
[ad_1]
This put up is co-written with Karthik Kondamudi and Jenny Thompson from Sew Repair.
Sew Repair is a personalised clothes styling service for males, ladies, and children. At Sew Repair, we’ve got been powered by knowledge science since its basis and depend on many trendy knowledge lake and knowledge processing applied sciences. In our infrastructure, Apache Kafka has emerged as a robust instrument for managing occasion streams and facilitating real-time knowledge processing. At Sew Repair, we’ve got used Kafka extensively as a part of our knowledge infrastructure to assist numerous wants throughout the enterprise for over six years. Kafka performs a central position within the Sew Repair efforts to overtake its occasion supply infrastructure and construct a self-service knowledge integration platform.
Should you’d wish to know extra background about how we use Kafka at Sew Repair, please check with our beforehand revealed weblog put up, Placing the Energy of Kafka into the Palms of Knowledge Scientists. This put up contains way more info on enterprise use circumstances, structure diagrams, and technical infrastructure.
On this put up, we are going to describe how and why we determined emigrate from self-managed Kafka to Amazon Managed Streaming for Apache Kafka (Amazon MSK). We’ll begin with an outline of our self-managed Kafka, why we selected emigrate to Amazon MSK, and in the end how we did it.
- Kafka clusters overview
- Why migrate to Amazon MSK
- How we migrated to Amazon MSK
- Navigating challenges and classes realized
- Conclusion
Kafka Clusters Overview
At Sew Repair, we depend on a number of completely different Kafka clusters devoted to particular functions. This enables us to scale these clusters independently and apply extra stringent SLAs and message supply ensures per cluster. This additionally reduces general threat by minimizing the impression of modifications and upgrades and permits us to isolate and repair any points that happen inside a single cluster.
Our essential Kafka cluster serves because the spine of our knowledge infrastructure. It handles a mess of crucial capabilities, together with managing enterprise occasions, facilitating microservice communication, supporting characteristic technology for machine studying workflows, and way more. The steadiness, reliability, and efficiency of this cluster are of utmost significance to our operations.
Our logging cluster performs an important position in our knowledge infrastructure. It serves as a centralized repository for numerous utility logs, together with internet server logs and Nginx server logs. These logs present helpful insights for monitoring and troubleshooting functions. The logging cluster ensures easy operations and environment friendly evaluation of log knowledge.
Why migrate to Amazon MSK
Prior to now six years, our knowledge infrastructure crew has diligently managed our Kafka clusters. Whereas our crew has acquired intensive information in sustaining Kafka, we’ve got additionally confronted challenges similar to rolling deployments for model upgrades, making use of OS patches, and the general operational overhead.
At Sew Repair, our engineers thrive on creating new options and increasing our service choices to please our clients. Nonetheless, we acknowledged that allocating important sources to Kafka upkeep was taking away treasured time from innovation. To beat this problem, we got down to discover a managed service supplier that might deal with upkeep duties like upgrades and patching whereas granting us full management over cluster operations, together with partition administration and rebalancing. We additionally sought an easy scaling resolution for storage volumes, maintaining our prices in test whereas being able to accommodate future progress.
After thorough analysis of a number of choices, we discovered the proper match in Amazon MSK as a result of it permits us to dump cluster upkeep to the extremely expert Amazon engineers. With Amazon MSK in place, our groups can now focus their vitality on creating modern purposes distinctive and helpful to Sew Repair, as a substitute of getting caught up in Kafka administration duties.
Amazon MSK streamlines the method, eliminating the necessity for handbook configurations, extra software program installations, and worries about scaling. It merely works, enabling us to focus on delivering distinctive worth to our cherished clients.
How we migrated to Amazon MSK
Whereas planning our migration, we desired to change particular companies to Amazon MSK individually with no downtime, guaranteeing that solely a selected subset of companies could be migrated at a time. The general infrastructure would run in a hybrid atmosphere the place some companies hook up with Amazon MSK and others to the prevailing Kafka infrastructure.
We determined to start out the migration with our much less crucial logging cluster first after which proceed to migrating the principle cluster. Though the logs are important for monitoring and troubleshooting functions, they maintain comparatively much less significance to the core enterprise operations. Moreover, the quantity and forms of shoppers and producers for the logging cluster is smaller, making it a better alternative to start out with. Then, we have been in a position to apply our learnings from the logging cluster migration to the principle cluster. This deliberate alternative enabled us to execute the migration course of in a managed method, minimizing any potential disruptions to our crucial methods.
Over time, our skilled knowledge infrastructure crew has employed Apache Kafka MirrorMaker 2 (MM2) to duplicate knowledge between completely different Kafka clusters. At present, we depend on MM2 to duplicate knowledge from two completely different manufacturing Kafka clusters. Given its confirmed monitor document inside our group, we determined to make use of MM2 as the first instrument for our knowledge migration course of.
The final steerage for MM2 is as follows:
- Start with much less crucial purposes.
- Carry out lively migrations.
- Familiarize your self with key greatest practices for MM2.
- Implement monitoring to validate the migration.
- Accumulate important insights for migrating different purposes.
MM2 gives versatile deployment choices, permitting it to operate as a standalone cluster or be embedded inside an current Kafka Join cluster. For our migration undertaking, we deployed a devoted Kafka Join cluster working in distributed mode.
This setup offered the scalability we wanted, permitting us to simply develop the standalone cluster if essential. Relying on particular use circumstances similar to geoproximity, excessive availability (HA), or migrations, MM2 could be configured for active-active replication, active-passive replication, or each. In our case, as we migrated from self-managed Kafka to Amazon MSK, we opted for an active-passive configuration, the place MirrorMaker was used for migration functions and subsequently taken offline upon completion.
MirrorMaker configuration and replication coverage
By default, MirrorMaker renames replication subjects by prefixing the title of the supply Kafka cluster to the vacation spot cluster. As an illustration, if we replicate matter A from the supply cluster “current” to the brand new cluster “newkafka,” the replicated matter could be named “current.A” in “newkafka.” Nonetheless, this default habits could be modified to take care of constant matter names inside the newly created MSK cluster.
To take care of constant matter names within the newly created MSK cluster and keep away from downstream points, we utilized the CustomReplicationPolicy jar offered by AWS. This jar, included in our MirrorMaker setup, allowed us to duplicate subjects with similar names within the MSK cluster. Moreover, we utilized MirrorCheckpointConnector to synchronize shopper offsets from the supply cluster to the goal cluster and MirrorHeartbeatConnector to make sure connectivity between the clusters.
Monitoring and metrics
MirrorMaker comes outfitted with built-in metrics to observe replication lag and different important parameters. We built-in these metrics into our MirrorMaker setup, exporting them to Grafana for visualization. Since we’ve got been utilizing Grafana to observe different methods, we determined to make use of it throughout migration as effectively. This enabled us to intently monitor the replication standing in the course of the migration course of. The precise metrics we monitored will probably be described in additional element beneath.
Moreover, we monitored the MirrorCheckpointConnector included with MirrorMaker, because it periodically emits checkpoints within the vacation spot cluster. These checkpoints contained offsets for every shopper group within the supply cluster, guaranteeing seamless synchronization between the clusters.
Community format
At Sew Repair, we use a number of digital personal clouds (VPCs) by means of Amazon Digital Personal Cloud (Amazon VPC) for atmosphere isolation in every of our AWS accounts. We’ve got been utilizing separate manufacturing and staging VPCs since we initially began utilizing AWS. When essential, peering of VPCs throughout accounts is dealt with by means of AWS Transit Gateway. To take care of the sturdy isolation between environments we’ve got been utilizing all alongside, we created separate MSK clusters of their respective VPCs for manufacturing and staging environments.
Facet observe: It is going to be simpler now to shortly join Kafka purchasers hosted in numerous digital personal clouds with just lately introduced Amazon MSK multi-VPC personal connectivity, which was not out there on the time of our migration.
Migration steps: Excessive-level overview
On this part, we define the high-level sequence of occasions for the migration course of.
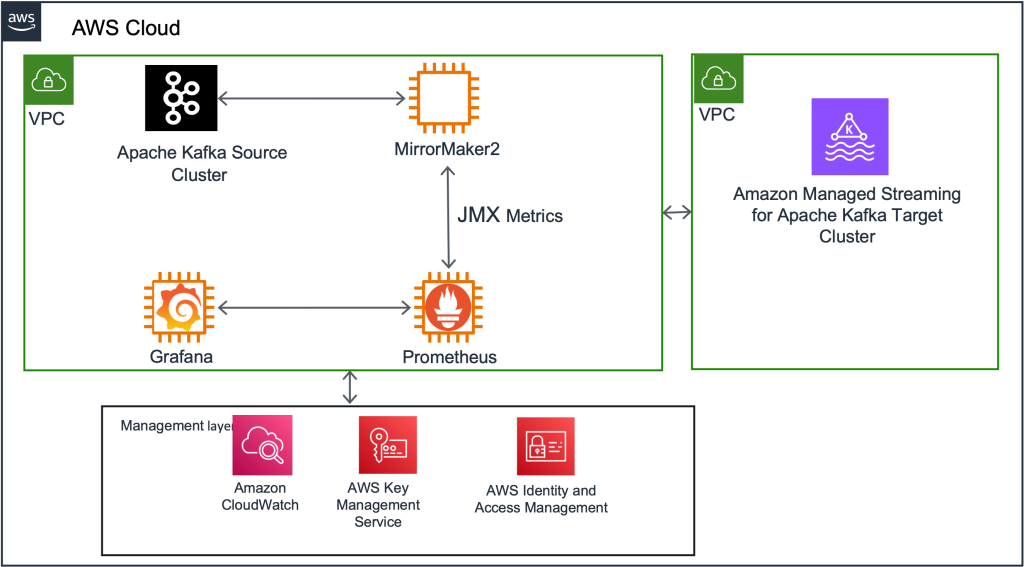
Kafka Join setup and MM2 deploy
First, we deployed a brand new Kafka Join cluster on an Amazon Elastic Compute Cloud (Amazon EC2) cluster as an middleman between the prevailing Kafka cluster and the brand new MSK cluster. Subsequent, we deployed the three MirrorMaker connectors to this Kafka Join cluster. Initially, this cluster was configured to reflect all the prevailing subjects and their configurations into the vacation spot MSK cluster. (We ultimately modified this configuration to be extra granular, as described within the “Navigating challenges and classes realized” part beneath.)
Monitor replication progress with MM metrics
Make the most of the JMX metrics supplied by MirrorMaker to observe the progress of information replication. Along with complete metrics, we primarily centered on key metrics, specifically replication-latency-ms and checkpoint-latency-ms. These metrics present invaluable insights into the replication standing, together with essential elements similar to replication lag and checkpoint latency. By seamlessly exporting these metrics to Grafana, you acquire the flexibility to visualise and intently monitor the progress of replication, guaranteeing the profitable replica of each historic and new knowledge by MirrorMaker.
Consider utilization metrics and provisioning
Analyze the utilization metrics of the brand new MSK cluster to make sure correct provisioning. Think about components similar to storage, throughput, and efficiency. If required, resize the cluster to satisfy the noticed utilization patterns. Whereas resizing might introduce extra time to the migration course of, it’s a cost-effective measure in the long term.
Sync shopper offsets between supply and goal clusters
Make sure that shopper offsets are synchronized between the supply in-house clusters and the goal MSK clusters. As soon as the buyer offsets are in sync, redirect the shoppers of the prevailing in-house clusters to devour knowledge from the brand new MSK cluster. This step ensures a seamless transition for shoppers and permits uninterrupted knowledge movement in the course of the migration.
Replace producer purposes
After confirming that every one shoppers are efficiently consuming knowledge from the brand new MSK cluster, replace the producer purposes to write down knowledge on to the brand new cluster. This ultimate step completes the migration course of, guaranteeing that every one knowledge is now being written to the brand new MSK cluster and taking full benefit of its capabilities.
Navigating challenges and classes realized
Throughout our migration, we encountered three challenges that required cautious consideration: scalable storage, extra granular configuration of replication configuration, and reminiscence allocation.
Initially, we confronted points with auto scaling Amazon MSK storage. We realized storage auto scaling requires a 24-hour cool-off interval earlier than one other scaling occasion can happen. We noticed this when migrating the logging cluster, and we utilized our learnings from this and factored within the cool-off interval throughout manufacturing cluster migration.
Moreover, to optimize MirrorMaker replication velocity, we up to date the unique configuration to divide the replication jobs into batches primarily based on quantity and allotted extra duties to high-volume subjects.
Through the preliminary part, we initiated replication utilizing a single connector to switch all subjects from the supply to focus on clusters, encompassing a big variety of duties. Nonetheless, we encountered challenges similar to rising replication lag for high-volume subjects and slower replication for particular subjects. Upon cautious examination of the metrics, we adopted another method by segregating high-volume subjects into a number of connectors. In essence, we divided the subjects into classes of excessive, medium, and low volumes, assigning them to respective connectors and adjusting the variety of duties primarily based on replication latency. This strategic adjustment yielded constructive outcomes, permitting us to attain sooner and extra environment friendly knowledge replication throughout the board.
Lastly, we encountered Java digital machine heap reminiscence exhaustion, leading to lacking metrics whereas operating MirrorMaker replication. To handle this, we elevated reminiscence allocation and restarted the MirrorMaker course of.
Conclusion
Sew Repair’s migration from self-managed Kafka to Amazon MSK has allowed us to shift our focus from upkeep duties to delivering worth for our clients. It has decreased our infrastructure prices by 40 p.c and given us the arrogance that we are able to simply scale the clusters sooner or later if wanted. By strategically planning the migration and utilizing Apache Kafka MirrorMaker, we achieved a seamless transition whereas guaranteeing excessive availability. The mixing of monitoring and metrics offered helpful insights in the course of the migration course of, and Sew Repair efficiently navigated challenges alongside the way in which. The migration to Amazon MSK has empowered Sew Repair to maximise the capabilities of Kafka whereas benefiting from the experience of Amazon engineers, setting the stage for continued progress and innovation.
Additional studying
In regards to the Authors
 Karthik Kondamudi is an Engineering Supervisor within the Knowledge and ML Platform Group at StitchFix. His pursuits lie in Distributed Methods and large-scale knowledge processing. Past work, he enjoys spending time with household and mountain climbing. A canine lover, he’s additionally obsessed with sports activities, notably cricket, tennis, and soccer.
Karthik Kondamudi is an Engineering Supervisor within the Knowledge and ML Platform Group at StitchFix. His pursuits lie in Distributed Methods and large-scale knowledge processing. Past work, he enjoys spending time with household and mountain climbing. A canine lover, he’s additionally obsessed with sports activities, notably cricket, tennis, and soccer.
 Jenny Thompson is a Knowledge Platform Engineer at Sew Repair. She works on a wide range of methods for Knowledge Scientists, and enjoys making issues clear, easy, and simple to make use of. She additionally likes making pancakes and Pavlova, shopping for furnishings on Craigslist, and getting rained on throughout picnics.
Jenny Thompson is a Knowledge Platform Engineer at Sew Repair. She works on a wide range of methods for Knowledge Scientists, and enjoys making issues clear, easy, and simple to make use of. She additionally likes making pancakes and Pavlova, shopping for furnishings on Craigslist, and getting rained on throughout picnics.
 Rahul Nammireddy is a Senior Options Architect at AWS, focusses on guiding digital native clients by means of their cloud native transformation. With a ardour for AI/ML applied sciences, he works with clients in industries similar to retail and telecom, serving to them innovate at a speedy tempo. All through his 23+ years profession, Rahul has held key technical management roles in a various vary of corporations, from startups to publicly listed organizations, showcasing his experience as a builder and driving innovation. In his spare time, he enjoys watching soccer and enjoying cricket.
Rahul Nammireddy is a Senior Options Architect at AWS, focusses on guiding digital native clients by means of their cloud native transformation. With a ardour for AI/ML applied sciences, he works with clients in industries similar to retail and telecom, serving to them innovate at a speedy tempo. All through his 23+ years profession, Rahul has held key technical management roles in a various vary of corporations, from startups to publicly listed organizations, showcasing his experience as a builder and driving innovation. In his spare time, he enjoys watching soccer and enjoying cricket.
 Todd McGrath is an information streaming specialist at Amazon Internet Providers the place he advises clients on their streaming methods, integration, structure, and options. On the private facet, he enjoys watching and supporting his 3 youngsters of their most well-liked actions in addition to following his personal pursuits similar to fishing, pickleball, ice hockey, and joyful hour with family and friends on pontoon boats. Join with him on LinkedIn.
Todd McGrath is an information streaming specialist at Amazon Internet Providers the place he advises clients on their streaming methods, integration, structure, and options. On the private facet, he enjoys watching and supporting his 3 youngsters of their most well-liked actions in addition to following his personal pursuits similar to fishing, pickleball, ice hockey, and joyful hour with family and friends on pontoon boats. Join with him on LinkedIn.
[ad_2]