll be able to validate that the nyc_taxi_yellow_iceberg desk is in Iceberg format desk and partitioned on the 12 months column utilizing the next command:



Create an exterior schema in Amazon Redshift
On this part, we reveal create an exterior schema in Amazon Redshift pointing to the AWS Glue database icebergdb to question the Iceberg desk nyc_taxi_yellow_iceberg that we noticed within the earlier part utilizing Athena.
Log in to the Redshift through Question Editor v2 or a SQL consumer and run the next command (word that the AWS Glue database icebergdb and Area info is getting used):
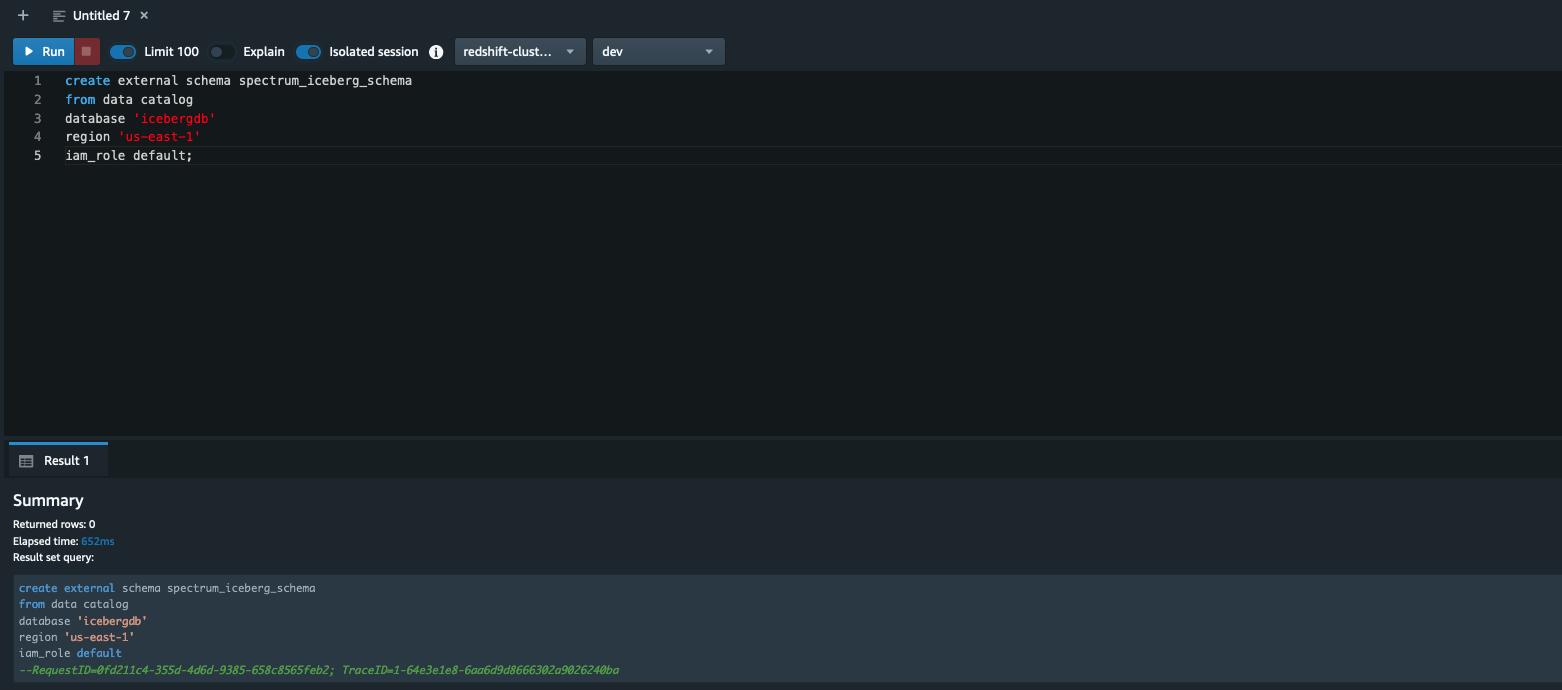
To study creating exterior schemas in Amazon Redshift, check with create exterior schema
After you create the exterior schema spectrum_iceberg_schema, you’ll be able to question the Iceberg desk in Amazon Redshift.
Question the Iceberg desk in Amazon Redshift
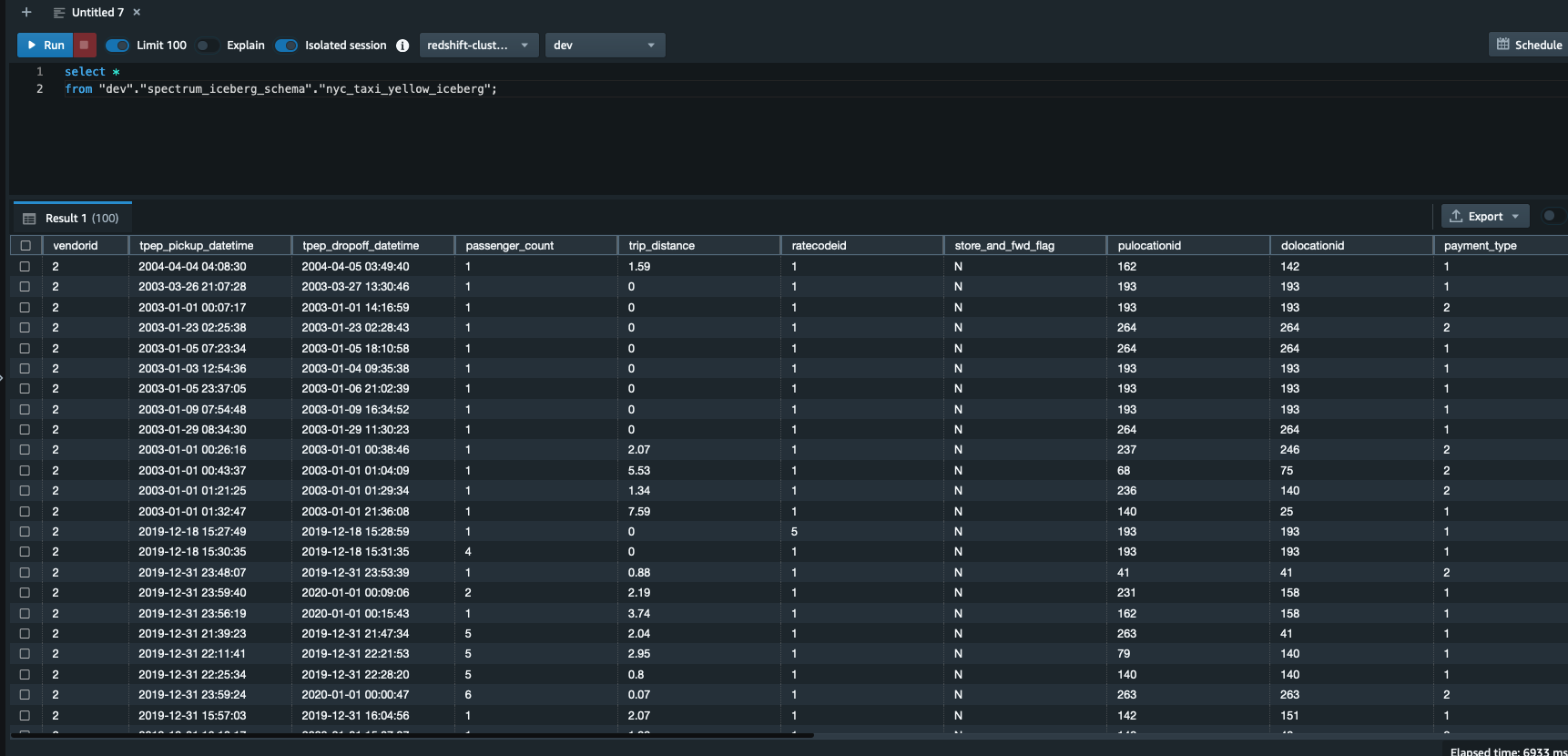
Run the next question in Question Editor v2. Be aware that spectrum_iceberg_schema is the identify of the exterior schema created in Amazon Redshift and nyc_taxi_yellow_iceberg is the desk within the AWS Glue database used within the question:
The question information output within the following screenshot reveals that the AWS Glue desk with Iceberg format is queryable utilizing Redshift Spectrum.
Examine the clarify plan of querying the Iceberg desk
You need to use the next question to get the clarify plan output, which reveals the format is ICEBERG:

Validate updates for information consistency
After the replace is full on the Iceberg desk, you’ll be able to question Amazon Redshift to see the transactionally constant view of the info. Let’s run a question by selecting a vendorid and for a sure pick-up and drop-off:
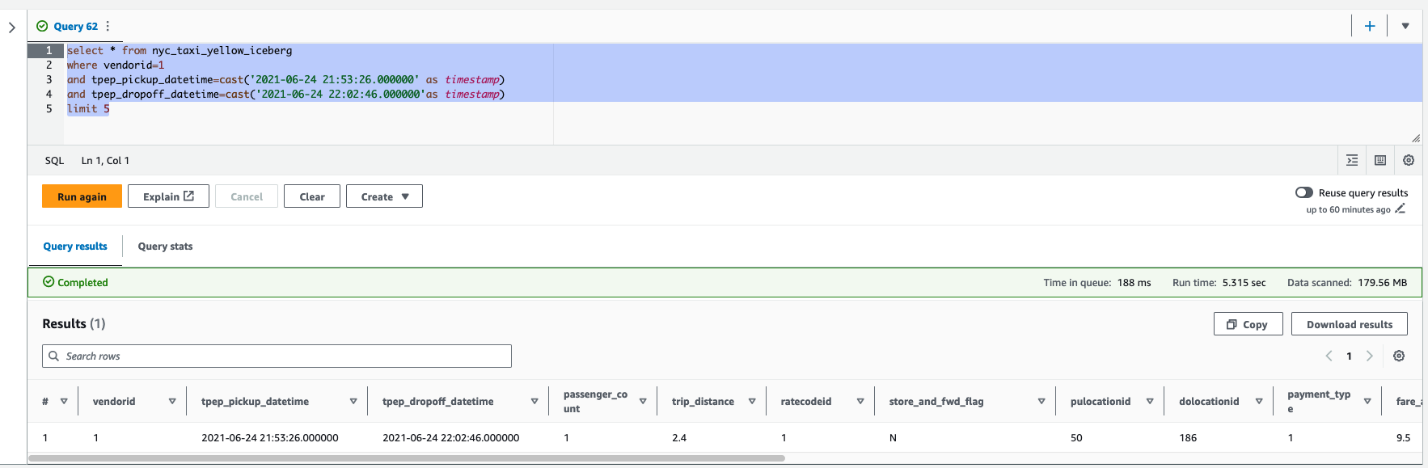
Subsequent, replace the worth of passenger_count to 4 and trip_distance to 9.4 for a vendorid and sure pick-up and drop-off dates in Athena:
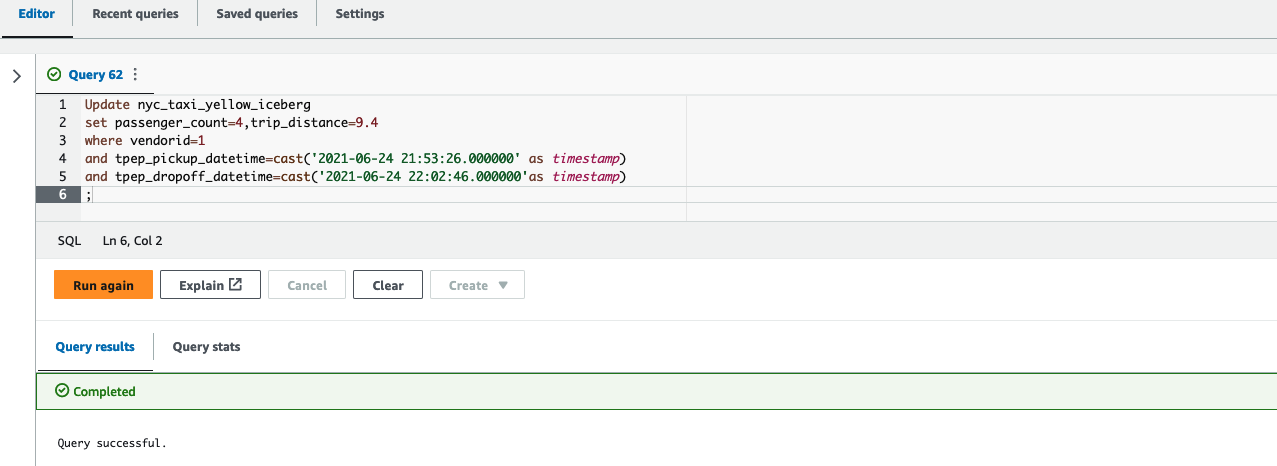
Lastly, run the next question in Question Editor v2 to see the up to date worth of passenger_count and trip_distance:
As proven within the following screenshot, the replace operations on the Iceberg desk can be found in Amazon Redshift.

Create a unified view of the native desk and historic information in Amazon Redshift
As a contemporary information structure technique, you’ll be able to arrange historic information or much less often accessed information within the information lake and maintain often accessed information within the Redshift information warehouse. This supplies the pliability to handle analytics at scale and discover essentially the most cost-effective structure answer.
On this instance, we load 2 years of knowledge in a Redshift desk; the remainder of the info stays on the S3 information lake as a result of that dataset is much less often queried.
- Use the next code to load 2 years of knowledge within the
nyc_taxi_yellow_recentdesk in Amazon Redshift, sourcing from the Iceberg desk:
- Subsequent, you’ll be able to take away the final 2 years of knowledge from the Iceberg desk utilizing the next command in Athena since you loaded the info right into a Redshift desk within the earlier step:

After you full these steps, the Redshift desk has 2 years of the info and the remainder of the info is within the Iceberg desk in Amazon S3.
- Create a view utilizing the
nyc_taxi_yellow_icebergIceberg desk andnyc_taxi_yellow_recentdesk in Amazon Redshift: - Now question the view, relying on the filter situations, Redshift Spectrum will scan both the Iceberg information, the Redshift desk, or each. The next instance question returns plenty of data from every of the supply tables by scanning each tables:

Partition evolution
Iceberg makes use of hidden partitioning, which suggests you don’t must manually add partitions in your Apache Iceberg tables. New partition values or new partition specs (add or take away partition columns) in Apache Iceberg tables are routinely detected by Amazon Redshift and no handbook operation is required to replace partitions within the desk definition. The next instance demonstrates this.
In our instance, if the Iceberg desk nyc_taxi_yellow_iceberg was initially partitioned by yr and later the column vendorid was added as an extra partition column, then Amazon Redshift can seamlessly question the Iceberg desk nyc_taxi_yellow_iceberg with two completely different partition schemes over a time frame.
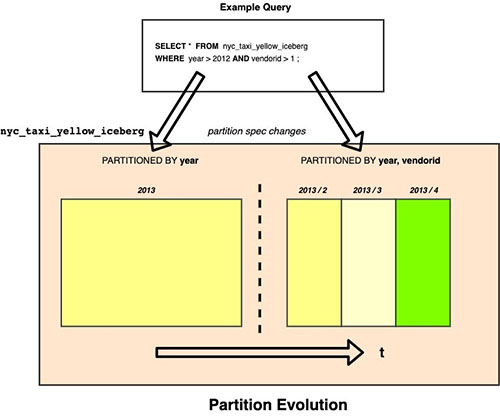
Issues when querying Iceberg tables utilizing Amazon Redshift
In the course of the preview interval, contemplate the next when utilizing Amazon Redshift with Iceberg tables:
- Solely Iceberg tables outlined within the AWS Glue Information Catalog are supported.
- CREATE or ALTER exterior desk instructions aren’t supported, which suggests the Iceberg desk ought to exist already in an AWS Glue database.
- Time journey queries aren’t supported.
- Iceberg variations 1 and a couple of are supported. For extra particulars on Iceberg format variations, check with Format Versioning.
- For a listing of supported information sorts with Iceberg tables, check with Supported information sorts with Apache Iceberg tables (preview).
- Pricing for querying an Iceberg desk is similar as accessing another information codecs utilizing Amazon Redshift.
For added particulars on concerns for Iceberg format tables preview, check with Utilizing Apache Iceberg tables with Amazon Redshift (preview).
Buyer suggestions
“Tinuiti, the most important impartial efficiency advertising agency, handles giant volumes of knowledge every day and will need to have a strong information lake and information warehouse technique for our market intelligence groups to retailer and analyze all our buyer information in a straightforward, reasonably priced, safe, and strong manner,” says Justin Manus, Chief Expertise Officer at Tinuiti. “Amazon Redshift’s assist for Apache Iceberg tables in our information lake, which is the one supply of fact, addresses a important problem in optimizing efficiency and accessibility and additional simplifies our information integration pipelines to entry all the info ingested from completely different sources and to energy our prospects’ model potential.”
Conclusion
On this submit, we confirmed you an instance of querying an Iceberg desk in Redshift utilizing recordsdata saved in Amazon S3, cataloged as a desk within the AWS Glue Information Catalog, and demonstrated a few of the key options like environment friendly row-level replace and delete, and the schema evolution expertise for customers to unlock the facility of massive information utilizing Athena.
You need to use Amazon Redshift to run queries on information lake tables in numerous recordsdata and desk codecs, comparable to Apache Hudi and Delta Lake, and now with Apache Iceberg (preview), which supplies extra choices in your trendy information architectures wants.
We hope this offers you a fantastic place to begin for querying Iceberg tables in Amazon Redshift.
In regards to the Authors
 Rohit Bansal is an Analytics Specialist Options Architect at AWS. He focuses on Amazon Redshift and works with prospects to construct next-generation analytics options utilizing different AWS Analytics companies.
Rohit Bansal is an Analytics Specialist Options Architect at AWS. He focuses on Amazon Redshift and works with prospects to construct next-generation analytics options utilizing different AWS Analytics companies.
 Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He’s an avid large information fanatic who collaborates with prospects across the globe to attain success and meet their information warehousing and information lake structure wants.
Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He’s an avid large information fanatic who collaborates with prospects across the globe to attain success and meet their information warehousing and information lake structure wants.
 Ranjan Burman is an Analytics Specialist Options Architect at AWS. He focuses on Amazon Redshift and helps prospects construct scalable analytical options. He has greater than 16 years of expertise in numerous database and information warehousing applied sciences. He’s obsessed with automating and fixing buyer issues with cloud options.
Ranjan Burman is an Analytics Specialist Options Architect at AWS. He focuses on Amazon Redshift and helps prospects construct scalable analytical options. He has greater than 16 years of expertise in numerous database and information warehousing applied sciences. He’s obsessed with automating and fixing buyer issues with cloud options.
[ad_2]