
[ad_1]
LLMs current an enormous alternative for organizations of all scales to rapidly construct highly effective functions and ship enterprise worth. The place information scientists used to spend hundreds of hours coaching and retraining fashions to carry out very restricted duties, they’ll now leverage a large basis of SaaS and open supply fashions to ship far more versatile and clever functions in a fraction of the time. Utilizing few-shot and zero-shot studying strategies like immediate engineering, information scientists can rapidly construct high-accuracy classifiers for various units of knowledge, state-of-the-art sentiment evaluation fashions, low-latency doc summarizers, and far more.
Nonetheless, to be able to establish the perfect fashions for manufacturing and deploy them safely, organizations want the best instruments and processes in place. Probably the most important elements is powerful mannequin analysis. With mannequin high quality challenges like hallucination, response toxicity, and vulnerability to immediate injection, as nicely an absence of floor fact labels for a lot of duties, information scientists must be extraordinarily diligent about evaluating their fashions’ efficiency on all kinds of knowledge. Information scientists additionally want to have the ability to establish delicate variations between a number of mannequin candidates to pick the perfect one for manufacturing. Now greater than ever, you want an LLMOps platform that gives an in depth efficiency report for each mannequin , helps you establish weaknesses and vulnerabilities lengthy earlier than manufacturing, and streamlines mannequin comparability.
To fulfill these wants, we’re thrilled to announce the arrival of MLflow 2.4, which supplies a complete set of LLMOps instruments for mannequin analysis. With new mlflow.consider() integrations for language duties, a model new Artifact View UI for evaluating textual content outputs throughout a number of mannequin variations, and long-anticipated dataset monitoring capabilities, MLflow 2.4 accelerates growth with LLMs.
Seize efficiency insights with mlflow.consider() for language fashions
To evaluate the efficiency of a language mannequin, it’s essential feed it quite a lot of enter datasets, document the corresponding outputs, and compute domain-specific metrics. In MLflow 2.4, we’ve prolonged MLflow’s highly effective analysis API – mlflow.consider() – to dramatically simplify this course of. With a single line of code, you’ll be able to observe mannequin predictions and efficiency metrics for all kinds of duties with LLMs, together with textual content summarization, textual content classification, query answering, and textual content era. All of this data is recorded to MLflow Monitoring, the place you’ll be able to examine and examine efficiency evaluations throughout a number of fashions to be able to choose the perfect candidates for manufacturing.
The next instance code makes use of mlflow.consider() to rapidly seize efficiency data for a summarization mannequin:
import mlflow
# Consider a information summarization mannequin on a take a look at dataset
summary_test_data = mlflow.information.load_delta(table_name="ml.cnn_dailymail.take a look at")
evaluation_results = mlflow.consider(
"runs:/d13953d1da1a41a59bf6a32fde599c63/summarization_model",
information=summary_test_data,
model_type="summarization",
targets="highlights"
)
# Confirm that ROUGE metrics are routinely computed for summarization
assert "rouge1" in evaluation_results.metrics
assert "rouge2" in evaluation_results.metrics
# Confirm that inputs and outputs are captured as a desk for additional evaluation
assert "eval_results_table" in evaluation_results.artifactsFor extra details about the mlflow.consider(), together with utilization examples, try the MLflow Documentation and examples repository.
Examine and examine LLM outputs with the brand new Artifact View
With out floor fact labels, many LLM builders have to manually examine mannequin outputs to evaluate high quality. This usually means studying via textual content produced by the mannequin, reminiscent of doc summaries, solutions to complicated questions, and generated prose. When choosing the right mannequin for manufacturing, these textual content outputs must be grouped and in contrast throughout fashions. For instance, when growing a doc summarization mannequin with LLMs, it’s essential to see how every mannequin summarizes a given doc and establish variations.
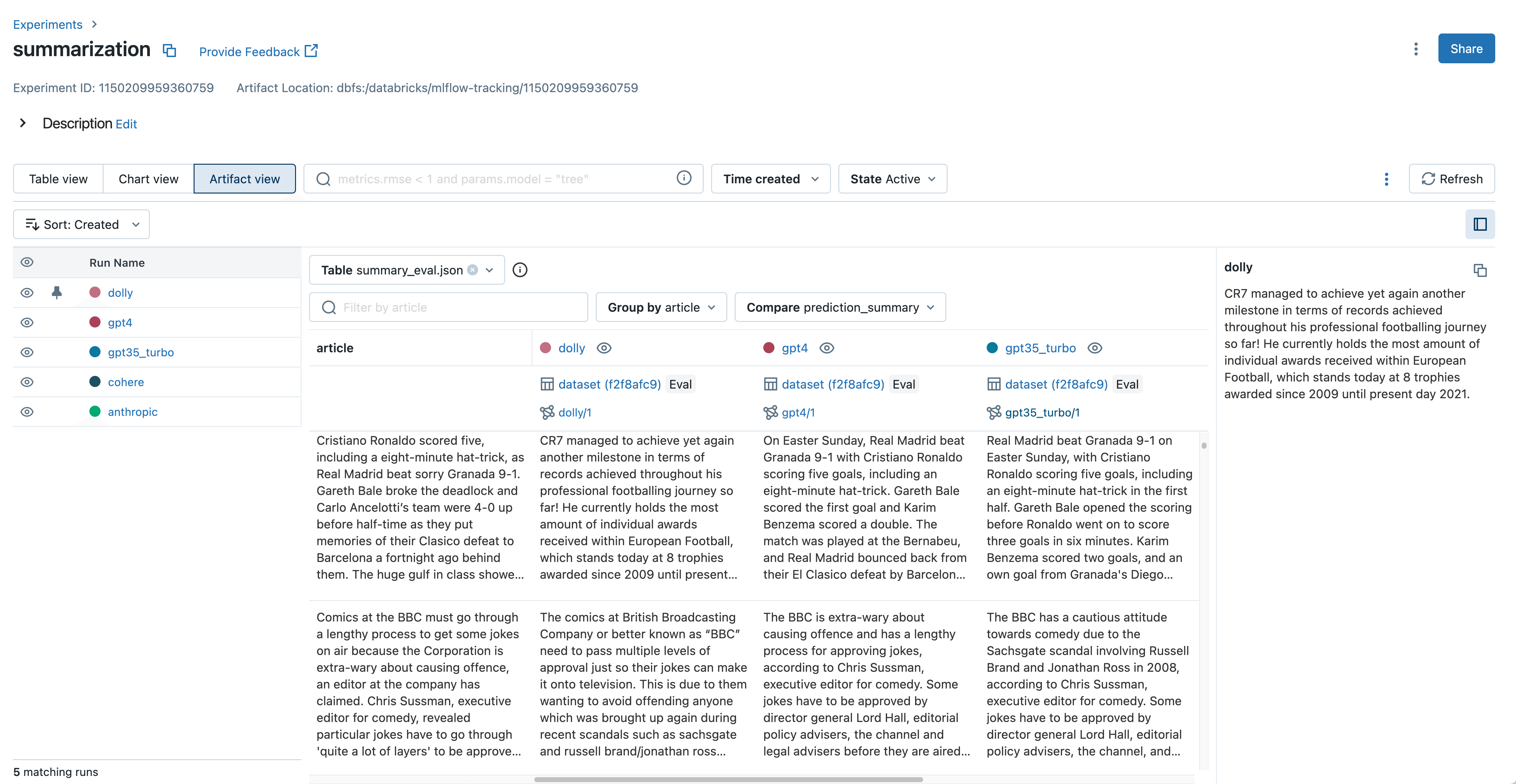
In MLflow 2.4, the brand new Artifact View in MLflow Monitoring streamlines this output inspection and comparability. With just some clicks, you’ll be able to view and examine textual content inputs, outputs, and intermediate outcomes from mlflow.consider() throughout your whole fashions. This makes it very simple to establish unhealthy outputs and perceive which immediate was used throughout inference. With the brand new mlflow.load_table() API in MLflow 2.4, you may as well obtain all the analysis outcomes displayed within the Artifact View to be used with Databricks SQL, information labeling, and extra. That is demonstrated within the following code instance:
import mlflow
# Consider a language mannequin
mlflow.consider(
"fashions:/my_language_model/1", information=test_dataset, model_type="textual content"
)
# Obtain analysis outcomes for additional evaluation
mlflow.load_table("eval_results_table.json")Observe your analysis datasets to make sure correct comparisons
Selecting the perfect mannequin for manufacturing requires thorough comparability of efficiency throughout completely different mannequin candidates. An important side of this comparability is guaranteeing that every one fashions are evaluated utilizing the identical dataset(s). In spite of everything, deciding on a mannequin with the perfect reported accuracy solely is sensible if each mannequin thought of was evaluated on the identical dataset.
In MLflow 2.4, we’re thrilled to introduce a long-anticipated characteristic to MLflow – Dataset Monitoring. This thrilling new characteristic standardizes the way in which you handle and analyze datasets throughout mannequin growth. With dataset monitoring, you’ll be able to rapidly establish which datasets had been used to develop and consider every of your fashions, guaranteeing truthful comparability and simplifying mannequin choice for manufacturing deployment.
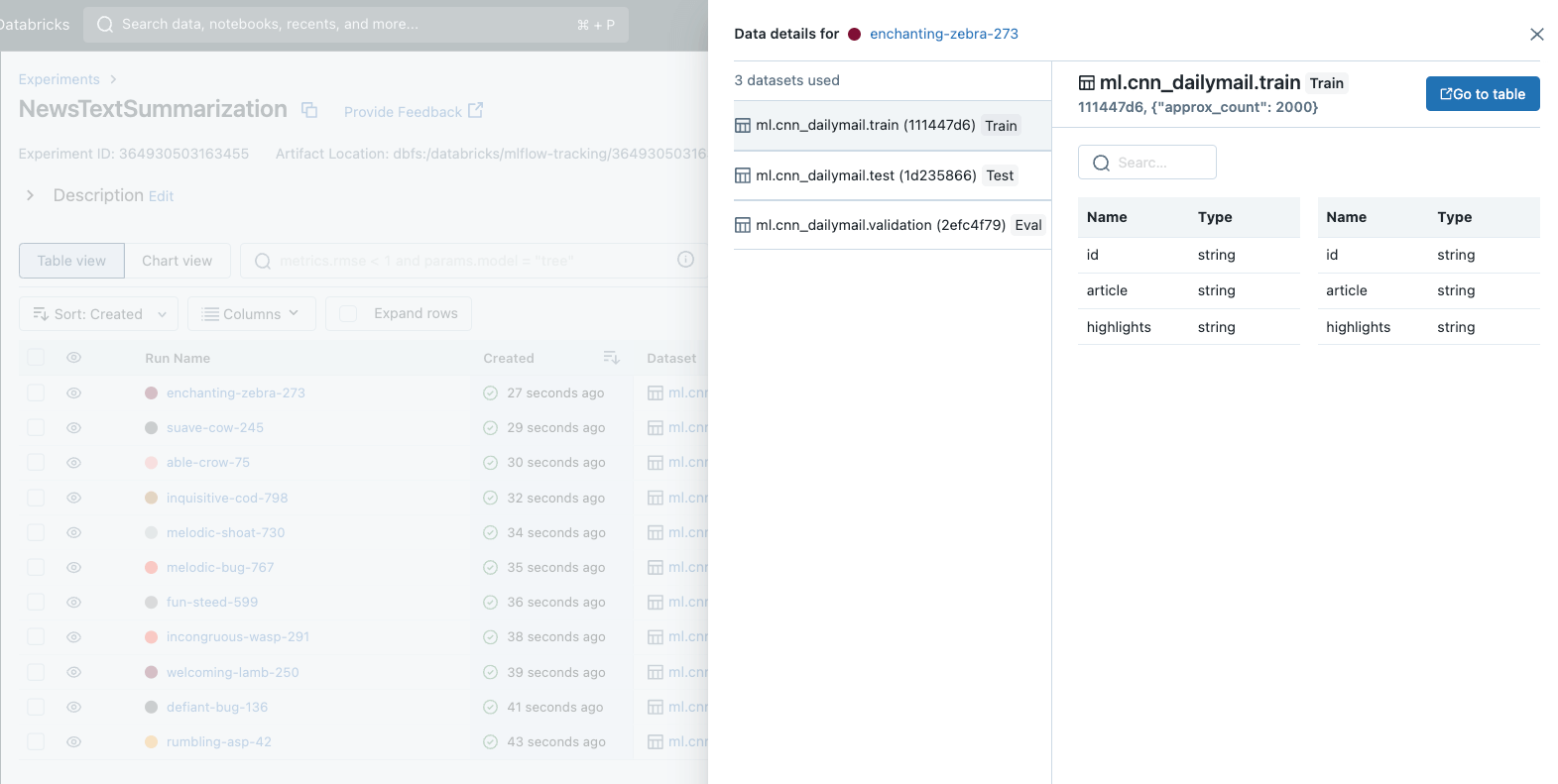
It’s very simple to get began with dataset monitoring in MLflow. To document dataset data to any of your MLflow Runs, merely name the mlflow.log_input() API. Dataset monitoring has additionally been built-in with Autologging in MLflow, offering information insights with no extra code required. All of this dataset data is displayed prominently within the MLflow Monitoring UI for evaluation and comparability. The next instance demonstrates the way to use mlflow.log_input() to log a coaching dataset to a run, retrieve details about the dataset from the run, and cargo the dataset’s supply:
import mlflow
# Load a dataset from Delta
dataset = mlflow.information.load_delta(table_name="ml.cnn_dailymail.prepare")
with mlflow.start_run():
# Log the dataset to the MLflow Run
mlflow.log_input(dataset, context="coaching")
# <Your mannequin coaching code goes right here>
# Retrieve the run, together with dataset data
run = mlflow.get_run(mlflow.last_active_run().information.run_id)
dataset_info = run.inputs.dataset_inputs[0].dataset
print(f"Dataset title: {dataset_info.title}")
print(f"Dataset digest: {dataset_info.digest}")
print(f"Dataset profile: {dataset_info.profile}")
print(f"Dataset schema: {dataset_info.schema}")
# Load the dataset's supply Delta desk
dataset_source = mlflow.information.get_source(dataset_info)
dataset_source.load()For extra dataset monitoring data and utilization guides, try the MLflow Documentation.
Get began with LLMOps instruments in MLflow 2.4
With the introduction of mlflow.consider() for language fashions, a brand new Artifact View for language mannequin comparability, and complete dataset monitoring, MLflow 2.4 continues to empower customers to construct extra sturdy, correct, and dependable fashions. Specifically, these enhancements dramatically enhance the expertise of growing functions with LLMs.
We’re excited so that you can expertise the brand new options of MLflow 2.4 for LLMOps. In the event you’re an present Databricks person, you can begin utilizing MLflow 2.4 right this moment by putting in the library in your pocket book or cluster. MLflow 2.4 may even be preinstalled in model 13.2 of the Databricks Machine Studying Runtime. Go to the Databricks MLflow information [AWS][Azure][GCP] to get began. In the event you’re not but a Databricks person, go to databricks.com/product/managed-mlflow to study extra and begin a free trial of Databricks and Managed MLflow 2.4. For a whole record of latest options and enhancements in MLflow 2.4, see the launch changelog.
[ad_2]