
[ad_1]
That is the fifth put up in a sequence by Rockset’s CTO and Co-founder Dhruba Borthakur on Designing the Subsequent Technology of Knowledge Techniques for Actual-Time Analytics. We’ll be publishing extra posts within the sequence within the close to future, so subscribe to our weblog so you do not miss them!
Posts printed to date within the sequence:
- Why Mutability Is Important for Actual-Time Knowledge Analytics
- Dealing with Out-of-Order Knowledge in Actual-Time Analytics Purposes
- Dealing with Bursty Site visitors in Actual-Time Analytics Purposes
- SQL and Advanced Queries Are Wanted for Actual-Time Analytics
- Why Actual-Time Analytics Requires Each the Flexibility of NoSQL and Strict Schemas of SQL Techniques
The toughest substance on earth, diamonds, have surprisingly restricted makes use of: noticed blades, drilling bits, wedding ceremony rings and different industrial purposes.
Against this, one of many softer metals in nature, iron, may be reworked for an infinite listing of purposes: the sharpest blades, the tallest skyscrapers, the heaviest ships, and shortly, if Elon Musk is true, the most cost-effective EV automotive batteries.
In different phrases, iron’s unimaginable usefulness is as a result of it’s each inflexible and versatile.
Equally, databases are solely helpful for right now’s real-time analytics if they are often each strict and versatile.
Conventional databases, with their wholly-inflexible buildings, are brittle. So are schemaless NoSQL databases, which capably ingest firehoses of knowledge however are poor at extracting advanced insights from that information.
Buyer personalization, autonomic stock administration, operational intelligence and different real-time use circumstances require databases that stricly implement schemas and possess the flexibility to mechanically redefine these schemas based mostly on the information itself. This satisfies the three key necessities of contemporary analytics:
- Help each scale and pace for ingesting information
- Help versatile schemas that may immediately adapt to the variety of streaming information
- Help quick, advanced SQL queries that require a strict construction or schema
Yesterday’s Schemas: Onerous however Fragile
The basic schema is the relational database desk: rows of entities, e.g. folks, and columns of various attributes (age or gender) of these entities. Sometimes saved in SQL statements, the schema additionally defines all of the tables within the database and their relationship to one another.
Historically, schemas are strictly enforced. Incoming information that doesn’t match the predefined attributes or information sorts is mechanically rejected by the database, with a null worth saved as an alternative or the whole document skipped fully. Altering schemas was tough and barely completed. Firms fastidiously engineered their ETL information pipelines to align with their schemas (not vice-versa).
There have been good causes again within the day for pre-creating and strictly implementing schemas. SQL queries have been simpler to write down. In addition they ran loads sooner. Most significantly, inflexible schemas prevented question errors created by unhealthy or mismatched information.
Nonetheless, strict, unchanging schemas have large disadvantages right now. First, there are lots of extra sources and kinds of information than there have been within the 90s. Lots of them can’t simply match into the identical schema construction. Most notable are real-time occasion streams. Streaming and time-series information often arrives in semi-structured codecs that change continuously. As these codecs change, so should the schemas.
Second, as enterprise situations change, corporations regularly want to investigate new information sources, run various kinds of analytics – or just replace their information sorts or labels.
Right here’s an instance. Again once I was on the information infrastructure group at Fb, we have been concerned in an formidable initiative known as Challenge Nectar. Fb’s person base was exploding. Nectar was an try to log each person motion with an ordinary set of attributes. Standardizing this schema worldwide would allow us to investigate developments and spot anomalies on a world degree. After a lot inside debate, our group agreed to retailer each person occasion in Hadoop utilizing a timestamp in a column named time_spent that had a decision of a second.
After debuting Challenge Nectar, we introduced it to a brand new set of utility builders. The primary query they requested: “Can you alter the column time-spent from seconds to milliseconds?” In different phrases, they casually requested us to rebuild a basic facet of Nectar’s schema post-launch!
ETL pipelines can make all of your information sources match underneath the identical proverbial roof (that’s what the T, which stands for information transformation, is all about). Nonetheless, ETL pipelines are time-consuming and costly to arrange, function, and manually replace as your information sources and kinds evolve.
Makes an attempt at Flexibility
Strict, unchanging schemas destroy agility, which all corporations want right now. Some database makers responded to this drawback by making it simpler for customers to manually modify their schemas. There have been heavy tradeoffs, although.
Altering schemas utilizing the SQL ALTER-TABLE command takes a number of time and processing energy, leaving your database offline for an prolonged time. And as soon as the schema is up to date, there’s a excessive danger of inadvertently corrupting your information and crippling your information pipeline.
Take PostgreSQL, the favored transactional database that many corporations have additionally used for easy analytics. To correctly ingest right now’s fast-changing occasion streams, PostgreSQL should change its schema via a handbook ALTER-TABLE command in SQL. This locks the database desk and freezes all queries and transactions for so long as ALTER-TABLE takes to complete. In keeping with many commentators, ALTER-TABLE takes a very long time, regardless of the measurement of your PostgreSQL desk. It additionally requires a number of CPU, and creates the chance of knowledge errors and damaged downstream purposes.
The identical issues face the NewSQL database, CockroachDB. CockroachDB guarantees on-line schema adjustments with zero downtime. Nonetheless, Cockroach warns in opposition to doing a couple of schema change at a time. It additionally strongly cautions in opposition to altering schemas throughout a transaction. And identical to PostgreSQL, all schema adjustments in CockroachDB should be carried out manually by the person. So CockroachDB’s schemas are far much less versatile than they first seem. And the identical danger of knowledge errors and information downtime additionally exists.
NoSQL Involves the Rescue … Not
Different makers launched NoSQL databases that significantly relaxed schemas or deserted them altogether.
This radical design selection made NoSQL databases — doc databases, key-value shops, column-oriented databases and graph databases — nice at storing large quantities of knowledge of various varieties collectively, whether or not it’s structured, semi-structured or polymorphic.
Knowledge lakes constructed on NoSQL databases reminiscent of Hadoop are the very best instance of scaled-out information repositories of blended sorts. NoSQL databases are additionally quick at retrieving massive quantities of knowledge and operating easy queries.
Nonetheless, there are actual disadvantages to light-weight/no-weight schema databases.
Whereas lookups and easy queries may be quick and simple, queries which are advanced. nested and should return exact solutions are likely to run slowly and be tough to create. That’s because of the lack of SQL help, and their tendency to poorly help indexes and different question optimizations. Advanced queries are much more more likely to day out with out returning outcomes because of NoSQL’s overly-relaxed information consistency mannequin. Fixing and rerunning the queries is a time-wasting problem. And on the subject of the cloud and builders, meaning wasted cash.
Take the Hive analytics database that’s a part of the Hadoop stack. Hive does help versatile schemas, however crudely. When it encounters semi-structured information that doesn’t match neatly into its current tables and databases, it merely shops the information as a JSON-like blob. This retains the information intact. Nonetheless, at question time, the blobs should be deserialized first, a gradual and inefficient course of.
Or take Amazon DynamoDB, which makes use of a schemaless key-value retailer. DynamoDB is ultra-fast at studying particular data. Multi-record queries are usually a lot slower, although constructing secondary indexes may help. The larger concern is that DynamoDB doesn’t help any JOINs or another advanced queries.
The Proper Technique to Strict and Versatile Schemas
There’s a successful database formulation, nevertheless, that blends the versatile scalability of NoSQL with the accuracy and reliability of SQL, whereas including a splash of the low-ops simplicity of cloud-native infrastructure.
Rockset is a real-time analytics platform constructed on prime of the RocksDB key-value retailer. Like different NoSQL databases, Rockset is extremely scalable, versatile and quick at writing information. However like SQL relational databases, Rockset has some great benefits of strict schemas: sturdy (however dynamic) information sorts and excessive information consistency, which, together with our computerized and environment friendly Converged Indexing™, mix to make sure your advanced SQL queries are quick.
Rockset mechanically generates schemas by inspecting information for fields and information sorts as it’s saved. And Rockset can deal with any kind of knowledge thrown at it, together with:
- JSON information with deeply-nested arrays and objects, in addition to blended information sorts and sparse fields
- Actual-time occasion streams that continually add new fields over time
- New information sorts from new information sources
Supporting schemaless ingest together with Converged Indexing permits Rockset to scale back information latency by eradicating the necessity for upstream information transformations.
Rockset has different optimization options to scale back storage prices and speed up queries. For each discipline of each document, Rockset shops the information kind. This maximizes question efficiency and minimizes errors. And we do that effectively via a function known as discipline interning that reduces the required storage by as much as 30 % in comparison with a schemaless JSON-based doc database, for instance.
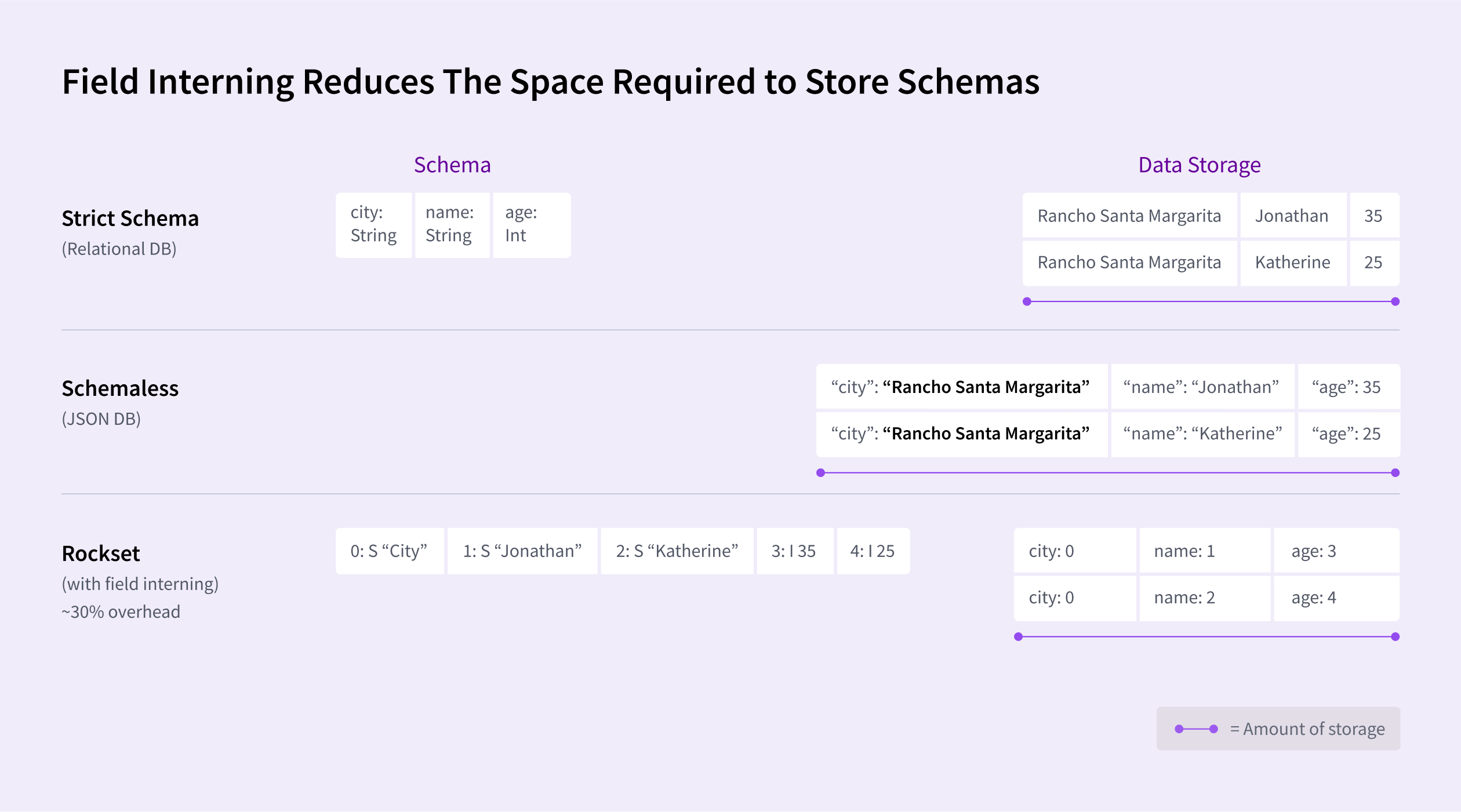
Rockset makes use of one thing known as kind hoisting that reduces processing time for queries. Adjoining objects which have the identical kind can hoist their kind data to use to the whole set of things reasonably than storing with each particular person merchandise within the listing. This allows vectorized CPU directions to course of the whole set of things shortly. This implementation – together with our Converged Index™ – permits Rockset queries to run as quick as databases with inflexible schemas with out incurring extra compute.

Some NoSQL database makers declare solely they will help versatile schemas properly. It isn’t true and is only one of many outdated information myths that trendy choices reminiscent of Rockset are busting.
I invite you to study extra about how Rockset’s structure gives the very best of conventional and trendy — SQL and NoSQL — schemaless information ingestion with computerized schematization. This structure absolutely empowers advanced queries and can fulfill the necessities of the most demanding real-time information purposes with stunning effectivity.
[ad_2]