
[ad_1]
Apache Parquet is among the hottest open supply file codecs within the massive knowledge world right this moment. Being column-oriented, Apache Parquet permits for environment friendly knowledge storage and retrieval, and this has led many organizations over the previous decade to undertake it as a necessary solution to retailer knowledge in knowledge lakes. A few of these corporations went one step additional and determined to make use of Apache Parquet information as ‘database tables’ – performing CRUD operations on them. Nonetheless, Apache Parquet information, being simply knowledge information, with none transaction logging, statistics assortment and indexing capabilities aren’t good candidates for ACID compliant database operations. Constructing such tooling is a monumental activity that may require an enormous growth workforce to develop on their very own and to take care of it. The outcome was an Apache Parquet Knowledge Lake. It was a makeshift resolution at its finest, affected by points comparable to unintentional corruption of tables arising from brittle ACID compliance.
The answer got here within the type of the Delta Lake format. It was designed to resolve the precise issues Apache Parquet knowledge lakes have been riddled with. Apache Parquet was adopted as the bottom knowledge storage format for Delta Lake and the lacking transaction logging, statistics assortment and indexing capabilities have been in-built, offering it with the a lot wanted ACID compliance and ensures. Open supply Delta Lake, underneath the Linux Basis, has been going from energy to energy, discovering huge utilization within the trade.
Over time, organizations have realized important advantages shifting their Apache Parquet knowledge lake to Delta Lake, but it surely takes planning and collection of the correct strategy emigrate the information. There may even be situations the place a enterprise wants the Apache Parquet Knowledge Lake to co-exist even after migrating the information to Delta Lake. For instance, you may need an ETL pipeline that writes knowledge to tables saved in Apache Parquet Knowledge lake and you’ll want to carry out an in depth influence evaluation earlier than regularly migrating the information to Delta Lake. Till such time, you’ll want to maintain their Apache Parquet Knowledge Lake and Delta Lake in sync. On this weblog we’ll talk about a couple of related use circumstances and present you learn how to sort out them.
Benefits of shifting from Apache Parquet to Delta Lake
- Any dataset composed solely of Apache Parquet information, with none transaction log monitoring ‘what has modified’, results in a brittle conduct with respect to ACID transactions. Such conduct might trigger inconsistent reads throughout appending and modification of current knowledge. If write jobs fail mid-way, they might trigger partial writes. These inconsistencies might make stakeholders lose belief on the information in regulated environments that require reproducibility, auditing, and governance. Delta Lake format, in distinction, is a completely ACID compliant knowledge storage format.
- The time-travel characteristic of Delta Lake allows groups to have the ability to observe variations and the evolution of knowledge units. If there are any points with the information, the rollback characteristic provides groups the flexibility to return to a previous model. You’ll be able to then replay the information pipelines after implementing corrective measures.
- Delta Lake, owing to the bookkeeping processes within the type of transaction logs, file metadata, knowledge statistics and clustering methods, results in a big question efficiency enchancment over Apache Parquet primarily based knowledge lake.
- Schema enforcement rejects any new columns or different schema adjustments that are not appropriate along with your desk. By setting and upholding these excessive requirements, analysts and engineers can belief that their knowledge has the best ranges of integrity, and purpose about it with readability, permitting them to make higher enterprise selections. With Delta Lake customers have entry to easy semantics to manage the schema, which incorporates schema enforcement, that forestalls customers from unintentionally polluting their tables with errors or rubbish knowledge.
Schema evolution enhances enforcement by making it simple for meant schema adjustments to happen mechanically. Delta Lake makes it easy to mechanically add new columns of wealthy knowledge when these columns belong.
You’ll be able to seek advice from this Databricks Weblog collection to know Delta Lake inside performance.
Issues earlier than migrating to Delta Lake
The methodology that must be adopted for the migration of Apache Parquet Knowledge Lake to Delta Lake is dependent upon one or many migration necessities that are documented within the matrix beneath.
| Necessities ⇨
Strategies ⇩ |
Full overwrite at supply | Incremental with append at supply | Duplicates knowledge | Maintains knowledge construction | Backfill knowledge | Ease of use |
|---|---|---|---|---|---|---|
| Deep CLONE Apache Parquet | Sure | Sure | Sure | Sure | Sure | Straightforward |
| Shallow CLONE Apache Parquet | Sure | Sure | No | Sure | Sure | Straightforward |
| CONVERT TO DELTA | Sure | No | No | Sure | No | Straightforward |
| Auto Loader | Sure | Sure | Sure | No | Non-compulsory | Some configuration |
| Batch Apache Spark job | Customized logic | Customized logic | Sure | No | Customized logic | Customized logic |
| COPY INTO | Sure | Sure | Sure | No | Non-compulsory | Some configuration |
Desk 1 – Matrix to point out choices for migrations
Now let’s talk about the migration necessities and the way that impacts the selection of migration methodologies.
Necessities
- Full overwrite at supply: This requirement specifies that the information processing program fully refreshes the information in supply Apache Parquet knowledge lake every time it runs and knowledge ought to be fully refreshed within the goal Delta Lake after the conversion has begun
- Incremental with append at supply: This requirement specifies that the information processing program refreshes the information in supply Apache Parquet knowledge lake through the use of UPSERT (INSERT, UPDATE or DELETE) every time it runs and knowledge ought to be incrementally refreshed within the goal Delta Lake after the conversion has begun
- Duplicates knowledge: This requirement specifies that knowledge is written to a brand new location from the Apache Parquet Knowledge Lake to Delta Lake. If knowledge duplication is just not most well-liked and there’s no influence to the prevailing purposes then the Apache Parquet Knowledge Lake is modified to Delta Lake in place.
- Maintains knowledge construction: This requirement specifies if the information partitioning technique at supply is maintained throughout conversion.
- Backfill knowledge: Knowledge backfilling entails filling in lacking or outdated knowledge from the previous on a brand new system or updating outdated data. This course of is usually executed after an information anomaly or high quality subject has resulted in incorrect knowledge being entered into the information warehouse. Within the context of this weblog, the ‘backfill knowledge’ requirement specifies the performance that helps backfilling knowledge that has been added to the conversion supply after the conversion has begun.
- Ease of use: This requirement specifies the extent of person effort to configure and run the information conversion.
Methodologies with Particulars
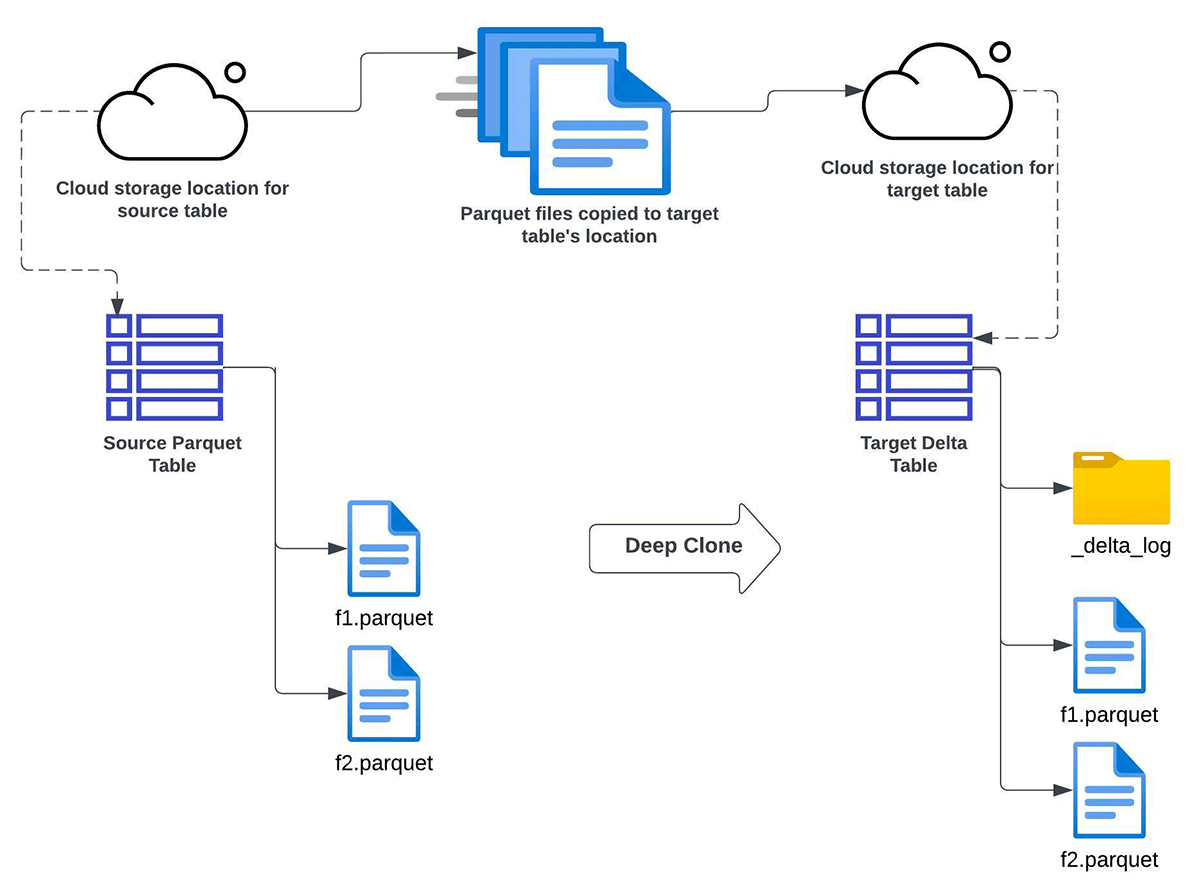
Deep CLONE Apache Parquet
You should use Databricks deep clone performance to incrementally convert knowledge from the Apache Parquet Knowledge lake to the Delta Lake. Use this strategy when all of the beneath standards are happy:
- you’ll want to both fully refresh or incrementally refresh the goal Delta Lake desk from a supply Apache Parquet desk
- in-place improve to Delta Lake is just not doable
- knowledge duplication (sustaining a number of copies) is suitable
- the goal schema must match the supply schema
- you might have a necessity for knowledge backfill. On this context, it means in future you possibly can have extra knowledge coming into the supply desk. By way of a subsequent Deep Clone operation, such new knowledge would get copied into and synchronized with the goal Delta Lake desk.
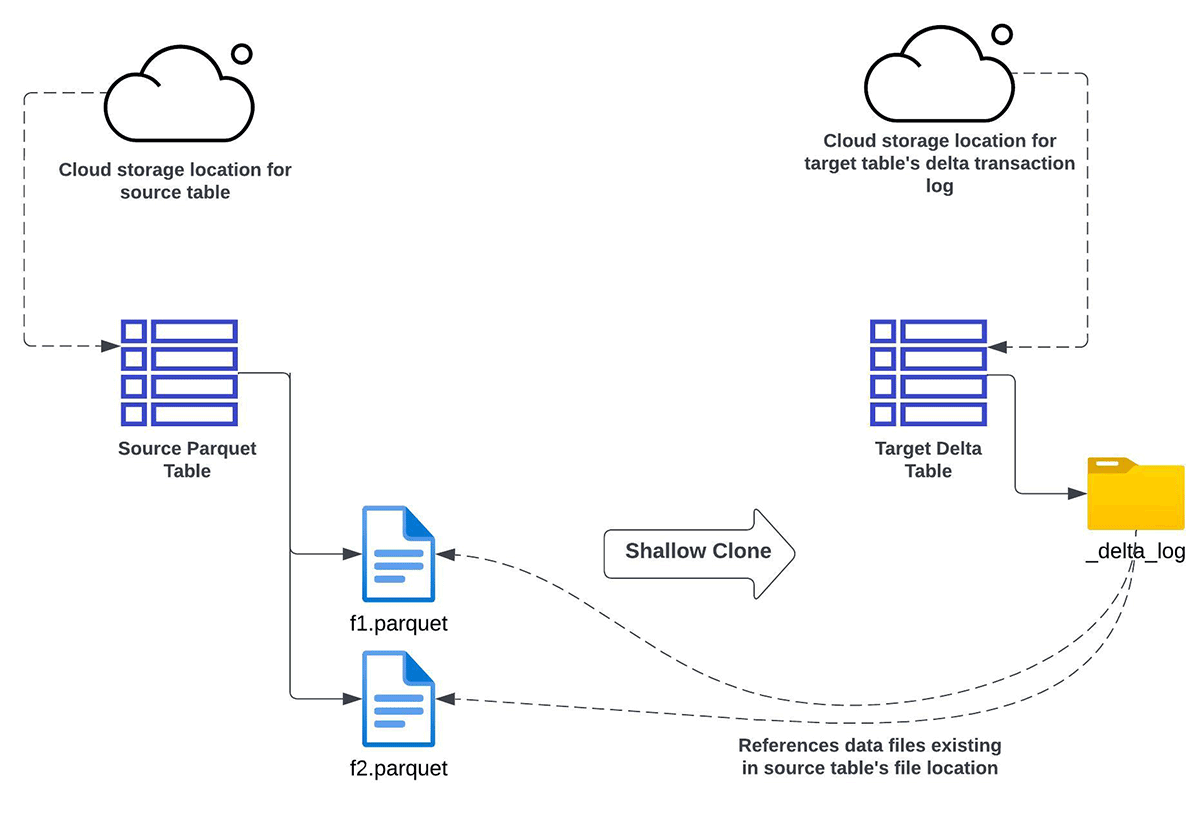
Shallow CLONE Apache Parquet
You should use Databricks shallow clone performance to incrementally convert knowledge from Apache Parquet Knowledge lake to Delta Lake, whenever you:
- need to both fully refresh or incrementally refresh the goal Delta Lake desk from a supply Apache Parquet desk
- don’t desire the information to be duplicated (or copied)
- need the identical schema between the supply and goal
- even have a necessity for knowledge backfilling. It means in future you possibly can have extra knowledge coming into the supply aspect. By way of a subsequent Shallow Clone operation, such new knowledge would get acknowledged (however not copied) within the goal Delta Lake desk.
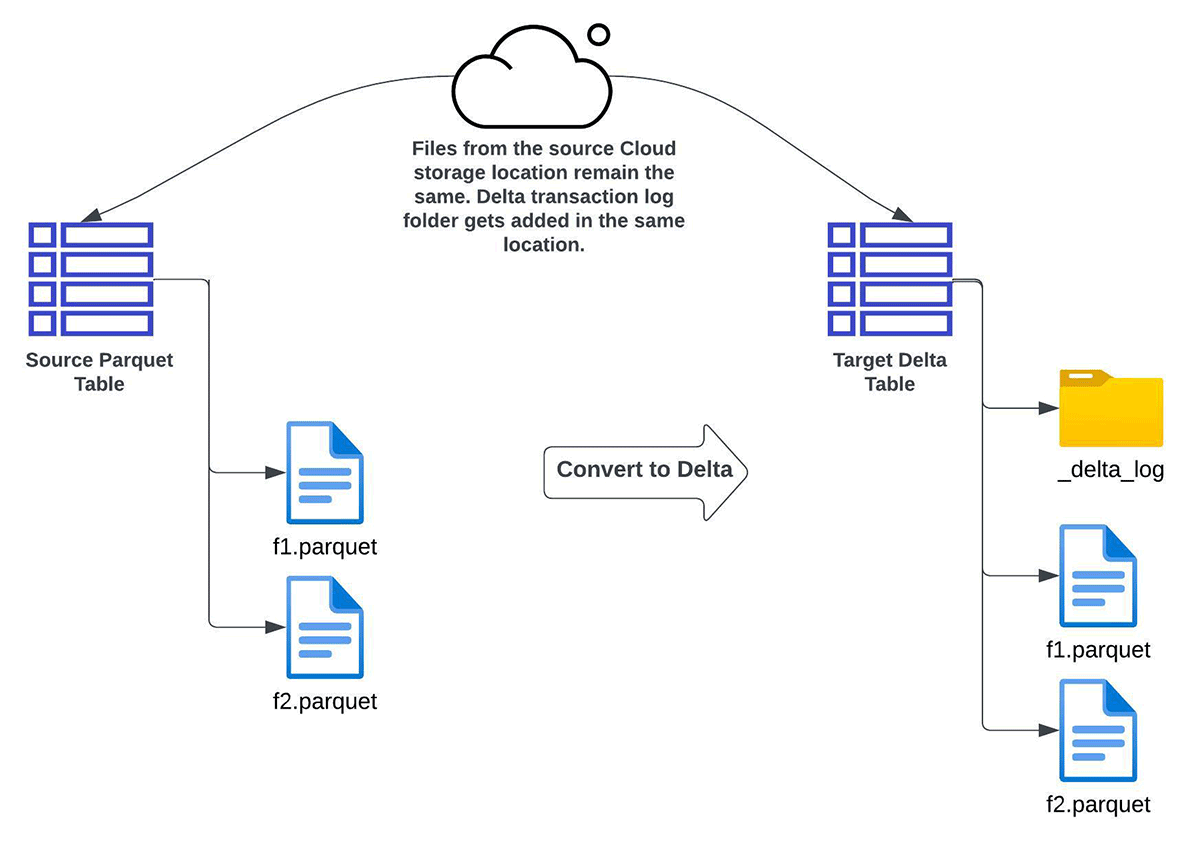
CONVERT TO DELTA
You should use Convert to Delta Lake characteristic when you’ve got necessities for:
- solely full refresh (and never incremental refresh) of the goal Delta Lake desk
- no a number of copies of the information i.e. knowledge must be transformed in place
- the supply and goal tables to have the identical schema
- no backfill of knowledge. On this context, it implies that knowledge written to the supply listing after the conversion has began might not mirror within the resultant goal Delta desk.
Because the supply is reworked right into a goal Delta Lake desk in-place, all future CRUD operations on the goal desk must occur by way of Delta Lake ACID transactions.
Be aware – Please seek advice from the Caveats earlier than utilizing the CONVERT TO DELTA choice. You need to keep away from updating or appending knowledge information through the conversion course of. After the desk is transformed, be sure all writes undergo Delta Lake.
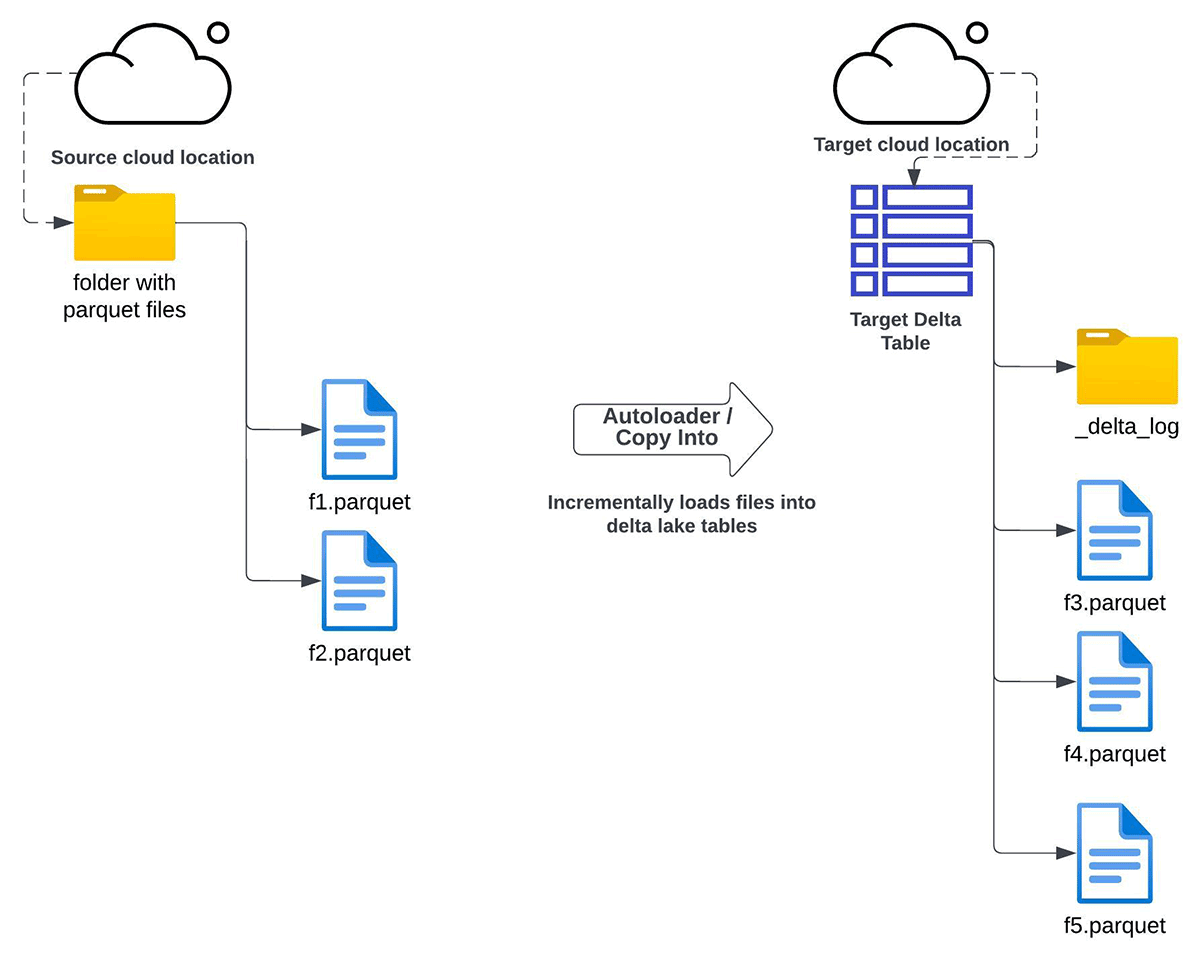
Auto Loader
You should use Auto Loader to incrementally copy all knowledge from a given cloud storage listing to a goal Delta desk. This strategy can be utilized for the beneath situations:
- you might have necessities for both full refresh or incremental refresh of the Delta Lake from Apache Parquet information saved in cloud object storage
- in place improve to a Delta Lake desk is just not doable
- knowledge duplication (a number of copies of information) is allowed
- sustaining the information construction (schema) between supply and goal after the migration is just not a requirement
- you do not need a particular want for knowledge backfilling, however nonetheless need to have it as an choice if want arises sooner or later
COPY INTO
You should use COPY INTO SQL command to incrementally copy all knowledge from a given cloud storage listing to a goal Delta desk. This strategy can be utilized for the beneath situations:
- When you’ve got necessities for both full refresh or incremental refresh of the Delta Lake desk from the Apache Parquet information saved within the cloud object storage
- in-place improve to a Delta Lake desk is just not doable
- knowledge duplication (a number of copies of information) is allowed
- adhering to the identical schema between supply and goal after migration is just not a requirement
- you do not need a particular want for knowledge backfill
Each Auto Loader and COPY INTO enable the customers loads of choices to configure the information motion course of. Discuss with this hyperlink when you’ll want to resolve between COPY INTO and Auto Loader.
Batch Apache Spark job
Lastly, you need to use customized Apache Spark logic emigrate to Delta Lake. It supplies nice flexibility in controlling how and when totally different knowledge out of your supply system is migrated, however may require in depth configuration and customization to supply capabilities already constructed into the opposite methodologies mentioned right here.
To carry out backfills or incremental migration, you may be capable of depend on the partitioning construction of your knowledge supply, however may additionally want to put in writing customized logic to trace which information have been added because you final loaded knowledge from the supply. Whereas you need to use Delta Lake merge capabilities to keep away from writing duplicate data, evaluating all data from a big Parquet supply desk to the contents of a giant Delta desk is a posh and computationally costly activity.
Discuss with this hyperlink for extra data on the methodologies of migrating your Apache Parquet Knowledge Lake to Delta Lake.
Conclusion
On this weblog, we’ve got described varied choices emigrate your Apache Parquet Knowledge Lake to Delta Lake and mentioned how one can decide the correct methodology primarily based in your necessities. To be taught extra concerning the Apache Parquet to Delta Lake migration and learn how to get began, please go to the guides (AWS, Azure, GCP). In these Notebooks we’ve got supplied a couple of examples so that you can get began and take a look at totally different choices for migration. Additionally it’s at all times beneficial to comply with optimization finest practices on Databricks after you migrate to Delta Lake.
[ad_2]