
[ad_1]
We’re excited to announce that assist for utilizing Structured Streaming with Delta Sharing is now typically accessible (GA) in Azure, AWS, and GCP! This new characteristic will enable knowledge recipients on the Databricks Lakehouse Platform to stream modifications from a Delta Desk shared by the Unity Catalog.
Knowledge suppliers can leverage this functionality to scale their data-as-a-service simply, scale back the operational value of sharing giant knowledge units, enhance knowledge high quality with instant knowledge validation and high quality checks as new knowledge arrives, and enhance customer support with real-time knowledge supply. Equally, knowledge recipients can stream the newest modifications from a shared dataset, lowering the infrastructure value of processing giant batch knowledge and setting the muse for cutting-edge, real-time knowledge functions. Knowledge recipients throughout many trade verticals can profit from this new characteristic, for instance:
- Retail: Knowledge analysts can stream the newest gross sales figures for a seasonal vogue line and current enterprise insights within the type of a BI report.
- Well being Life Sciences: Well being practitioners can stream electrocardiogram readings into an ML mannequin to determine abnormalities.
- Manufacturing: Constructing administration groups can stream good thermostat readings and determine what time of day or evening heating and cooling items ought to effectively activate or off.
Oftentimes, knowledge groups rely on knowledge pipelines executed in a batch vogue to course of their knowledge attributable to the truth that batch execution is each strong and straightforward to implement. Nevertheless, right this moment, organizations want the newest arriving knowledge to make real-time enterprise selections. Structured streaming not solely simplifies real-time processing but in addition simplifies batch processing by lowering the variety of batch jobs to only a few streaming jobs. Changing batch knowledge pipelines to streaming is trivial as Structured Streaming helps the identical DataFrame API.
On this weblog article, we’ll discover how enterprises can leverage Structured Streaming with Delta Sharing to maximise the enterprise worth of their knowledge in close to real-time utilizing an instance within the monetary trade. We’ll additionally look at how different complementary options, like Databricks Workflows, can be utilized at the side of Delta Sharing and Unity Catalog to construct a real-time knowledge software.
Help for Structured Streaming
Maybe essentially the most extremely anticipated Delta Sharing characteristic over the previous few months has been added assist for utilizing a shared Delta Desk as a supply in Structured Streaming. This new characteristic will enable knowledge recipients to construct real-time functions utilizing Delta Tables shared by Unity Catalog on the Databricks Lakehouse Platform.
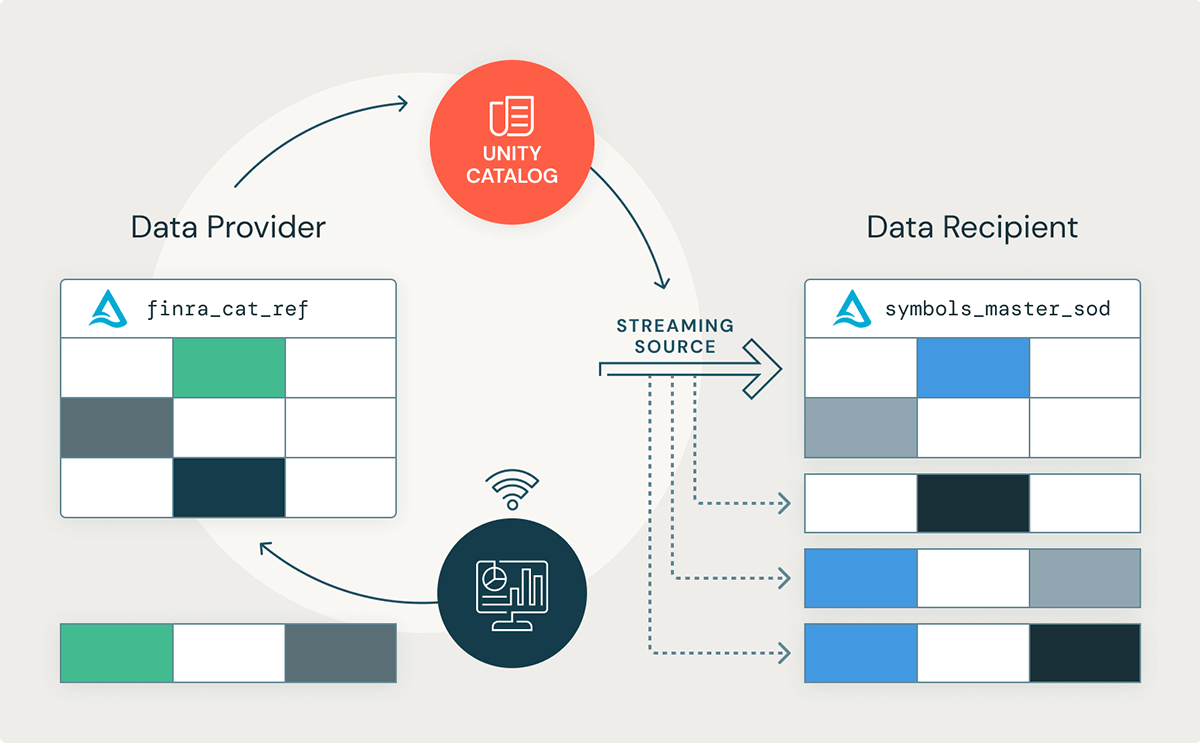
Learn how to Use Delta Sharing with Structured Streaming
Let’s take a better have a look at how a knowledge recipient would possibly stream publicly traded inventory image info for real-time buying and selling insights. This text will use the FINRA CAT Reportable Fairness Securities Image Grasp dataset, which lists all shares and fairness securities traded throughout the U.S. Nationwide Market System (NMS). Structured Streaming can be utilized to construct real-time functions, but it surely can be helpful in situations the place knowledge arrives much less ceaselessly. For a easy pocket book demonstration, we’ll use a dataset that’s up to date 3 times all through the day – as soon as initially of the transaction date (SOD), a second time through the day to mirror any intraday modifications, and a 3rd time on the finish of the transaction date (EOD). There are not any updates printed on weekends or on U.S. holidays.
| Printed File | Schedule |
|---|---|
| CAT Reportable Fairness Securities Image Grasp – SOD | 6:00 a.m. EST |
| CAT Reportable Choices Securities Image Grasp – SOD | 6:00 a.m. EST |
| Member ID (IMID) Record | 6:00 a.m. EST |
| Member ID (IMID) Conflicts Record | 6:00 a.m. EST |
| CAT Reportable Fairness Securities Image Grasp – Intraday | 10:30 a.m. EST, and roughly each 2 hours till EOD file is printed |
| CAT Reportable Choices Securities Image Grasp – Intraday | 10:30 a.m. EST, and roughly each 2 hours till EOD file is printed |
| CAT Reportable Fairness Securities Image Grasp – EOD | 8 p.m. EST |
| CAT Reportable Choices Securities Image Grasp – EOD | 8 p.m. EST |
Desk 1.1 – The FINRA CAT image and member reference knowledge is printed all through the enterprise day. There are not any updates printed on weekends or on U.S. holidays.
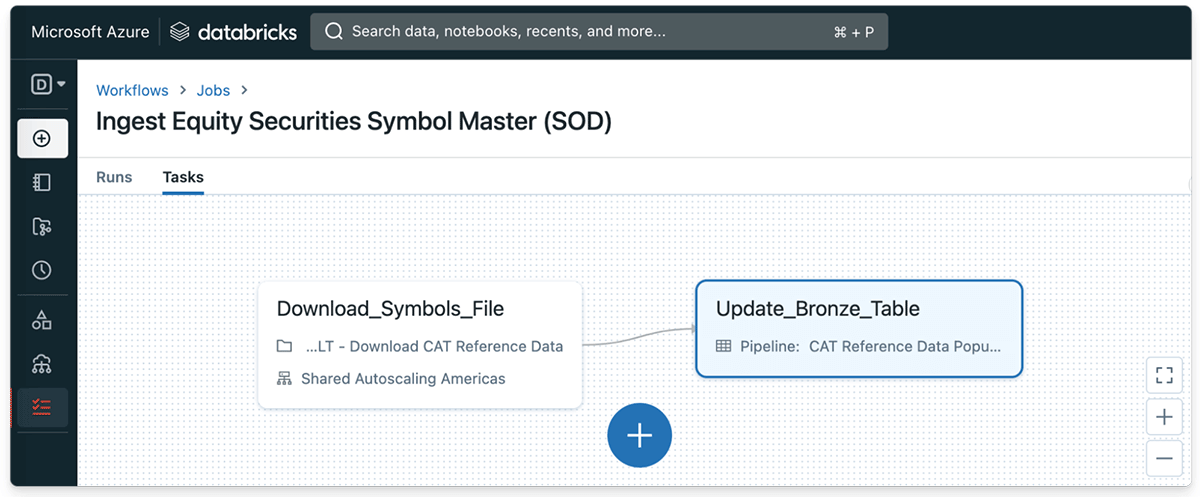
From Knowledge Supplier’s Perspective: Ingesting the CAT Knowledge utilizing Databricks Workflows
One of many main advantages of the Databricks Lakehouse Platform is that it makes repeatedly streaming modifications right into a Delta Desk extraordinarily simple. We’ll first begin by defining a easy Python activity that downloads the FINRA CAT fairness securities image file initially of the transaction date (SOD). Afterward, we’ll save the printed file to a brief listing on the Databricks filesystem.
# First, we'll obtain the FINRA CAT Fairness Securities Symbols file for right this moment's Begin of Day
request = requests.get(catReferenceDataURL, stream=True, allow_redirects=True)
# Subsequent, save the printed file to a temp listing on the Databricks filesystem
with open(dbfsPath, "wb") as binary_file:
for chunk in request.iter_content(chunk_size=2048):
if chunk:
binary_file.write(chunk)
binary_file.flush()
Code 1.1. – A easy Python activity can obtain the FINRA CAT fairness image file initially of the buying and selling day.
To display, we’ll additionally outline a operate that may ingest the uncooked file and repeatedly replace a bronze desk in our Delta Lake every time an up to date file is printed.
# Lastly, we'll ingest the newest fairness symbols CSV file right into a "bronze" Delta desk
def load_CAT_reference_data():
return (
spark.learn.choice("header", "true")
.schema(catEquitySymbolsMasterSchema)
.choice("delimiter", "|")
.format("csv")
.load(localFilePath)
.withColumn("catReferenceDataType", lit("FINRACATReportableEquitySecurities_SOD"))
.withColumn("currentDate", current_date())
.withColumn("currentTimestamp", current_timestamp())
.withColumn("compositeKey", concat_ws(".", "image", "listingExchange"))
)
Code. 1.2 – The FINRA CAT fairness image knowledge is ingested right into a Delta Desk initially of every buying and selling day.
As soon as it’s began, the Databricks Workflow will start populating the CAT fairness symbols dataset every time the file is printed initially of the buying and selling day.
From Knowledge Supplier’s Perspective: Sharing a Delta Desk as a Streaming Supply
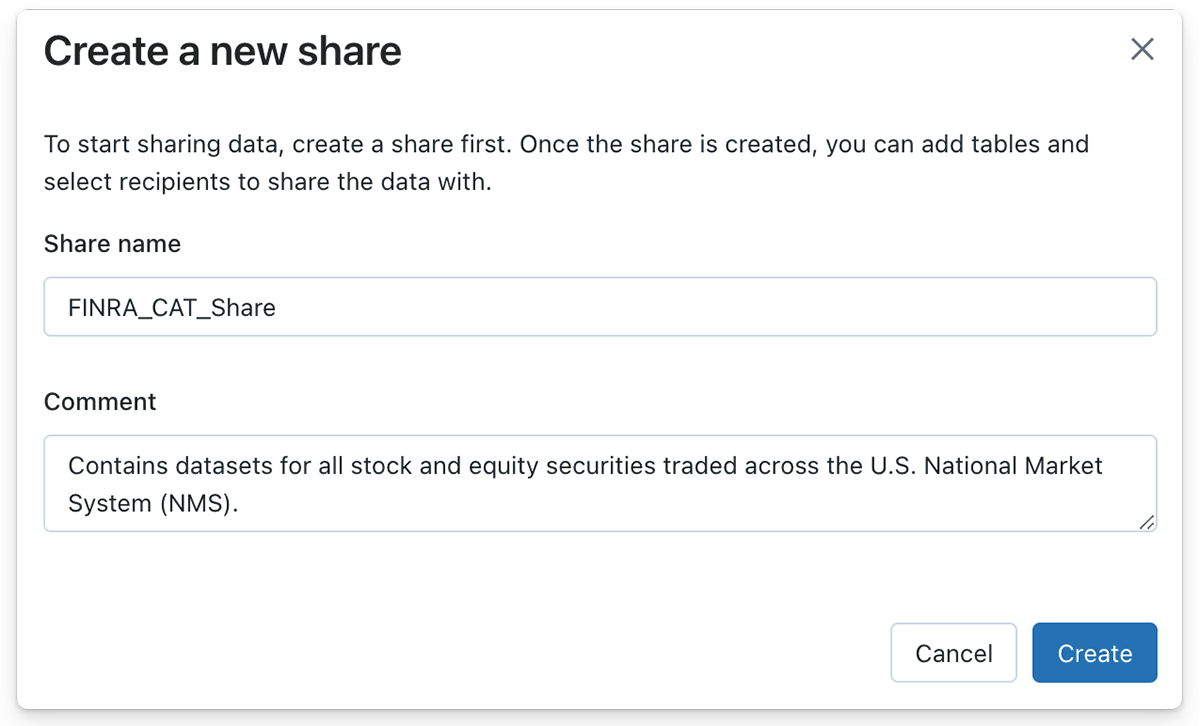
Now that we have created a streaming pipeline to ingest updates to the image file every buying and selling day, we will leverage Delta Sharing to share the Delta Desk with knowledge recipients. Making a Delta Share on the Databricks Lakehouse Platform will be carried out with only a few clicks of the button or with a single SQL assertion if SQL syntax is most popular.
Equally, a knowledge supplier can populate a Delta Share with a number of tables by clicking the ‘Handle property‘ button, adopted by the ‘Edit tables‘ button. On this case, the bronze Delta Desk containing the fairness image knowledge is added to the Share object.
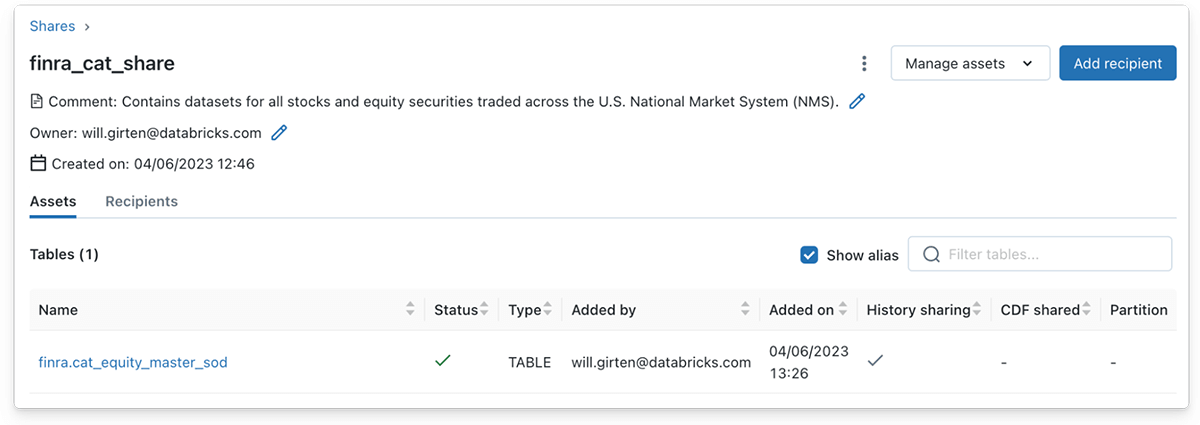
Notice that the complete historical past of a Delta desk have to be shared to assist reads utilizing Structured Streaming. Historical past sharing is enabled by default utilizing the Databricks UI so as to add a Delta desk to a Share. Nevertheless, historical past sharing have to be explicitly specified when utilizing the SQL syntax.
/**
A Delta desk have to be shared with historical past with a purpose to assist
Spark Structured Stream reads.
*/
ALTER SHARE finra_cat_share
ADD TABLE finance_catalog.finra.symbols_master
WITH HISTORY;
Code 1.4 – The historical past of a Delta desk have to be explicitly shared to assist Structured Streaming reads when utilizing the SQL syntax.
From Knowledge Recipient’s Perspective: Streaming a Shared Delta Desk
As a knowledge recipient, streaming from a shared Delta desk is simply as easy! After the Delta Share has been shared with a knowledge recipient, the recipient will instantly see the Share seem beneath the supplier particulars in Unity Catalog. Subsequently, the information recipient can create a brand new catalog in Unity Catalog by clicking the ‘Create catalog‘ button, offering a significant identify, and including an non-obligatory remark to explain the Share contents.
Knowledge recipients can stream from a Delta Desk shared by Unity Catalog utilizing Databricks Runtime 12.1 or better. On this instance, we have used a Databricks cluster with Databricks 12.2 LTS Runtime put in. A knowledge recipient can learn the shared Delta desk as a Spark Structured Stream utilizing the deltaSharing knowledge supply and supplying the identify of the shared desk.
# Stream from the shared Delta desk that is been created with a brand new Catalog in Unity Catalog
equity_master_stream = (spark.readStream
.format('deltaSharing')
.desk('finra_cat_catalog.finra.cat_equity_master'))
equity_master_stream.show()
Code 1.4 – A knowledge recipient can stream from a shared Delta Desk utilizing the deltaSharing knowledge supply.
As an additional instance, let’s mix the shared CAT fairness symbols grasp dataset with a inventory worth historical past dataset, native to the information recipient’s Unity Catalog. We’ll start by defining a utility operate for getting the weekly inventory worth histories of a given inventory ticker image.
import yfinance as yf
import pyspark.sql.capabilities as F
def get_weekly_stock_prices(image: str):
""" Scrapes the inventory worth historical past of a ticker image over the past 1 week.
arguments:
image (String) - The goal inventory image, usually a 3-4 letter abbreviation.
returns:
(Spark DataFrame) - The present worth of the offered ticker image.
"""
ticker = yf.Ticker(image)
# Retrieve the final recorded inventory worth within the final week
current_stock_price = ticker.historical past(interval="1wk")
# Convert to a Spark DataFrame
df = spark.createDataFrame(current_stock_price)
# Choose solely columns related to inventory worth and add an occasion processing timestamp
event_ts = str(current_stock_price.index[0])
df = (df.withColumn("Event_Ts", F.lit(event_ts))
.withColumn("Image", F.lit(image))
.choose(
F.col("Image"), F.col("Open"), F.col("Excessive"), F.col("Low"), F.col("Shut"),
F.col("Quantity"), F.col("Event_Ts").forged("timestamp"))
)
# Return the newest worth info
return df
Subsequent, we’ll be a part of collectively the fairness inventory grasp knowledge stream with the native inventory worth histories of three giant tech shares – Apple Inc. (AAPL), the Microsoft Company (MSFT), and the Invidia Company (NVDA).
# Seize the weekly worth histories for 3 main tech shares
aapl_stock_prices = get_weekly_stock_prices('AAPL')
msft_stock_prices = get_weekly_stock_prices('MSFT')
nvidia_stock_prices = get_weekly_stock_prices('NVDA')
all_stock_prices = aapl_stock_prices.union(msft_stock_prices).union(nvidia_stock_prices)
# Be part of the inventory worth histories with the fairness symbols grasp stream
symbols_master = spark.readStream.format('deltaSharing').desk('finra_catalog.finra.cat_equity_master')
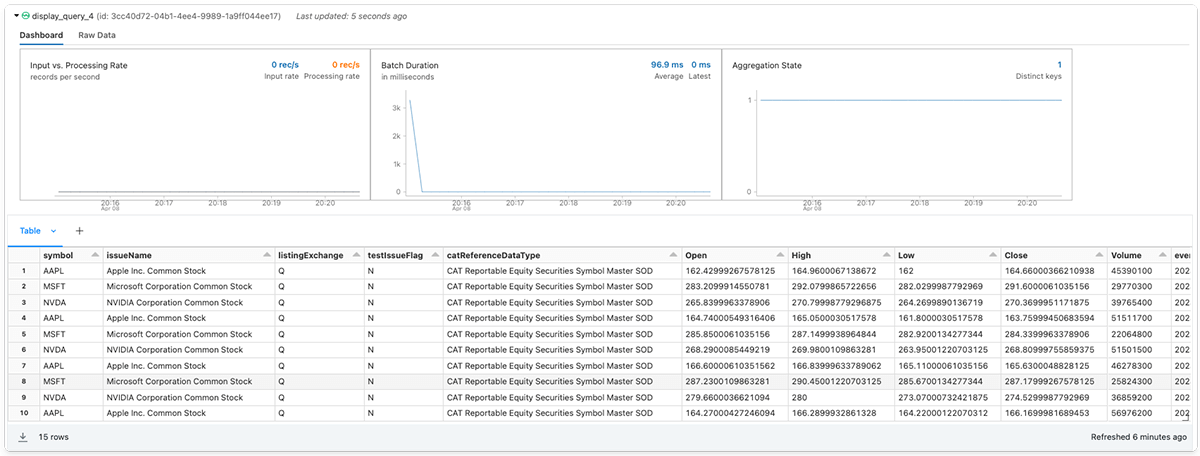
(symbols_master.be a part of(all_stock_prices, on="image", how="internal")
.choose("image", "issueName", "listingExchange", "testIssueFlag", "catReferenceDataType",
"Open", "Excessive", "Low", "Shut", "Quantity", "event_ts")
).show()
Lastly, the information recipient can add an non-obligatory vacation spot sink and begin the streaming question.
Getting Began with Delta Sharing on Databricks
I hope you loved this instance of how organizations can leverage Delta Sharing to maximise the enterprise worth of their knowledge in close to real-time.
Need to get began with Delta Sharing however do not know the place to start out? When you already are a Databricks buyer, comply with the information to get began utilizing Delta Sharing (AWS | Azure | GCP). Learn the documentation to be taught extra concerning the configuration choices included in with characteristic. If you’re not an current Databricks buyer, join a free trial with a Premium or Enterprise workspace.
Credit
We would like to increase particular thanks for the entire contributions to this launch, together with Abhijit Chakankar, Lin Zhou, and Shixiong Zhu.
Assets
[ad_2]