
[ad_1]
Introduction
Image this: You’re looking for merchandise that appear like one thing you’ve seen and beloved earlier than. Discovering visually comparable objects generally is a game-changer, whether or not trend, house decor, or devices. However how do you navigate via an enormous sea of photographs to pinpoint these good matches?
Enter the world of strong picture retrieval methods. These digital wizards have the facility to establish objects with strikingly comparable visible options and current them to you want a personalised buying assistant. Right here’s the key sauce: Picture retrieval discovers photographs resembling a given question picture inside a large dataset. Previously, this was typically executed by evaluating pixel values immediately – a sluggish and not-so-accurate course of. However concern not; there’s a better approach.
We’re speaking about embeddings and cosine similarity – the dynamic duo of contemporary picture retrieval. Embeddings are like magic codes representing photographs in a compact, feature-packed format. They seize the essence of a picture, its distinctive visible fingerprint, if you’ll. After which comes cosine similarity, the genius behind the scenes. It measures these embeddings’ similarity, providing you with lightning-fast and extremely correct outcomes.
With this powerhouse combo, you possibly can say goodbye to the times of scrolling endlessly to seek out that good look-alike. Due to embeddings and cosine similarity, you’ll simply uncover visually comparable photographs and merchandise, making your on-line buying expertise extra environment friendly and fulfilling than ever earlier than.
Studying Aims
On this article, you’ll study
- Introduction to Neo4j – a graph database administration system.
- Picture retrieval significance and enterprise use circumstances.
- Embedding technology utilizing pretrained CNNs
- Storing and Retrieving embeddings utilizing Neo4j
- Creating relationships between Neo4j nodes utilizing embedding’s cosine similarity.
This text was revealed as part of the Information Science Blogathon.
What’s Neo4j?
Neo4j is a graph database that permits us to retailer information within the type of nodes and relationships. Graph databases optimize graph computations, making them supreme for storing and querying graph information. Numerous corporations, together with eBay and Walmart, use Neo4j, a well-liked graph database. It additionally finds use amongst startups like Medium and Coursera
What are the Benefits of Utilizing Graph Databases?
- Advanced Relationship Dealing with: Supreme for social networks and complicated connections.
- Schema Flexibility: Adapt to evolving information buildings effortlessly.
- Native Question Language: Use Cypher for expressive graph queries.
- Traversal Efficiency: Effectively navigate relationships, e.g., shortest paths.
- Scalability: Deal with large datasets and elevated workloads.
- Expressive Information Modeling: Versatile modeling for varied buildings.
- Advanced Question Assist: Proficiently execute intricate graph queries.
- Sample Matching Efficiency: Distinctive in superior sample matching.
- Actual-Time Insights: Presents instantaneous insights into linked information.
Significance of Environment friendly Picture Retrieval
Environment friendly picture retrieval is essential in varied domains, together with e-commerce, content material sharing platforms, healthcare, and extra. It permits customers to shortly discover visually comparable photographs, aiding in product suggestions, content material curation, medical picture evaluation, and extra. By bettering retrieval velocity and accuracy, companies can improve consumer experiences, improve engagement, and make better-informed choices based mostly on picture information.
The next strategy have 2 elements:
Half 1: Producing Embeddings and Storing Information in Neo4j
1. Information Preparation
For simplicity, I scraped few automobile photographs from google and saved them in a folder referred to as photographs. The pictures are saved within the .jpg format.
import torch
import torchvision.transforms as transforms
...
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])Pretrained networks works properly if we resize the pictures to it enter layer dimension after we are producing embeddings. On this case, we shall be utilizing ResNet50, which takes in photographs of dimension 224×224. We shall be resizing the pictures to this dimension earlier than producing embeddings.
Submit resizing, we are going to normalize the pictures utilizing the imply and normal deviation of the ImageNet dataset. That is executed to make sure that the pictures are in the identical format as the pictures used to coach the community.
2. Producing Embeddings
For embedding technology, we shall be utilizing a pre-trained mannequin referred to as ResNet50. ResNet50 is a convolutional neural community that’s 50 layers deep. Its skip connections make it simpler to coach than a equally deep plain community. It’s skilled on greater than 1,000,000 photographs from the ImageNet database. The community is skilled to categorise photographs into 1000 object classes. We shall be utilizing the community to generate embeddings for our photographs.
When the networks layers are trimmed, we will use the community to generate embeddings for our photographs. The embeddings generated by the community shall be 2048-dimensional. These embeddings shall be used to retrieve comparable photographs.
Mannequin loading
import torchvision.fashions as fashions
mannequin = fashions.resnet50(pretrained=True)
mannequin = nn.Sequential(*record(mannequin.youngsters())[:-1])
mannequin = fashions.resnet50(pretrained=True)
mannequin = nn.Sequential(*record(mannequin.youngsters())[:-1]) def get_image_embeddings(image_path):
img = Picture.open(image_path).convert('RGB')
img = preprocess(img)
img = img.unsqueeze(0) # Add batch dimension
with torch.no_grad():
embeddings = mannequin(img)
return embeddings.squeeze().numpy()3. Storing Information in Neo4j
We shall be utilizing Neo4j to retailer the embeddings and the picture paths. Neo4j is a graph database that permits us to retailer information within the type of nodes and relationships. We shall be storing the embeddings as node properties and the picture paths as node labels. We can even be making a relationship between the embeddings and the picture paths. This may enable us to question the database for comparable photographs.
from neo4j import GraphDatabase
# Hook up with the Neo4j database
uri = "<neo4j_bolt_url>"
username = "<neo4j_username>"
password = "<neo4j_password>"
class Neo4jDatabase:
def __init__(self):
self._driver = GraphDatabase.driver(uri, auth=(username, password))
def shut(self):
self._driver.shut()
def create_image_node(self, embeddings,path):
with self._driver.session() as session:
session.write_transaction(self._create_image_node, embeddings,path)
@staticmethod
def _create_image_node(tx, embeddings,path):
question = (
"CREATE (img:Picture {embeddings: $embeddings,path: $path})"
)
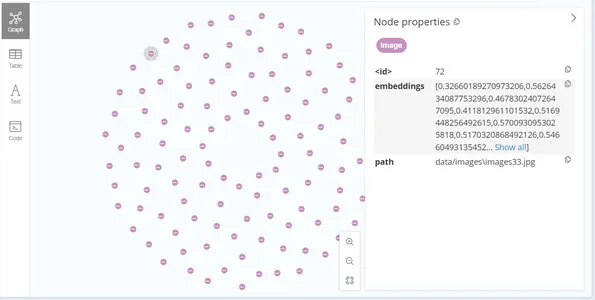
tx.run(question, embeddings=embeddings,path = path)After the info insertion, the graph seems to be like this:
Half 2: Picture Retrieval
For the inference half, the place we have to predict the same photographs, we shall be utilizing the cosine similarity metric. Cosine similarity is a measure of similarity between two non-zero vectors of an internal product house. It’s outlined to equal the cosine of the angle between them, which can be the identical because the internal product of the identical vectors normalized to each have size 1. We shall be utilizing the embeddings generated by the ResNet50 mannequin to calculate the cosine similarity between the question picture and the pictures within the database. The pictures with the best cosine similarity would be the most just like the question picture.
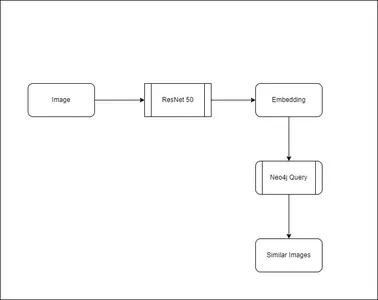
First the picture embeddings are generated for the question picture. Then it’s handed to the Neo4j database to retrieve the same photographs.
MATCH (a:Picture)
WITH a, gds.similarity.cosine(a.embeddings, $query_embeddings) AS similarity
ORDER BY similarity DESC
LIMIT $top_k
RETURN a.id AS image_id, a.embeddings AS embeddings, a.path as image_path, similarityThe above question returns the highest ok comparable photographs to the question picture. The question returns the picture id, picture path, and the cosine similarity between the question picture and the retrieved photographs. Use the cosine similarity to rank the pictures in descending order. Return the highest ok photographs. The node even have the picture path as a property, which may retrieve the picture from the file system.
The Neo4j server performs these computations, leading to considerably sooner processing in comparison with client-side execution. This effectivity is attributed to the server’s optimization for graph computations. Node properties retailer the embeddings in a columnar format, facilitating speedy retrieval. Moreover, the Neo4j server handles the computation of cosine similarity, leveraging its optimization for graph computations. This permits for sooner retrieval of comparable photographs.
Streamlit App
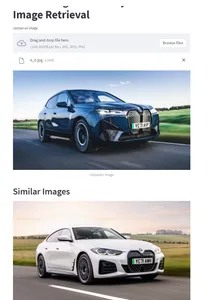
I’ve created a pattern StreamLit app to check our logics.
The UI have an choice to add a picture. It processes within the under circulate get fetch the related photographs.
- Generates Picture embeddings utilizing Resnet50 mannequin
- Queries Neo4j DB to fetch comparable embeddings and picture areas
- Shows the same photographs again to the UI
Sounds attention-grabbing?
The code for the pattern app is right here.
Creating Relations Between Nodes
Let’s say, if we’re dealing with with solely restricted photographs and we wish to create relations between them. We will use the next code to create relations between the pictures.
This permits to keep away from the similarity calculations for each question we do.
MATCH (n1:Picture), (n2:Picture)
WHERE id(n1) < id(n2) // To keep away from duplicate pairs and self-comparisons
WITH n1, n2, gds.similarity.cosine(n1.embeddings, n2.embeddings) AS similarity
WHERE similarity > 0.8
CREATE (n1)-[:SIMILAR_TO {score: similarity}]->(n2)This creates a relations, and it may be seen within the Neo4j graph.
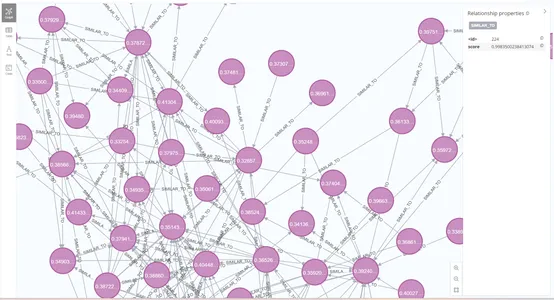
Once we question the database for comparable photographs, we will additionally embody the relations within the question. This may enable us to retrieve the same photographs together with the relations between them. Use this to visualise the relations between the pictures.
MATCH (a:Picture)-[r:SIMILAR_TO]->(b:Picture)
WITH a, b, gds.similarity.cosine(a.embeddings, $query_embeddings) AS similarity, r
ORDER BY similarity DESC
LIMIT $top_k
RETURN a.id AS image_id, a.embeddings AS embeddings, a.path as image_path, similarity, rConclusion
On this article, we noticed easy methods to generate embeddings for photographs utilizing a pre-trained mannequin. We additionally noticed easy methods to retailer the embeddings and picture paths in Neo4j. Lastly, we noticed easy methods to retrieve comparable photographs utilizing the cosine similarity metric. This strategy allows environment friendly retrieval of comparable photographs. It finds functions in varied domains, together with e-commerce, content material sharing platforms, healthcare, and extra. Based mostly on the info set we’ve got, we will additionally strive totally different picture embeddings fashions and similarity metrics to mess around.
Often Requested Questions
A. Picture embeddings compress photographs into lower-dimensional vector representations, offering a numerical illustration of the picture content material. You possibly can generate picture embeddings via totally different strategies, equivalent to CNNs, unsupervised studying, pre-trained networks, and switch studying.
A. A graph embedding determines a set size vector illustration for every entity (normally nodes) in our graph. These embeddings are a decrease dimensional illustration of the graph and protect the graph’s topology.
A. Neo4j CQL question language instructions are in humane readable format and really simple to study. It makes use of easy and highly effective information mannequin. It does NOT require complicated Joins to retrieve linked/associated information as it is rather simple to retrieve its adjoining node or relationship particulars with out Joins or Indexes.
A. Relationships describe a connection between a supply node and a goal node. They all the time have a path (one path). It will need to have a kind (one kind) to outline (classify) what kind of relationship they’re.
The media proven on this article shouldn’t be owned by Analytics Vidhya and is used on the Writer’s discretion.
Associated
[ad_2]