
[ad_1]
It’s no secret that OpenAI’s ChatGPT has some unimaginable capabilities — as an illustration, the chatbot can write poetry that resembles Shakespearean sonnets or debug code for a pc program. These talents are made doable by the large machine-learning mannequin that ChatGPT is constructed upon. Researchers have discovered that when some of these fashions turn into giant sufficient, extraordinary capabilities emerge.
However greater fashions additionally require extra money and time to coach. The coaching course of includes displaying a whole bunch of billions of examples to a mannequin. Gathering a lot knowledge is an concerned course of in itself. Then come the financial and environmental prices of working many highly effective computer systems for days or perhaps weeks to coach a mannequin which will have billions of parameters.
“It’s been estimated that coaching fashions on the scale of what ChatGPT is hypothesized to run on might take hundreds of thousands of {dollars}, only for a single coaching run. Can we enhance the effectivity of those coaching strategies, so we will nonetheless get good fashions in much less time and for much less cash? We suggest to do that by leveraging smaller language fashions which have beforehand been skilled,” says Yoon Kim, an assistant professor in MIT’s Division of Electrical Engineering and Laptop Science and a member of the Laptop Science and Synthetic Intelligence Laboratory (CSAIL).
Moderately than discarding a earlier model of a mannequin, Kim and his collaborators use it because the constructing blocks for a brand new mannequin. Utilizing machine studying, their methodology learns to “develop” a bigger mannequin from a smaller mannequin in a approach that encodes data the smaller mannequin has already gained. This permits quicker coaching of the bigger mannequin.
Their method saves about 50 % of the computational price required to coach a big mannequin, in comparison with strategies that prepare a brand new mannequin from scratch. Plus, the fashions skilled utilizing the MIT methodology carried out in addition to, or higher than, fashions skilled with different methods that additionally use smaller fashions to allow quicker coaching of bigger fashions.
Lowering the time it takes to coach large fashions might assist researchers make developments quicker with much less expense, whereas additionally lowering the carbon emissions generated throughout the coaching course of. It might additionally allow smaller analysis teams to work with these large fashions, doubtlessly opening the door to many new advances.
“As we glance to democratize some of these applied sciences, making coaching quicker and cheaper will turn into extra necessary,” says Kim, senior writer of a paper on this method.
Kim and his graduate pupil Lucas Torroba Hennigen wrote the paper with lead writer Peihao Wang, a graduate pupil on the College of Texas at Austin, in addition to others on the MIT-IBM Watson AI Lab and Columbia College. The analysis might be introduced on the Worldwide Convention on Studying Representations.
The larger the higher
Massive language fashions like GPT-3, which is on the core of ChatGPT, are constructed utilizing a neural community structure referred to as a transformer. A neural community, loosely primarily based on the human mind, consists of layers of interconnected nodes, or “neurons.” Every neuron accommodates parameters, that are variables discovered throughout the coaching course of that the neuron makes use of to course of knowledge.
Transformer architectures are distinctive as a result of, as some of these neural community fashions get greater, they obtain a lot better outcomes.
“This has led to an arms race of corporations making an attempt to coach bigger and bigger transformers on bigger and bigger datasets. Extra so than different architectures, evidently transformer networks get a lot better with scaling. We’re simply not precisely certain why that is the case,” Kim says.
These fashions typically have a whole bunch of hundreds of thousands or billions of learnable parameters. Coaching all these parameters from scratch is dear, so researchers search to speed up the method.
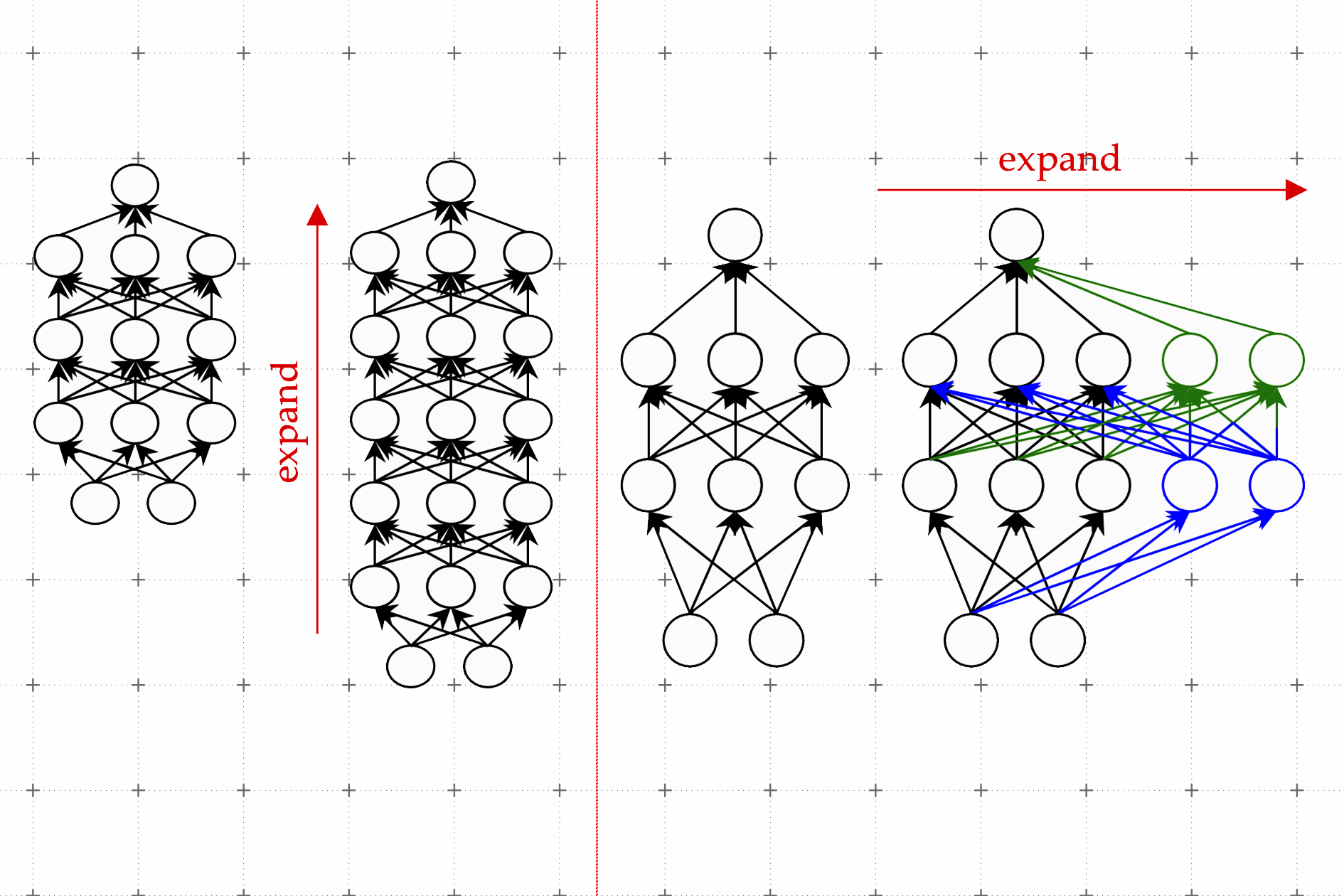
One efficient method is named mannequin progress. Utilizing the mannequin progress methodology, researchers can enhance the scale of a transformer by copying neurons, and even complete layers of a earlier model of the community, then stacking them on prime. They’ll make a community wider by including new neurons to a layer or make it deeper by including further layers of neurons.
In distinction to earlier approaches for mannequin progress, parameters related to the brand new neurons within the expanded transformer will not be simply copies of the smaller community’s parameters, Kim explains. Moderately, they’re discovered combos of the parameters of the smaller mannequin.
Studying to develop
Kim and his collaborators use machine studying to be taught a linear mapping of the parameters of the smaller mannequin. This linear map is a mathematical operation that transforms a set of enter values, on this case the smaller mannequin’s parameters, to a set of output values, on this case the parameters of the bigger mannequin.
Their methodology, which they name a discovered Linear Development Operator (LiGO), learns to develop the width and depth of bigger community from the parameters of a smaller community in a data-driven approach.
However the smaller mannequin may very well be fairly giant — maybe it has 100 million parameters — and researchers may need to make a mannequin with a billion parameters. So the LiGO method breaks the linear map into smaller items {that a} machine-learning algorithm can deal with.
LiGO additionally expands width and depth concurrently, which makes it extra environment friendly than different strategies. A consumer can tune how extensive and deep they need the bigger mannequin to be once they enter the smaller mannequin and its parameters, Kim explains.
Once they in contrast their method to the method of coaching a brand new mannequin from scratch, in addition to to model-growth strategies, it was quicker than all of the baselines. Their methodology saves about 50 % of the computational prices required to coach each imaginative and prescient and language fashions, whereas typically enhancing efficiency.
The researchers additionally discovered they may use LiGO to speed up transformer coaching even once they didn’t have entry to a smaller, pretrained mannequin.
“I used to be stunned by how a lot better all of the strategies, together with ours, did in comparison with the random initialization, train-from-scratch baselines.” Kim says.
Sooner or later, Kim and his collaborators are trying ahead to making use of LiGO to even bigger fashions.
The work was funded, partially, by the MIT-IBM Watson AI Lab, Amazon, the IBM Analysis AI {Hardware} Heart, Heart for Computational Innovation at Rensselaer Polytechnic Institute, and the U.S. Military Analysis Workplace.
[ad_2]