
[ad_1]
Streaming knowledge has develop into an indispensable useful resource for organizations worldwide as a result of it provides real-time insights which can be essential for knowledge analytics. The escalating velocity and magnitude of collected knowledge has created a requirement for real-time analytics. This knowledge originates from numerous sources, together with social media, sensors, logs, and clickstreams, amongst others. With streaming knowledge, organizations acquire a aggressive edge by promptly responding to real-time occasions and making well-informed selections.
In streaming functions, a prevalent method entails ingesting knowledge via Apache Kafka and processing it with Apache Spark Structured Streaming. Nevertheless, managing, integrating, and authenticating the processing framework (Apache Spark Structured Streaming) with the ingesting framework (Kafka) poses important challenges, necessitating a managed and serverless framework. For instance, integrating and authenticating a consumer like Spark streaming with Kafka brokers and zookeepers utilizing a guide TLS technique requires certificates and keystore administration, which isn’t a simple activity and requires a great data of TLS setup.
To deal with these points successfully, we suggest utilizing Amazon Managed Streaming for Apache Kafka (Amazon MSK), a totally managed Apache Kafka service that gives a seamless strategy to ingest and course of streaming knowledge. On this submit, we use Amazon MSK Serverless, a cluster sort for Amazon MSK that makes it attainable so that you can run Apache Kafka with out having to handle and scale cluster capability. To additional improve safety and streamline authentication and authorization processes, MSK Serverless allows you to deal with each authentication and authorization utilizing AWS Id and Entry Administration (IAM) in your cluster. This integration eliminates the necessity for separate mechanisms for authentication and authorization, simplifying and strengthening knowledge safety. For instance, when a consumer tries to put in writing to your cluster, MSK Serverless makes use of IAM to examine whether or not that consumer is an authenticated id and likewise whether or not it’s approved to provide to your cluster.
To course of knowledge successfully, we use AWS Glue, a serverless knowledge integration service that makes use of the Spark Structured Streaming framework and allows near-real-time knowledge processing. An AWS Glue streaming job can deal with massive volumes of incoming knowledge from MSK Serverless with IAM authentication. This highly effective mixture ensures that knowledge is processed securely and swiftly.
The submit demonstrates tips on how to construct an end-to-end implementation to course of knowledge from MSK Serverless utilizing an AWS Glue streaming extract, remodel, and cargo (ETL) job with IAM authentication to attach MSK Serverless from the AWS Glue job and question the info utilizing Amazon Athena.
Answer overview
The next diagram illustrates the structure that you just implement on this submit.
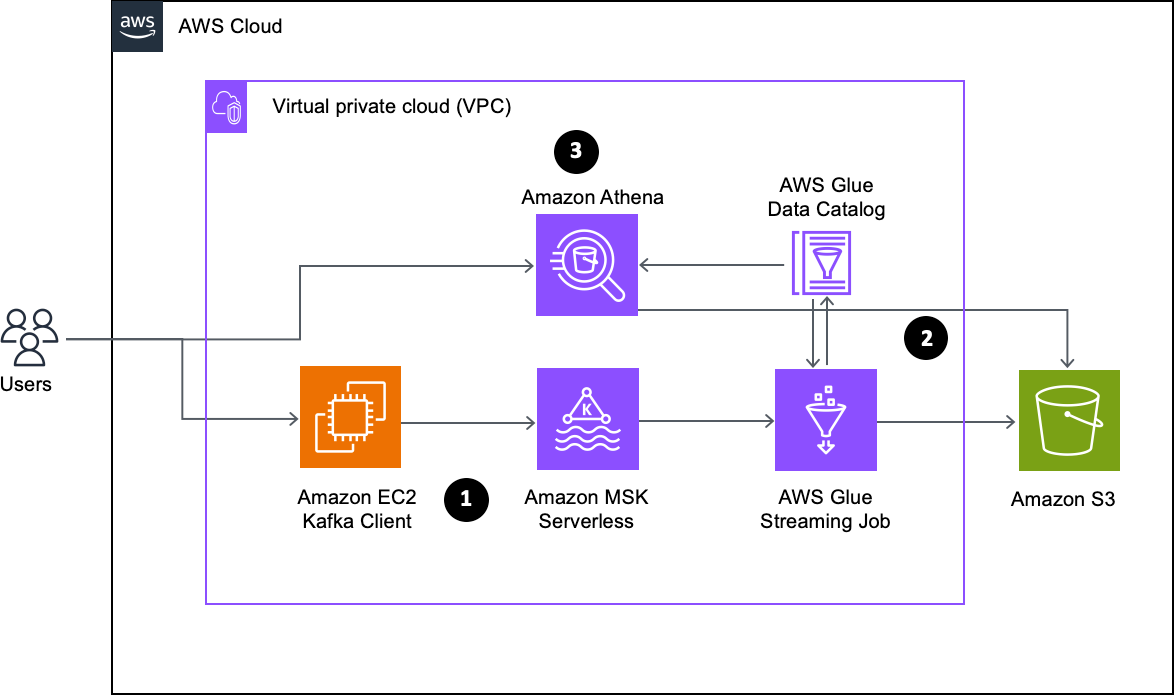
The workflow consists of the next steps:
- Create an MSK Serverless cluster with IAM authentication and an EC2 Kafka consumer because the producer to ingest pattern knowledge right into a Kafka matter. For this submit, we use the kafka-console-producer.sh Kafka console producer consumer.
- Arrange an AWS Glue streaming ETL job to course of the incoming knowledge. This job extracts knowledge from the Kafka matter, masses it into Amazon Easy Storage Service (Amazon S3), and creates a desk within the AWS Glue Information Catalog. By constantly consuming knowledge from the Kafka matter, the ETL job ensures it stays synchronized with the most recent streaming knowledge. Furthermore, the job incorporates the checkpointing performance, which tracks the processed data, enabling it to renew processing seamlessly from the purpose of interruption within the occasion of a job run failure.
- Following the info processing, the streaming job shops knowledge in Amazon S3 and generates a Information Catalog desk. This desk acts as a metadata layer for the info. To work together with the info saved in Amazon S3, you should utilize Athena, a serverless and interactive question service. Athena allows the run of SQL-like queries on the info, facilitating seamless exploration and evaluation.
For this submit, we create the answer assets within the us-east-1 Area utilizing AWS CloudFormation templates. Within the following sections, we present you tips on how to configure your assets and implement the answer.
Configure assets with AWS CloudFormation
On this submit, you employ the next two CloudFormation templates. The benefit of utilizing two totally different templates is that you would be able to decouple the useful resource creation of ingestion and processing half in accordance with your use case and you probably have necessities to create particular course of assets solely.
- vpc-mskserverless-client.yaml – This template units up knowledge the ingestion service assets similar to a VPC, MSK Serverless cluster, and S3 bucket
- gluejob-setup.yaml – This template units up the info processing assets such because the AWS Glue desk, database, connection, and streaming job
Create knowledge ingestion assets
The vpc-mskserverless-client.yaml stack creates a VPC, non-public and public subnets, safety teams, S3 VPC Endpoint, MSK Serverless cluster, EC2 occasion with Kafka consumer, and S3 bucket. To create the answer assets for knowledge ingestion, full the next steps:
- Launch the stack
vpc-mskserverless-clientutilizing the CloudFormation template:
- Present the parameter values as listed within the following desk.
| Parameters | Description | Pattern Worth |
EnvironmentName |
Atmosphere title that’s prefixed to useful resource names | . |
PrivateSubnet1CIDR |
IP vary (CIDR notation) for the non-public subnet within the first Availability Zone | . |
PrivateSubnet2CIDR |
IP vary (CIDR notation) for the non-public subnet within the second Availability Zone | . |
PublicSubnet1CIDR |
IP vary (CIDR notation) for the general public subnet within the first Availability Zone | . |
PublicSubnet2CIDR |
IP vary (CIDR notation) for the general public subnet within the second Availability Zone | . |
VpcCIDR |
IP vary (CIDR notation) for this VPC | . |
InstanceType |
Occasion sort for the EC2 occasion | t2.micro |
LatestAmiId |
AMI used for the EC2 occasion | /aws/service/ami-amazon-linux- newest/amzn2-ami-hvm-x86_64-gp2 |
- When the stack creation is full, retrieve the EC2 occasion PublicDNS from the
vpc-mskserverless-clientstack’s Outputs tab.
The stack creation course of can take round quarter-hour to finish.
- On the Amazon EC2 console, entry the EC2 occasion that you just created utilizing the CloudFormation template.
- Select the EC2 occasion whose
InstanceIdis proven on the stack’s Outputs tab.

Subsequent, you log in to the EC2 occasion utilizing Session Supervisor, a functionality of AWS Methods Supervisor.
- On the Amazon EC2 console, choose the
instanceidand on the Session Supervisor tab, select Join.

After you log in to the EC2 occasion, you create a Kafka matter within the MSK Serverless cluster from the EC2 occasion.
- Within the following export command, present the
MSKBootstrapServersworth from thevpc-mskserverless- consumerstack output to your endpoint: - Run the next command on the EC2 occasion to create a subject known as
msk-serverless-blog. The Kafka consumer is already put in within the ec2-user house listing (/house/ec2-user).
After you affirm the subject creation, you possibly can push the info to the MSK Serverless.
- Run the next command on the EC2 occasion to create a console producer to provide data to the Kafka matter. (For supply knowledge, we use
nycflights.csvdownloaded on the ec2-user house listing/house/ec2-user.)
Subsequent, you arrange the info processing service assets, particularly AWS Glue parts just like the database, desk, and streaming job to course of the info.
Create knowledge processing assets
The gluejob-setup.yaml CloudFormation template creates a database, desk, AWS Glue connection, and AWS Glue streaming job. Retrieve the values for VpcId, GluePrivateSubnet, GlueconnectionSubnetAZ, SecurityGroup, S3BucketForOutput, and S3BucketForGlueScript from the vpc-mskserverless-client stack’s Outputs tab to make use of on this template. Full the next steps:
- Launch the stack
gluejob-setup:
![]()
- Present parameter values as listed within the following desk.
| Parameters | Description | Pattern worth |
EnvironmentName |
Atmosphere title that’s prefixed to useful resource names. | Gluejob-setup |
VpcId |
ID of the VPC for safety group. Use the VPC ID created with the primary stack. | Check with the primary stack’s output. |
GluePrivateSubnet |
Personal subnet used for creating the AWS Glue connection. | Check with the primary stack’s output. |
SecurityGroupForGlueConnection |
Safety group utilized by the AWS Glue connection. | Check with the primary stack’s output. |
GlueconnectionSubnetAZ |
Availability Zone for the primary non-public subnet used for the AWS Glue connection. | . |
GlueDataBaseName |
Identify of the AWS Glue Information Catalog database. | glue_kafka_blog_db |
GlueTableName |
Identify of the AWS Glue Information Catalog desk. | blog_kafka_tbl |
S3BucketNameForScript |
Bucket Identify for Glue ETL script. | Use the S3 bucket title from the earlier stack. For instance, aws-gluescript-${AWS::AccountId}-${AWS::Area}-${EnvironmentName} |
GlueWorkerType |
Employee sort for AWS Glue job. For instance, G.1X. | G.1X |
NumberOfWorkers |
Variety of staff within the AWS Glue job. | 3 |
S3BucketNameForOutput |
Bucket title for writing knowledge from the AWS Glue job. | aws-glueoutput-${AWS::AccountId}-${AWS::Area}-${EnvironmentName} |
TopicName |
MSK matter title that must be processed. | msk-serverless-blog |
MSKBootstrapServers |
Kafka bootstrap server. | boot-30vvr5lg.c1.kafka-serverless.us- east-1.amazonaws.com:9098 |
The stack creation course of can take round 1–2 minutes to finish. You may examine the Outputs tab for the stack after the stack is created.

Within the gluejob-setup stack, we created a Kafka sort AWS Glue connection, which consists of dealer info just like the MSK bootstrap server, matter title, and VPC during which the MSK Serverless cluster is created. Most significantly, it specifies the IAM authentication possibility, which helps AWS Glue authenticate and authorize utilizing IAM authentication whereas consuming the info from the MSK matter. For additional readability, you possibly can look at the AWS Glue connection and the related AWS Glue desk generated via AWS CloudFormation.
After efficiently creating the CloudFormation stack, now you can proceed with processing knowledge utilizing the AWS Glue streaming job with IAM authentication.
Run the AWS Glue streaming job
To course of the info from the MSK matter utilizing the AWS Glue streaming job that you just arrange within the earlier part, full the next steps:
- On the CloudFormation console, select the stack
gluejob-setup. - On the Outputs tab, retrieve the title of the AWS Glue streaming job from the
GlueJobNamerow. Within the following screenshot, the title isGlueStreamingJob-glue-streaming-job.

- On the AWS Glue console, select ETL jobs within the navigation pane.
- Seek for the AWS Glue streaming job named
GlueStreamingJob-glue-streaming-job. - Select the job title to open its particulars web page.
- Select Run to start out the job.
- On the Runs tab, affirm if the job ran with out failure.

- Retrieve the
OutputBucketNamefrom thegluejob-setup templateoutputs. - On the Amazon S3 console, navigate to the S3 bucket to confirm the info.

- On the AWS Glue console, select the AWS Glue streaming job you ran, then select Cease job run.
As a result of this can be a streaming job, it would proceed to run indefinitely till manually stopped. After you confirm the info is current within the S3 output bucket, you possibly can cease the job to avoid wasting value.
Validate the info in Athena
After the AWS Glue streaming job has efficiently created the desk for the processed knowledge within the Information Catalog, comply with these steps to validate the info utilizing Athena:
- On the Athena console, navigate to the question editor.
- Select the Information Catalog as the info supply.
- Select the database and desk that the AWS Glue streaming job created.
- To validate the info, run the next question to seek out the flight quantity, origin, and vacation spot that coated the best distance in a 12 months:
The next screenshot reveals the output of our instance question.

Clear up
To wash up your assets, full the next steps:
- Delete the CloudFormation stack
gluejob-setup. - Delete the CloudFormation stack
vpc-mskserverless-client.
Conclusion
On this submit, we demonstrated a use case for constructing a serverless ETL pipeline for streaming with IAM authentication, which lets you concentrate on the outcomes of your analytics. You too can modify the AWS Glue streaming ETL code on this submit with transformations and mappings to make sure that solely legitimate knowledge will get loaded to Amazon S3. This answer allows you to harness the prowess of AWS Glue streaming, seamlessly built-in with MSK Serverless via the IAM authentication technique. It’s time to behave and revolutionize your streaming processes.
Appendix
This part supplies extra details about tips on how to create the AWS Glue connection on the AWS Glue console, which helps set up the connection to the MSK Serverless cluster and permit the AWS Glue streaming job to authenticate and authorize utilizing IAM authentication whereas consuming the info from the MSK matter.
- On the AWS Glue console, within the navigation pane, below Information catalog, select Connections.
- Select Create connection.
- For Connection title, enter a singular title to your connection.
- For Connection sort, select Kafka.
- For Connection entry, choose Amazon managed streaming for Apache Kafka (MSK).
- For Kafka bootstrap server URLs, enter a comma-separated listing of bootstrap server URLs. Embody the port quantity. For instance,
boot-xxxxxxxx.c2.kafka-serverless.us-east- 1.amazonaws.com:9098.

- For Authentication, select IAM Authentication.
- Choose Require SSL connection.
- For VPC, select the VPC that incorporates your knowledge supply.
- For Subnet, select the non-public subnet inside your VPC.
- For Safety teams, select a safety group to permit entry to the info retailer in your VPC subnet.
Safety teams are related to the ENI connected to your subnet. You should select no less than one safety group with a self-referencing inbound rule for all TCP ports.
- Select Save adjustments.

After you create the AWS Glue connection, you should utilize the AWS Glue streaming job to devour knowledge from the MSK matter utilizing IAM authentication.
In regards to the authors
 Shubham Purwar is a Cloud Engineer (ETL) at AWS Bengaluru specialised in AWS Glue and Amazon Athena. He’s obsessed with serving to prospects remedy points associated to their ETL workload and implement scalable knowledge processing and analytics pipelines on AWS. In his free time, Shubham likes to spend time together with his household and journey world wide.
Shubham Purwar is a Cloud Engineer (ETL) at AWS Bengaluru specialised in AWS Glue and Amazon Athena. He’s obsessed with serving to prospects remedy points associated to their ETL workload and implement scalable knowledge processing and analytics pipelines on AWS. In his free time, Shubham likes to spend time together with his household and journey world wide.
 Nitin Kumar is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He’s devoted to helping prospects in resolving points associated to their ETL workloads and creating scalable knowledge processing and analytics pipelines on AWS.
Nitin Kumar is a Cloud Engineer (ETL) at AWS with a specialization in AWS Glue. He’s devoted to helping prospects in resolving points associated to their ETL workloads and creating scalable knowledge processing and analytics pipelines on AWS.
[ad_2]